Access REST APIs with GraphQL: Simplify Your Data Fetching
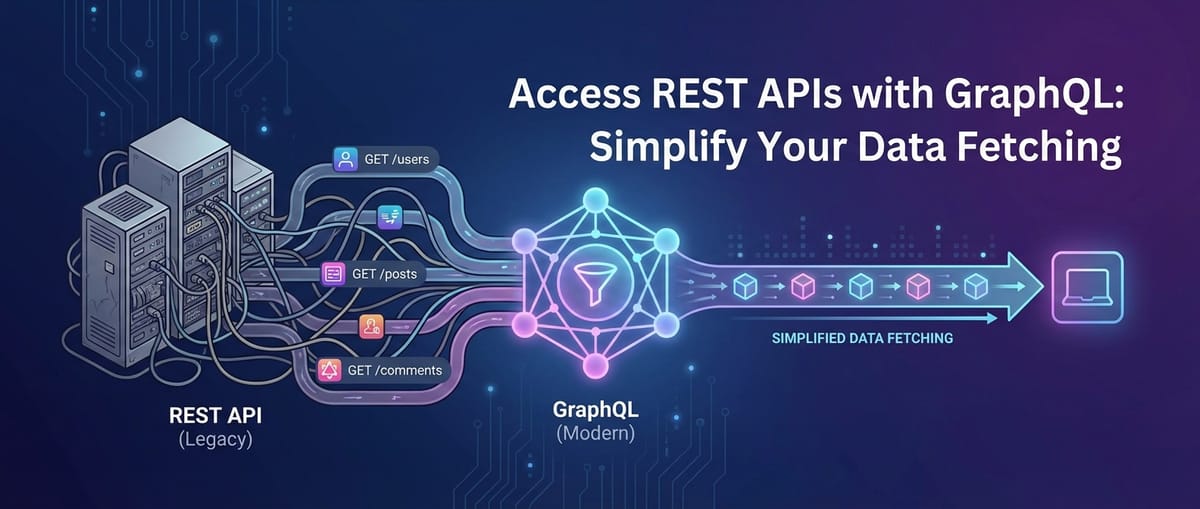


The digital landscape is a ceaseless tide of innovation, constantly reshaping how applications are built and how data is consumed. In this ever-evolving ecosystem, Application Programming Interfaces (APIs) stand as the foundational bedrock, enabling disparate systems to communicate and exchange information. For decades, REST (Representational State Transfer) has reigned supreme as the architectural style of choice for building web services, celebrated for its simplicity, statelessness, and widespread adoption. Yet, as the demands of modern applications grow — particularly with the proliferation of complex single-page applications, mobile apps, and microservices architectures — the traditional RESTful approach, while robust, often encounters limitations when it comes to efficient data fetching. Developers frequently grapple with challenges like over-fetching unnecessary data, under-fetching requiring multiple round trips, and the intricate dance of combining data from various endpoints.
This article delves into a powerful paradigm shift in data fetching: GraphQL. Far from being a replacement for REST, GraphQL emerges as a sophisticated query language for your API and a runtime for fulfilling those queries, offering a declarative and highly efficient alternative to consuming data. More importantly, it provides an elegant solution for modernizing data access patterns even when your backend primarily consists of existing RESTful APIs. We will explore how GraphQL can act as a strategic façade or an API gateway layer, sitting atop your existing REST infrastructure, to empower clients with precise data requests and significantly simplify the data fetching process. Our journey will cover the inherent challenges of REST, the core principles and benefits of GraphQL, practical strategies for integrating GraphQL with existing REST APIs, and best practices to ensure a seamless and performant transition. Ultimately, we aim to illustrate how this hybrid approach can provide the best of both worlds: leveraging your investment in robust REST services while unlocking the flexibility and efficiency that GraphQL offers for modern client-side development.
The Landscape of API Design: REST's Dominance and its Challenges
To fully appreciate the value proposition of GraphQL, it's essential to first understand the entrenched position of REST and the specific friction points it introduces in contemporary application development. REST’s principles were first articulated by Roy Fielding in his 2000 doctoral dissertation, and since then, it has become the de facto standard for building web APIs. Its ubiquity is a testament to its design philosophy, which aligns closely with the architecture of the World Wide Web itself.
Deep Dive into REST: The Cornerstone of Web APIs
REST operates on a set of fundamental principles that promote scalability, reliability, and maintainability. These include:
- Client-Server Architecture: A clear separation between the client and the server, allowing them to evolve independently. The client is responsible for the user interface and user experience, while the server handles data storage and processing. This separation improves portability and scalability.
- Statelessness: Each request from the client to the server must contain all the information necessary to understand the request. The server should not store any client context between requests. This design makes the system more reliable (easier to recover from failures) and scalable (servers don't need to manage session state for individual clients, allowing them to handle more concurrent requests).
- Cacheability: Responses from the server can be explicitly or implicitly defined as cacheable or non-cacheable. This allows clients and intermediaries to reuse previously fetched data, which improves performance and scalability by reducing the number of requests to the server.
- Uniform Interface: This is the most critical constraint. It simplifies the overall system architecture by ensuring that there is a single, consistent way to interact with resources. This principle is further broken down into four sub-constraints:
- Identification of Resources: Resources are identified by URIs (Uniform Resource Identifiers).
- Manipulation of Resources Through Representations: Clients interact with resources by exchanging representations (e.g., JSON, XML) of those resources.
- Self-Descriptive Messages: Each message contains enough information to describe how to process it. This typically involves using standard HTTP methods (GET, POST, PUT, DELETE) and media types.
- Hypermedia as the Engine of Application State (HATEOAS): Resources should contain links to related resources, guiding the client through the application's state transitions. While often touted as a core REST principle, HATEOAS is arguably the least adopted and most debated aspect in practical REST API implementations.
- Layered System: A client cannot ordinarily tell whether it is connected directly to the end server or to an intermediary along the way. This allows for intermediate servers (like proxies, load balancers, or API gateways) to be introduced to provide services like load balancing, caching, or security, without affecting the client or the end server.
- Code on Demand (Optional): Servers can temporarily extend or customize the functionality of a client by transferring executable code (e.g., JavaScript applets). This constraint is optional and less commonly used in typical REST API scenarios today.
REST's success stems from its alignment with HTTP, making it intuitive for web developers. It leverages existing web infrastructure, tools, and protocols, which significantly lowered the barrier to entry for building distributed systems. Resources are clearly delineated by URLs, and standard HTTP verbs map directly to CRUD (Create, Read, Update, Delete) operations, making the API predictable and discoverable.
Challenges of REST for Modern Frontend Needs
Despite its strengths and pervasive adoption, REST faces significant challenges when confronted with the dynamic and data-intensive requirements of modern client applications. These challenges often lead to inefficiencies, increased development complexity, and a suboptimal user experience.
Over-fetching
One of the most common issues with REST APIs is over-fetching. When a client requests data from a REST endpoint, the server typically returns a fixed, predefined payload for that resource. For instance, an endpoint like /users/{id} might return all attributes of a user: ID, name, email, address, phone number, creation date, last login date, and a list of associated roles. However, a specific client UI component might only need the user's name and email for display. The client still receives the entire dataset, consuming unnecessary bandwidth and processing cycles to parse and discard the unneeded information. This problem is particularly acute on mobile devices where bandwidth is often limited and costly, and processing power is at a premium. Each redundant byte transmitted contributes to slower loading times and higher data consumption for the end-user. The server also expends resources fetching and serializing data that will ultimately be discarded by the client. This seemingly minor inefficiency can aggregate into a substantial performance bottleneck in high-traffic applications.
Under-fetching and Multiple Requests (N+1 Problem)
Conversely, modern applications often require deeply nested or related data that is not available from a single REST endpoint. Consider a scenario where a client needs to display a list of users, along with their orders, and the items within each order. A typical REST approach would necessitate multiple requests:
GET /usersto fetch a list of users.- For each user,
GET /users/{id}/ordersto fetch their orders. - For each order,
GET /orders/{id}/itemsto fetch the items.
This sequence of requests, often referred to as the N+1 problem (1 request for the parent resource, N requests for each child resource), leads to a "chatty" API. It significantly increases the number of HTTP round trips between the client and the server, introducing latency and delaying the rendering of the UI. This is a major impediment to responsiveness and can severely degrade the user experience, especially over high-latency networks. Furthermore, the client-side code becomes more complex, burdened with orchestrating these sequential requests, handling potential failures at each step, and then meticulously stitching together the disparate data fragments into a coherent structure for display. This also puts a greater load on the API gateway and backend infrastructure due to the sheer volume of individual requests.
Version Control Challenges
As APIs evolve, new features are added, existing data structures change, or business logic is refined. Managing these changes in a RESTful environment often necessitates API versioning (e.g., /v1/users, /v2/users). While versioning helps prevent breaking changes for existing clients, it introduces significant overhead. Backend teams must maintain and support multiple versions of the same API endpoint, leading to code duplication, increased maintenance burden, and prolonged support periods for older versions. Clients, in turn, need to be updated to consume newer versions, which can be a slow and arduous process, particularly for mobile applications with slower adoption rates for updates. Deciding when to deprecate an old version and forcing clients to migrate is a constant operational challenge.
Client-Side Complexity in Data Aggregation
Due to over-fetching and under-fetching, frontend developers spend a considerable amount of time writing glue code. This code is responsible for filtering out unwanted data from oversized REST responses and, more commonly, for making multiple requests and then combining the data from various endpoints into the shape required by the UI. This data aggregation logic can become quite intricate, leading to brittle client-side code that is difficult to maintain and test. Any change in a backend API endpoint's structure or the introduction of a new dependency often requires modifications across multiple client-side components. This tight coupling between frontend UI components and specific REST endpoints hinders independent development and innovation.
Backend Developer Burden
From the backend perspective, REST's fixed payloads often mean that developers are constantly asked to create new, specialized endpoints to satisfy specific client data requirements. If one client needs user_name and email, and another needs user_name, email, and profile_picture_url, the backend might end up with /users/basic, /users/profile, and so on. This proliferation of endpoints designed for niche client needs bloats the API surface, making it harder to manage, document, and test. It diverts backend development resources from building core business logic to simply tailoring data representations for individual client use cases, leading to slower feature delivery and increased technical debt.
In summary, while REST remains an indispensable API architecture, its rigid approach to resource representation often clashes with the dynamic and granular data needs of modern applications. These challenges highlight a growing demand for a more flexible and efficient data fetching mechanism, paving the way for solutions like GraphQL to complement or even transform how we interact with our backend APIs. The role of an API gateway also becomes crucial here, not just for security and traffic management, but also for potentially abstracting and optimizing these underlying REST interactions, foreshadowing the GraphQL façade approach.
Introducing GraphQL: A Paradigm Shift in Data Fetching
Having explored the limitations of traditional RESTful APIs in the context of modern application development, we now turn our attention to GraphQL, a technology that offers a compelling alternative for data fetching. GraphQL is not merely a different way to structure endpoints; it represents a fundamental shift in how clients request and receive data, designed to address many of the inefficiencies inherent in REST.
What is GraphQL?
At its core, GraphQL is a query language for your API and a server-side runtime for executing queries by using a type system you define for your data. It was developed internally by Facebook in 2012 to power their mobile applications and was open-sourced in 2015. Unlike REST, which is an architectural style, GraphQL is a specification that describes a language for clients to ask for exactly what data they need and nothing more.
Key characteristics that define GraphQL include:
- Not a Database or a Specific Backend Technology: GraphQL is entirely agnostic to the underlying data storage or backend implementation. It doesn't care if your data comes from a relational database, a NoSQL store, microservices, or even existing REST APIs. It simply acts as an intermediary, defining how clients can request data and how the server should fulfill those requests.
- A Query Language for Your API: The most defining feature of GraphQL is its declarative nature. Clients send a single query string to the server, specifying precisely the data fields they require, including nested relationships. The server then responds with a JSON object that exactly mirrors the structure of the query. This contrasts sharply with REST, where the server dictates the shape of the data returned by an endpoint.
- A Runtime for Fulfilling Queries with Your Existing Data: The GraphQL server interprets the incoming query and, based on a predefined schema, executes "resolver" functions that fetch the necessary data from various backend sources. It then assembles the data into the requested shape before sending it back to the client.
Core Principles of GraphQL
GraphQL's design is underpinned by several core principles that collectively contribute to its efficiency and flexibility:
Declarative Data Fetching
This is the cornerstone of GraphQL. Clients declare their data requirements in the query itself. Instead of hitting multiple endpoints or receiving an oversized payload, a client can ask for specific fields from specific resources, including deeply nested relationships, all within a single query. For example, a client might query for a user's name and email, along with the titles of their last three orders, and only the product names within those orders. The GraphQL server, guided by its schema, will fetch precisely this data and return it in a single, perfectly shaped JSON response. This eliminates both over-fetching and under-fetching.
Single Endpoint
A fundamental departure from REST is GraphQL's use of a single endpoint, typically /graphql, to handle all data requests. Unlike REST, where different resources are exposed via distinct URLs (e.g., /users, /products, /orders), GraphQL channels all queries and mutations through this one location. The "action" and the "resource" are determined by the query string sent in the request body, not by the URL path or HTTP method. This simplifies client-side API interaction and streamlines API gateway configurations, as all traffic for data fetching flows through a single point.
Strongly Typed Schema
Every GraphQL API is defined by a schema, written in GraphQL's Schema Definition Language (SDL). This schema is a contract between the client and the server, describing all the data types available, the relationships between them, and the possible operations (queries, mutations, subscriptions) that clients can perform. For example, you might define a User type with fields id, name, email, and orders, where orders is a list of Order types. This strong typing provides several benefits:
- Validation: Queries are validated against the schema before execution, catching errors early.
- Introspection: Clients can query the schema itself to understand the available types and fields. This powers powerful developer tools like GraphiQL, which provides autocomplete, documentation, and error checking directly in the browser.
- Code Generation: The schema can be used to automatically generate client-side types and API client code, improving developer productivity and reducing errors.
- Clarity and Documentation: The schema serves as a comprehensive, living documentation of your API, always reflecting the current state of the data graph.
Real-time Capabilities (Subscriptions)
Beyond queries (for fetching data) and mutations (for modifying data), GraphQL also supports subscriptions. Subscriptions allow clients to receive real-time updates from the server when specific data changes. This is typically implemented over WebSockets, enabling scenarios like live chat, real-time dashboards, or notifications, without the need for traditional polling mechanisms. While not directly related to accessing REST APIs, it highlights GraphQL's comprehensive approach to data interaction.
How GraphQL Addresses REST's Challenges
By design, GraphQL directly tackles the shortcomings identified with REST:
- Eliminates Over-fetching and Under-fetching: Clients explicitly ask for what they need, solving both problems. They get exactly the data they request, in the exact shape, and nothing more. This optimizes network usage and client-side processing.
- Reduces Multiple Requests to a Single Round Trip: With GraphQL, even complex, deeply nested data requirements can be satisfied with a single query to the
/graphqlendpoint. This drastically reduces the number of HTTP requests, minimizing latency and improving application responsiveness, especially for mobile clients or over high-latency networks. - Simplifies Versioning: Instead of creating new
/v2endpoints, GraphQL schemas can evolve incrementally. New fields can be added, and old fields can be marked as deprecated without breaking existing clients. Clients simply stop asking for deprecated fields at their leisure. This "schema evolution" approach simplifies API maintenance and deployment. - Empowers Frontend Developers: Frontend teams gain significant autonomy. They can adjust their data requirements without needing backend changes or waiting for new endpoints to be exposed. This speeds up iteration cycles and allows frontend developers to focus on UI/UX rather than intricate data orchestration.
- Backend Flexibility: Backend developers are freed from the constant burden of creating tailored endpoints for every client need. They can focus on building a robust data graph and implementing efficient resolvers, knowing that the GraphQL layer will handle the specific data shaping required by clients.
In essence, GraphQL shifts the power of data fetching from the server to the client, providing a flexible and efficient mechanism to retrieve data precisely as needed. This client-driven approach makes it particularly attractive for modern applications that demand highly responsive and data-efficient interactions, setting the stage for integrating it with existing REST services.
Bridging the Gap: Integrating GraphQL with Existing REST APIs
The concept of replacing an entire REST API infrastructure with GraphQL can be daunting, if not impossible, for many organizations. Most companies have significant investments in existing REST services, often powering multiple applications and maintained by diverse teams. A complete rewrite is rarely a pragmatic first step. This is where the true power of GraphQL shines as a complementary technology: it can be implemented as a layer, a façade, or an API gateway sitting on top of your existing REST APIs, allowing you to leverage your current infrastructure while providing clients with the benefits of GraphQL.
The "Why": Leveraging Existing Investment
The primary motivation for integrating GraphQL with existing REST APIs is pragmatic modernization. You want to offer a modern, efficient data fetching experience to your clients (especially new client applications) without undergoing a costly and risky "rip and replace" operation for your backend. This approach allows organizations to:
- Gradually Adopt GraphQL: Introduce GraphQL incrementally, starting with new features or specific client applications, without disrupting existing services.
- Consolidate Diverse Data Sources: Bring together data from various REST APIs (and potentially other sources like databases, microservices, or even third-party APIs) under a single, unified GraphQL schema. This creates a "single pane of glass" for data access.
- Improve Client Experience Immediately: Deliver immediate benefits to frontend developers and end-users by reducing over-fetching, under-fetching, and the number of network requests.
- Extend the Lifespan of Legacy Systems: Give new life to older, possibly less flexible, REST APIs by wrapping them in a modern GraphQL interface.
The GraphQL layer acts as an intelligent proxy, translating client GraphQL queries into the appropriate calls to your backend REST APIs. It becomes the new data access layer for clients, abstracting away the complexities and inefficiencies of the underlying REST structure.
The Concept of a GraphQL Layer/Façade
Imagine a GraphQL server not as a new backend altogether, but as a smart intermediary. This intermediary functions much like an API gateway, specifically designed for data access. When a client sends a GraphQL query, this server intercepts it. Instead of fetching data directly from a database, it consults its schema to understand what data is requested and then, using resolver functions, makes one or more calls to your existing REST API endpoints. It then takes the responses from these REST APIs, transforms them if necessary, stitches them together, and shapes them precisely according to the original GraphQL query before sending a single, consolidated response back to the client.
This architectural pattern is often referred to as a "GraphQL façade" or a "GraphQL API gateway." It effectively creates a "data graph" over your disparate data sources, making them appear as a single, coherent API to the client.
Key Components of a GraphQL Server for REST Integration
Building this GraphQL façade involves setting up a GraphQL server and defining how it interacts with your REST APIs. The primary components are:
Schema Definition Language (SDL)
The first step is to define your GraphQL schema using SDL. This schema will represent the unified data graph that clients will interact with. You'll map the concepts and resources exposed by your REST APIs into GraphQL types, fields, and relationships.
For example, if you have a REST endpoint /api/v1/users that returns user information and /api/v1/posts that returns posts, you might define your GraphQL types as:
type User {
id: ID!
name: String!
email: String
posts: [Post!]! # A user can have multiple posts
}
type Post {
id: ID!
title: String!
content: String
author: User! # A post has one author
}
type Query {
user(id: ID!): User
users: [User!]!
post(id: ID!): Post
posts: [Post!]!
}
Notice how posts on User and author on Post define relationships that might require multiple REST calls to resolve. The schema dictates the shape of the data that clients can request, completely abstracting the underlying REST endpoints.
Resolvers
Resolvers are the workhorses of a GraphQL server. For every field in your schema that can be queried, there must be a corresponding resolver function. When a client queries a specific field, the GraphQL execution engine invokes its associated resolver to fetch the data for that field.
In the context of integrating with REST APIs, your resolvers will contain the logic to make HTTP requests to your REST endpoints.
Continuing the example:
- The
user(id: ID!)query resolver would make aGETrequest to/api/v1/users/{id}. - The
usersquery resolver would make aGETrequest to/api/v1/users. - The
postsfield resolver within theUsertype would be more complex. When a client queries foruser { id name posts { title } }, theuserresolver first fetches the user data. Then, for each user, thepostsresolver needs to fetch the posts associated with that user, perhaps by calling/api/v1/users/{id}/postsor/api/v1/posts?userId={id}. This is where the N+1 problem can re-emerge if not handled carefully, which we will discuss later.
Resolvers are the critical bridge that translates the declarative GraphQL query into imperative calls to your existing REST infrastructure.
Data Sources
To manage the interactions with external REST APIs more cleanly and efficiently, it's common to abstract the REST calls into "data sources" or "connectors." A data source is essentially a class or module that encapsulates the logic for making HTTP requests to a specific REST API, handling authentication, error parsing, and potentially caching. This separation of concerns keeps your resolvers clean and focused purely on data fetching logic, rather than low-level HTTP details.
For instance, you might have a UsersAPIDataSource and a PostsAPIDataSource, each knowing how to communicate with their respective REST APIs. Resolvers would then use methods like usersAPIDataSource.getUserById(id) or postsAPIDataSource.getPostsByUserId(userId).
Step-by-Step Integration Process
Implementing a GraphQL façade over your existing REST APIs typically follows a structured process:
- Identify Core Resources and Relationships: Begin by thoroughly understanding your existing REST APIs. Document all available endpoints, the data they return, and how different resources are related (e.g., how users relate to orders, products to categories). This forms the blueprint for your GraphQL schema.
- Design Your GraphQL Schema: Translate your identified resources and their relationships into a GraphQL schema using SDL. Define
Querytypes for fetching data andMutationtypes for modifying data. Pay special attention to how nested relationships are defined, as this is where GraphQL truly shines. Focus on the data model that makes sense for your clients, not necessarily a direct 1:1 mapping of your REST endpoints. - Implement Resolvers: For each field in your schema that needs to fetch data, write a resolver function. These resolvers will contain the logic to call your underlying REST APIs. Utilize data sources to abstract the HTTP request logic. This step requires careful consideration of how to efficiently transform GraphQL query parameters into REST request parameters and how to map REST responses back into the GraphQL type system. This is also where you would implement solutions for potential N+1 problems.
- Set up the GraphQL Server: Choose a GraphQL server framework (e.g., Apollo Server for Node.js, Graphene for Python, HotChocolate for .NET) and configure it to use your defined schema and resolvers. This server will expose the single
/graphqlendpoint that your clients will interact with. Deploy this GraphQL server, potentially as a new microservice or as part of an existing API gateway infrastructure. Ensure it is accessible and robust enough to handle expected traffic.
By following these steps, you can effectively construct a powerful GraphQL API gateway that simplifies data access for your clients, all while leveraging your valuable investment in existing REST APIs. This hybrid approach offers a pragmatic path to modernization and improved developer experience.
APIPark is a high-performance AI gateway that allows you to securely access the most comprehensive LLM APIs globally on the APIPark platform, including OpenAI, Anthropic, Mistral, Llama2, Google Gemini, and more.Try APIPark now! 👇👇👇
Practical Techniques and Best Practices for REST-to-GraphQL Integration
Successfully building a GraphQL façade over existing REST APIs requires more than just defining a schema and writing resolvers. It involves careful consideration of several practical aspects, including choosing the right tools, managing authentication, handling errors, and optimizing performance. These techniques ensure that your GraphQL layer is robust, efficient, and truly simplifies data fetching.
Choosing a GraphQL Server Framework
The foundation of your GraphQL façade is the server framework. The choice of framework often depends on your existing technology stack and team's expertise. Popular options include:
- Node.js:
- Apollo Server: A robust and widely adopted server-side library that provides a comprehensive toolkit for building GraphQL APIs, including caching, tracing, and integration with various HTTP frameworks. It’s highly flexible and has a large community.
- Express-GraphQL: A simpler integration for Express.js, allowing you to quickly set up a basic GraphQL endpoint. Suitable for smaller projects or learning.
- GraphQL-Yoga: A full-featured GraphQL server that builds on Apollo Server and provides a batteries-included experience with subscriptions, file uploads, and more.
- Python:
- Graphene: A powerful and flexible library for building GraphQL APIs in Python, with integrations for Django, Flask, and other frameworks.
- Java/Kotlin:
- GraphQL Java: The core GraphQL implementation for Java, providing low-level building blocks.
- Spring for GraphQL: Built on GraphQL Java, offering seamless integration with the Spring ecosystem.
- Go:
- gqlgen: A schema-first Go library that generates type-safe Go code from your GraphQL schema.
- .NET:
- HotChocolate: A modern GraphQL server for .NET, known for its performance, extensibility, and rich feature set including real-time capabilities and schema stitching.
The chosen framework will dictate how you define your schema, implement resolvers, and handle HTTP requests, so selecting one that aligns with your team's skills is crucial.
Handling Authentication and Authorization
Security is paramount for any API, and a GraphQL façade adds another layer to consider. You need to ensure that client requests are authenticated and authorized before hitting your GraphQL layer, and that your GraphQL layer correctly passes or performs authentication for the underlying REST APIs.
- Client-to-GraphQL Authentication: Clients will typically send authentication tokens (e.g., JWTs, OAuth tokens) in the
Authorizationheader to your GraphQL server. Your GraphQL server should validate these tokens. If using an API gateway in front of your GraphQL server, the gateway might handle this initial authentication and pass user context to the GraphQL layer. - GraphQL-to-REST Authorization:
- Pass-through: The simplest approach is for the GraphQL server to simply forward the client's authentication token (if applicable and appropriate) to the underlying REST APIs. This works if your REST APIs understand the same token format.
- GraphQL Layer-Specific Credentials: In some cases, the GraphQL layer might use its own set of credentials (e.g., an API key or service account token) to authenticate with the backend REST APIs. This is common when the GraphQL server acts more like a trusted internal service.
- Role-Based Access Control (RBAC): Your GraphQL resolvers can implement authorization logic based on the authenticated user's roles or permissions. Before invoking a REST API, the resolver can check if the user is authorized to access the requested data. For example, a user might be able to query their own
postsbut not another user'spostsdirectly. - Centralized API Gateway Role: This is where a dedicated API gateway can be extremely powerful. An API gateway can centralize authentication, authorization, and rate limiting policies for both the GraphQL endpoint itself and the underlying REST APIs. This ensures a consistent security posture across your entire API landscape and offloads these concerns from individual services.
Error Handling and Data Transformation
REST APIs typically communicate errors via HTTP status codes (4xx for client errors, 5xx for server errors) and a JSON error body. GraphQL handles errors differently: successful requests (even if they contain errors for specific fields) will still return a 200 OK status code, with an errors array in the JSON response body detailing any issues.
- Mapping REST Errors to GraphQL Errors: Your resolvers need to catch errors thrown by the underlying REST APIs and transform them into a GraphQL-compatible error format. This often means adding an entry to the
errorsarray in the GraphQL response, potentially including specific error codes or messages from the REST API. - Data Transformation: REST API responses might not perfectly match the structure defined in your GraphQL schema. Resolvers are responsible for transforming the data received from REST into the exact shape expected by the GraphQL type system. This could involve renaming fields, combining fields, or even performing simple data type conversions.
- Example: A REST API might return
user_nameanduser_email, while your GraphQL schema definesnameandemail. The resolver would mapuser_nametonameanduser_emailtoemail.
- Example: A REST API might return
Batching and Caching: Solving the N+1 Problem
The N+1 problem, where fetching a list of parent resources followed by individual requests for each child resource, can resurface when GraphQL resolvers call REST APIs. This leads to a performance bottleneck.
- Dataloader Pattern: This is the canonical solution for the N+1 problem in GraphQL. Dataloader (or similar implementations in other languages) is a utility that provides two key benefits:
- Batching: It collects individual requests for data over a short period (e.g., during a single tick of the event loop) and dispatches them as a single, batched request to the backend. For instance, if 10 different
Userresolvers simultaneously need to fetchPostdata for their respective users, Dataloader can combine these 10 individualposts?userId={id}requests into a singleposts?userIds={id1},{id2},...{id10}request (assuming your REST API supports batch fetching by multiple IDs). - Caching: It caches the results of requests, so if the same data is requested multiple times within a single query, it's only fetched once from the backend. Implementing Dataloader effectively with your REST data sources is crucial for maintaining high performance.
- Batching: It collects individual requests for data over a short period (e.g., during a single tick of the event loop) and dispatches them as a single, batched request to the backend. For instance, if 10 different
- Caching REST Responses at the GraphQL Layer: Beyond Dataloader, you can implement caching at the GraphQL server level for responses from underlying REST APIs. This could involve in-memory caches, Redis, or Memcached. If a REST endpoint's data is relatively static or changes infrequently, caching its response in the GraphQL layer can significantly reduce load on the backend REST service and speed up query resolution. Cache invalidation strategies are critical here.
Performance Considerations
Optimizing the performance of your GraphQL façade is key to realizing its full benefits.
- Monitoring and Logging: Implement robust monitoring for your GraphQL server and its interactions with downstream REST APIs. Track query response times, error rates, and the latency of individual REST calls. Detailed logging helps identify performance bottlenecks, troubleshoot issues, and understand API usage patterns.
- Rate Limiting: Protect your GraphQL server and the underlying REST APIs from abuse or excessive traffic by implementing rate limiting. This can be done at the GraphQL server level or, more effectively, at an API gateway sitting in front of your GraphQL service.
- Payload Size Optimization: While GraphQL inherently reduces payload size for clients, ensure that your GraphQL server isn't generating unnecessarily large intermediate payloads when communicating with REST APIs. Use efficient JSON parsing and serialization.
- Complexity Analysis: GraphQL queries can be arbitrarily complex, potentially leading to expensive operations. Implement query complexity analysis to prevent malicious or overly resource-intensive queries from overwhelming your server. This involves calculating a "cost" for each query and rejecting queries that exceed a defined threshold.
- APIPark Integration: For organizations that are serious about API governance and performance, especially when managing a hybrid architecture involving GraphQL over REST, tools like APIPark offer a compelling solution. APIPark, as an open-source AI gateway and API management platform, is designed to efficiently manage, integrate, and deploy REST services. When you establish a GraphQL façade, the performance and reliability of the underlying REST APIs become even more critical. APIPark steps in as a robust API gateway that can handle the raw REST traffic that your GraphQL resolvers generate. Its features, such as performance rivaling Nginx (achieving over 20,000 TPS with minimal resources), comprehensive logging of every API call, and powerful data analysis of historical call data, are invaluable. For example, APIPark can provide deep insights into the performance of the REST APIs that your GraphQL layer relies on, helping you identify and resolve bottlenecks before they impact the client experience. It centralizes traffic forwarding, load balancing, and versioning of the underlying REST APIs, ensuring high availability and stability. Furthermore, its ability to manage API lifecycle, enforce access permissions, and provide commercial support makes it an ideal complement to a GraphQL integration strategy, ensuring the efficient operation and monitoring of the entire API ecosystem. By deploying APIPark in conjunction with your GraphQL façade, you can ensure that the underlying REST API interactions are as optimized and secure as possible, bolstering the overall reliability and scalability of your data fetching solution.
Schema Stitching vs. Federation
As your API landscape grows, you might end up with multiple GraphQL services, each perhaps responsible for a different domain or microservice. To present a unified GraphQL API to clients, you can use:
- Schema Stitching: A technique to combine multiple independent GraphQL schemas into a single, cohesive schema. The GraphQL server performs the stitching and delegates queries to the appropriate sub-schemas.
- GraphQL Federation: A more advanced approach, popularized by Apollo, where multiple independent GraphQL services (called "subgraphs") define their own schemas and contribute to a global "supergraph." A central "gateway" then uses metadata to route parts of a client's query to the correct subgraph, performing query planning and execution across services. This is particularly powerful for large, distributed architectures and can work seamlessly even when subgraphs resolve data from underlying REST APIs.
While these are advanced topics, they highlight how GraphQL can scale to complex enterprise environments, effectively acting as a universal API gateway for all data interactions, irrespective of the underlying data source or service implementation.
By carefully applying these practical techniques and best practices, developers can build a highly performant, secure, and maintainable GraphQL façade that truly simplifies data fetching and enhances the developer experience, all while leveraging the substantial investment in existing REST APIs.
Benefits of the GraphQL Façade over REST
Implementing a GraphQL façade over your existing REST APIs is not just a technical exercise; it delivers tangible benefits that span across development teams, infrastructure, and the end-user experience. This hybrid approach allows organizations to modernize their data access patterns without the disruptive overhaul of a complete backend migration.
Improved Developer Experience (DX)
For frontend developers, the shift to GraphQL is often transformative. They gain unprecedented control over the data they receive, asking for exactly what they need and getting it in a predictable, self-documenting format.
- Self-Documenting API: The GraphQL schema acts as live, interactive documentation. Tools like GraphiQL or Apollo Studio provide instant access to the schema, allowing developers to explore available types, fields, and relationships, and even test queries directly. This eliminates the need to consult outdated API documentation.
- Reduced Client-Side Logic: No more glue code for filtering over-fetched data or stitching together responses from multiple REST endpoints. The GraphQL server handles the aggregation and shaping, allowing frontend developers to focus on building UI components.
- Faster Iteration: Frontend teams can modify their data requirements without needing backend changes or new REST endpoints. This autonomy accelerates development cycles and allows for more rapid experimentation and feature deployment.
- Strong Typing and Autocomplete: The strongly typed nature of GraphQL schemas enables powerful tooling. Frontend IDEs can provide autocomplete for queries, catching type-related errors at compile-time rather than runtime, significantly improving development speed and reducing bugs.
Reduced Network Payload
By allowing clients to specify precisely what data they need, GraphQL eliminates the problem of over-fetching.
- Efficient Bandwidth Usage: Clients only receive the requested fields, resulting in smaller data payloads. This is particularly beneficial for mobile applications and users on limited or costly data plans, leading to faster loading times and reduced data consumption.
- Faster Perceived Performance: Less data to transfer means quicker response times, which translates to a more responsive and fluid user experience.
Fewer Round Trips
A single GraphQL query can replace multiple sequential REST requests, even for complex, deeply nested data.
- Minimized Latency: Reducing the number of HTTP requests from the client to the server significantly decreases network latency, especially over high-latency networks. A single round trip is always faster than N round trips.
- Optimized Resource Usage: Fewer requests mean less overhead for connection setup, TCP handshakes, and SSL/TLS negotiations, both on the client and the server (including any API gateway in between).
Simplified Backend Development
While the initial setup of the GraphQL layer requires effort, it can simplify ongoing backend development in the long run.
- Focus on Data Sources: Backend teams can concentrate on building robust, performant data sources (your existing REST APIs) rather than constantly tailoring specific endpoints for every client-side view.
- Clear Separation of Concerns: The GraphQL layer clearly separates the concerns of data fetching and shaping (client-driven) from the concerns of data storage and business logic (backend-driven).
- Reduced API Sprawl: Instead of a multitude of specialized REST endpoints, the GraphQL layer exposes a single, unified view of your data, making the overall API landscape easier to manage and understand.
Better API Evolution
GraphQL offers a more graceful approach to API versioning and evolution compared to traditional REST.
- Non-Breaking Changes: You can add new fields to your GraphQL schema without breaking existing clients. Clients simply won't request the new fields until they are updated.
- Deprecation Mechanism: GraphQL has built-in mechanisms to mark fields as deprecated. This allows you to signal to clients that a field will eventually be removed, giving them ample time to migrate, without needing to maintain separate API versions (e.g.,
/v1,/v2). This significantly reduces the maintenance burden and complexity associated with version management.
Unified Data Graph
Perhaps one of the most powerful long-term benefits is the creation of a unified data graph. The GraphQL layer can aggregate data not just from multiple REST APIs but potentially from databases, other microservices, and third-party APIs, all under a single, coherent schema.
- Holistic Data View: Clients get a single entry point to access all relevant data, regardless of its origin. This simplifies data integration and provides a holistic view of the application's data domain.
- Interoperability: It fosters better interoperability between different backend services by providing a consistent interface for consuming their data. The GraphQL API becomes a universal language for data access within your organization.
In summary, leveraging a GraphQL façade over existing REST APIs is a strategic move that enhances developer productivity, optimizes application performance, and future-proofs your API infrastructure. It allows organizations to gradually adopt modern data fetching capabilities while preserving their investment in established REST services, creating a powerful and flexible API ecosystem.
Potential Challenges and Considerations
While the benefits of adopting a GraphQL façade over existing REST APIs are substantial, it's crucial to acknowledge the potential challenges and considerations involved. No technology is a silver bullet, and understanding these aspects will help in planning and executing a successful integration.
Learning Curve
GraphQL introduces a new paradigm for API interaction, which comes with an initial learning curve for both frontend and backend teams.
- New Query Language: Frontend developers need to learn GraphQL's query syntax, schema definition language, and how to use GraphQL client libraries.
- Schema Design and Resolvers: Backend developers, while potentially familiar with data sources, need to master schema design principles, understand how to write efficient resolvers, and grasp the GraphQL execution model. This is different from simply exposing resources via HTTP endpoints.
- Mindset Shift: Moving from a resource-centric (REST) to a graph-centric (GraphQL) way of thinking about data can require a mental adjustment.
Complexity of Resolvers
Translating complex GraphQL queries into optimal REST calls can be challenging, especially for deeply nested or highly interconnected data.
- N+1 Problem Management: As discussed, ensuring efficient data fetching from REST APIs requires careful implementation of batching and caching mechanisms like Dataloader. Without these, a single GraphQL query could trigger a cascade of inefficient REST calls.
- Data Aggregation and Transformation: Resolvers need to handle the aggregation of data from multiple REST responses and transform them into the precise shape defined by the GraphQL schema. This can become intricate, especially if the underlying REST structures are inconsistent or require complex manipulation.
- Error Mapping: Accurately translating specific REST error codes and messages into meaningful GraphQL errors requires diligent handling within resolvers.
Caching
HTTP caching, while not always straightforward, is a well-understood mechanism for REST APIs, leveraging HTTP headers (e.g., Cache-Control, ETag, Last-Modified). GraphQL's single endpoint and dynamic queries complicate traditional HTTP caching.
- Client-Side Caching: GraphQL client libraries often come with sophisticated client-side caches (e.g., Apollo Client's normalized cache) that manage data based on object IDs. This handles caching for the client effectively but doesn't reduce load on the server.
- Server-Side Caching: Implementing server-side caching for GraphQL queries requires more thought. You can cache resolver results, entire query responses (though less common due to dynamic nature), or leverage a CDN for the GraphQL endpoint (with careful cache-key generation). This is an area where a smart API gateway could potentially offer advanced caching strategies for GraphQL query results, or more practically, cache the responses from the underlying REST APIs.
- Cache Invalidation: Designing robust cache invalidation strategies that account for data mutations and dependencies across different data sources is a non-trivial task.
N+1 Problem if Not Handled Correctly
The N+1 problem is a significant performance pitfall if Dataloader or similar batching/caching techniques are not diligently applied. If each nested field's resolver makes an individual REST call, a single GraphQL query could result in hundreds or thousands of HTTP requests to your backend, completely negating the performance benefits of GraphQL. This requires a proactive and disciplined approach during resolver implementation.
Tooling Maturity
While the GraphQL ecosystem has matured considerably, it's still younger than REST. Some advanced tooling or enterprise-grade features might still be evolving.
- Monitoring and Tracing: While good tools exist, integrating comprehensive monitoring and distributed tracing across your GraphQL layer and its underlying REST APIs requires careful setup.
- GraphQL-specific Security Scans: Traditional API security scanning tools might not fully understand GraphQL's unique attack vectors (e.g., query depth limits, alias abuse), requiring specialized tools or configurations.
Monitoring and Observability
Gaining deep visibility into the performance and behavior of your GraphQL façade and its interactions with downstream REST APIs is critical for operations and troubleshooting.
- Distributed Tracing: Implementing distributed tracing (e.g., OpenTelemetry, Jaeger) is essential to track a single GraphQL query's journey through multiple resolvers and subsequent REST API calls. This helps pinpoint latency issues.
- Detailed Logging: Comprehensive logging of GraphQL query execution, resolver timings, and all outgoing REST API calls is necessary.
- API Gateway Metrics: Utilizing the metrics provided by your API gateway (like APIPark) is crucial here. APIPark's detailed API call logging, which records every aspect of each API call, along with its powerful data analysis capabilities (displaying long-term trends and performance changes), provides invaluable insights. This helps businesses quickly trace and troubleshoot issues, ensuring system stability and data security for both the GraphQL layer and its dependent REST APIs. An API gateway can provide a centralized point for collecting and analyzing traffic patterns, error rates, and latency, offering a macroscopic view of your API health.
Managing Schema Complexity
As your unified data graph grows, the schema can become very large and complex. Managing its evolution, ensuring consistency, and avoiding breaking changes requires careful governance. This might involve adopting schema federation for larger organizations.
By being aware of these challenges and proactively addressing them with appropriate strategies, tooling, and best practices, organizations can successfully integrate GraphQL with their existing REST APIs and unlock its full potential for efficient and flexible data fetching. The investment in robust API gateway and management solutions can significantly mitigate many of these operational complexities.
Conclusion
The journey through the intricate world of API design and data fetching reveals a clear truth: the needs of modern applications are constantly pushing the boundaries of what traditional architectures can efficiently deliver. While REST has undeniably served as the backbone of web APIs for decades, its inherent limitations—particularly in terms of over-fetching, under-fetching, and the challenge of managing multiple requests for complex data structures—have become increasingly apparent. Developers are continually seeking more agile, efficient, and client-centric ways to interact with backend services.
GraphQL emerges not as a destructive force poised to completely replace REST, but rather as a powerful, complementary solution that enhances and modernizes data access. By acting as an intelligent façade or an API gateway layer over existing REST APIs, GraphQL provides a declarative query language that empowers clients to request precisely the data they need, in the exact shape they desire, all within a single round trip. This approach directly addresses the inefficiencies of REST, drastically reducing network payloads, minimizing latency, and significantly improving the developer experience.
The integration of GraphQL with existing REST APIs offers a pragmatic path for organizations to gradually adopt cutting-edge data fetching capabilities without necessitating a costly and disruptive overhaul of their entire backend infrastructure. Through careful schema design, robust resolver implementation (especially with patterns like Dataloader for batching and caching), and diligent attention to authentication, error handling, and performance optimization, the benefits are clear: improved developer productivity, faster application performance, simplified API evolution, and the creation of a unified, self-documenting data graph.
While the adoption of GraphQL does come with its own set of challenges—including a learning curve, the complexity of resolvers, and new considerations for caching and monitoring—these can be effectively managed with the right tools, best practices, and a strategic approach to API governance. Solutions like APIPark, an open-source AI gateway and API management platform, can play a pivotal role in this hybrid architecture. By providing robust traffic management, detailed logging, performance insights, and centralized control over the underlying REST APIs, platforms like APIPark ensure that the essential foundation upon which the GraphQL façade rests remains performant, secure, and highly available.
Ultimately, the future of API interaction is likely to be a hybrid one, where REST continues to excel in its core strengths (simple resource manipulation, easy caching for static assets) and GraphQL takes the lead in complex, client-driven data fetching. By embracing this strategic convergence, organizations can unlock unparalleled flexibility and efficiency, fostering a more agile development environment and delivering superior user experiences in the dynamic digital world.
Frequently Asked Questions (FAQs)
1. What are the main differences between REST and GraphQL for data fetching?
The primary difference lies in how clients request data. With REST, clients interact with multiple fixed endpoints, each returning a predefined data structure (potentially leading to over-fetching or under-fetching). With GraphQL, clients send a single query to a single endpoint, specifying exactly the data fields they need, including nested relationships. This eliminates over-fetching and under-fetching, and reduces the number of network requests. REST is an architectural style leveraging HTTP methods and URLs, while GraphQL is a query language with a type system.
2. Can GraphQL completely replace my existing REST APIs?
While GraphQL can abstract away your REST APIs, it doesn't necessarily replace them. For many organizations, the most practical approach is to implement GraphQL as a façade or an API gateway on top of existing REST APIs. This allows you to leverage your current backend infrastructure and investments while providing clients with the benefits of GraphQL. A complete "rip and replace" of all REST APIs with a GraphQL-native backend is often costly and unnecessary, especially for established systems.
3. What is the "N+1 Problem" in GraphQL, and how is it addressed when integrating with REST?
The N+1 Problem occurs when a GraphQL query, for example, fetching a list of users, then for each user, separately fetching their posts from an underlying REST API. This results in one request for the list of users, and then N additional requests (where N is the number of users) for their posts, leading to poor performance. This is typically addressed using the Dataloader pattern. Dataloader batches multiple individual requests for the same type of data into a single, more efficient request to the backend REST API, significantly reducing the number of round trips and improving performance. It also includes a caching mechanism for results within a single query.
4. How does a GraphQL façade handle authentication and authorization for the underlying REST APIs?
Authentication and authorization for a GraphQL façade involve two layers: 1. Client-to-GraphQL: Clients send their authentication tokens (e.g., JWTs) to the GraphQL server, which validates them. 2. GraphQL-to-REST: The GraphQL server (or its resolvers) can either pass the client's token directly to the underlying REST APIs (if compatible) or use its own service-level credentials to authenticate with the REST APIs. Authorization logic can also be implemented within GraphQL resolvers to check if an authenticated user has permission to access the specific data being requested from the REST API. An API gateway like APIPark can centralize and manage these authentication and authorization policies for both the GraphQL endpoint and the backend REST services.
5. What role does an API Gateway play in a GraphQL over REST architecture?
An API gateway is crucial in a GraphQL over REST architecture. It acts as a single entry point for all client requests, offering centralized management for security, traffic control, and monitoring. For the GraphQL façade itself, an API gateway can provide authentication, rate limiting, caching, and load balancing. More importantly, for the underlying REST APIs that the GraphQL resolvers consume, the API gateway continues to provide its core functions: protecting these services, routing traffic, load balancing, applying security policies, and offering detailed logging and performance analytics. Platforms like APIPark are specifically designed to manage and optimize these REST APIs, ensuring that the entire data fetching ecosystem, from the client's GraphQL query to the final REST call, is robust, performant, and secure.
🚀You can securely and efficiently call the OpenAI API on APIPark in just two steps:
Step 1: Deploy the APIPark AI gateway in 5 minutes.
APIPark is developed based on Golang, offering strong product performance and low development and maintenance costs. You can deploy APIPark with a single command line.
curl -sSO https://download.apipark.com/install/quick-start.sh; bash quick-start.sh

In my experience, you can see the successful deployment interface within 5 to 10 minutes. Then, you can log in to APIPark using your account.

Step 2: Call the OpenAI API.

