eBPF: What Data Can It Extract from Incoming Packets?



In the intricate dance of modern computing, where data flows ceaselessly through networks, understanding and controlling these currents is paramount. For developers, network engineers, and system administrators alike, the ability to peer into the heart of incoming packets offers unprecedented insights into system behavior, security posture, and application performance. This is where eBPF (extended Berkeley Packet Filter) emerges as a transformative technology, revolutionizing how we interact with the Linux kernel and, by extension, how we process and extract data from network traffic. Far from being a niche tool, eBPF is rapidly becoming a cornerstone of advanced networking, observability, and security, especially within complex distributed systems and API gateway architectures.
This extensive exploration delves into the remarkable capabilities of eBPF, dissecting precisely what types of data it can extract from incoming network packets. We will journey through the layers of the network stack, from the foundational data link layer to the intricate application layer, uncovering how eBPF empowers us to not only observe but also react to the minutiae of network communication. We'll specifically highlight its profound relevance to API gateway and API management scenarios, demonstrating how this kernel-level superpower is reshaping the landscape of high-performance and secure network operations.
The Genesis and Power of eBPF: A Kernel Superpower
Before we dive into the specifics of data extraction, it’s crucial to grasp the fundamental nature and architectural elegance of eBPF. Originating from the classic Berkeley Packet Filter (BPF) designed for filtering network packets in userspace, eBPF has evolved into a general-purpose, in-kernel virtual machine. This evolution is not merely incremental; it's a paradigm shift, enabling developers to write and run custom programs securely within the Linux kernel without modifying the kernel's source code or loading vulnerable kernel modules.
The core strength of eBPF lies in its unparalleled ability to attach programs to various hook points throughout the kernel, including those intimately involved in network packet processing. These programs, written in a restricted C-like language and compiled into eBPF bytecode, are then loaded into the kernel. Before execution, a sophisticated in-kernel verifier rigorously checks the program's safety and termination guarantees, ensuring it won't crash the kernel, loop indefinitely, or access unauthorized memory. Once verified, the eBPF bytecode is often Just-In-Time (JIT) compiled into native machine code, providing near-native performance. This unique combination of safety, flexibility, and performance makes eBPF an ideal candidate for high-stakes tasks like network data extraction and manipulation.
Traditional approaches to network analysis often involve cumbersome methods: instrumenting applications, parsing log files, or relying on userspace packet capture tools that incur significant context switching overhead. In contrast, eBPF operates directly at the kernel level, intercepting packets at their earliest arrival or at critical points within the network stack. This proximity to the data source drastically reduces latency and overhead, offering a true "observability superpower" that can be dynamically deployed and updated without system reboots or service interruptions. For a modern gateway handling millions of requests, this efficiency is not just an advantage; it's a necessity.
Navigating the Network Stack with eBPF: Where Data Resides
To understand what data eBPF can extract, we must first revisit the fundamental structure of network communication, often conceptualized through the OSI model or the TCP/IP model. Each layer encapsulates data from the layer above it, adding its own header information relevant to its specific function. eBPF programs, depending on where they are hooked into the kernel's network stack, can gain access to different levels of this encapsulated information.
The journey of an incoming packet into a Linux system is a complex one. It starts at the Network Interface Card (NIC), traverses hardware queues, and then enters the kernel's network driver. From there, it moves through various software queues, potentially interacts with functionalities like netfilter (Linux firewall), and eventually reaches the appropriate socket for a userspace application. eBPF can strategically tap into numerous points along this path:
- XDP (eXpress Data Path): This is the earliest possible hook point in the network stack, typically before the packet is even processed by the kernel's full network stack. XDP programs run directly on the network driver's receive path. This allows for extremely high-performance packet processing, enabling decisions like dropping, redirecting, or modifying packets with minimal overhead. It's a critical point for DDoS mitigation and high-speed load balancing, often found at the edge of a data center or an API gateway.
tc(Traffic Control) Ingress/Egress Hooks: These hooks integrate with the Linux traffic control subsystem, allowing eBPF programs to process packets as they enter (ingress) or leave (egress) a network interface after basic kernel processing but before they are handed to specific applications or sent out.tchooks offer more flexibility than XDP for complex packet manipulation and classification.- Socket Filters: eBPF programs can be attached to sockets, allowing them to filter packets destined for a specific application's socket. This is particularly useful for application-specific firewalling or specialized packet monitoring without affecting other applications.
- Tracepoints and Kprobes/Uprobes: Beyond direct packet processing, eBPF can also attach to kernel tracepoints (pre-defined instrumentation points) or dynamically attach Kprobes (kernel probes) to virtually any kernel function and Uprobes (userspace probes) to functions within userspace applications. While not directly "packet hooks," these are invaluable for understanding how the kernel or applications process packet data, especially for obtaining Layer 7 insights.
By leveraging these diverse hook points, eBPF gains a panoramic view of network traffic, enabling the extraction of a rich tapestry of data.
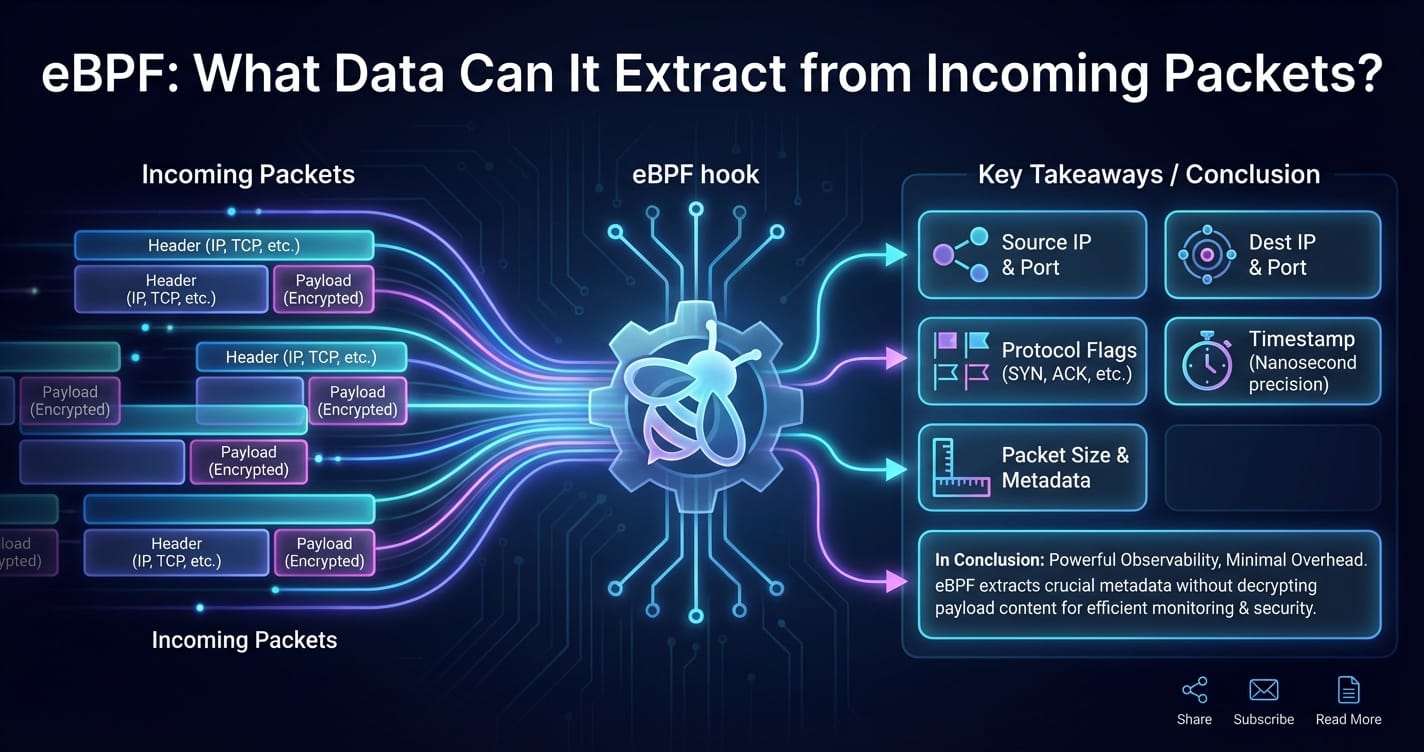
Deconstructing the Packet: What Data Can eBPF Extract?
The true power of eBPF lies in its ability to dissect incoming packets and expose their underlying data elements. We'll explore this layer by layer, detailing the specific information accessible and its implications for networking, security, and the operation of an API gateway.
Layer 2: The Data Link Layer – MAC Addresses and Frame Information
At the very foundation of network communication, the Data Link Layer (Layer 2) handles the physical transmission of data between devices on the same local network segment. When a packet first arrives at a network interface, eBPF programs, especially those attached at the XDP level, can inspect the raw Ethernet frame.
The key pieces of data extractable at Layer 2 include:
- Source MAC Address: The hardware address of the sending device. This 6-byte identifier is crucial for identifying specific network interfaces on a local segment.
- Destination MAC Address: The hardware address of the intended recipient on the local segment. This is used by switches to forward frames to the correct port.
- EtherType: A 2-byte field that specifies the protocol encapsulated in the payload of the Ethernet frame. Common EtherTypes include
0x0800for IPv4,0x86DDfor IPv6, and0x0806for ARP (Address Resolution Protocol). - VLAN Tag (802.1Q): If present, this 4-byte tag indicates that the frame belongs to a specific Virtual Local Area Network. It includes a Tag Protocol Identifier (TPID) and Tag Control Information (TCI), which contains the VLAN ID, priority, and CFI/DEI bits.
How eBPF accesses it: An eBPF program at an XDP hook receives a pointer to the start of the raw packet data. By casting this pointer to an ethhdr (Ethernet header) structure, the program can directly access fields like h_source (source MAC), h_dest (destination MAC), and h_proto (EtherType). For VLAN tags, the program might need to detect the 802.1Q EtherType and then parse the subsequent VLAN header.
Use Cases for an API Gateway/Networking:
- Basic Filtering and Firewalling: Dropping packets from specific malicious MAC addresses or allowing traffic only from trusted sources.
- Load Balancing (L2): In specific scenarios, an API gateway might distribute traffic based on source MAC for certain legacy systems or specialized network setups, though this is less common than L3/L4 load balancing.
- Network Segmentation: Identifying and enforcing VLAN policies at a very early stage.
- Telemetry: Collecting statistics on MAC address activity for network health monitoring and troubleshooting.
- DDoS Mitigation: Identifying and blocking traffic floods originating from spoofed or specific MAC addresses at the earliest point possible.
The ability to manipulate packets at Layer 2 with XDP provides an extremely efficient mechanism to drop unwanted traffic before it consumes further kernel resources, making it a powerful first line of defense for any internet-facing system or gateway.
Layer 3: The Network Layer – IP Addresses and Routing Information
Moving up the stack, the Network Layer (Layer 3) is responsible for logical addressing and routing across different networks. Once an eBPF program identifies an IPv4 or IPv6 packet (via the EtherType), it can parse the IP header.
Key data points extractable at Layer 3 include:
- Source IP Address: The logical address of the sender. This is fundamental for identifying the origin of traffic.
- Destination IP Address: The logical address of the intended final recipient. Crucial for routing decisions.
- IP Protocol: A single byte field indicating the next-layer protocol being carried (e.g.,
6for TCP,17for UDP,1for ICMP). - Time To Live (TTL): A field that limits the lifespan of a packet to prevent it from circulating indefinitely in a routing loop. Each router decrements the TTL; if it reaches zero, the packet is discarded.
- IP Flags and Fragmentation Offset: Indicate if the packet is fragmented and its position within the original, larger packet.
- Type of Service (ToS)/Traffic Class: Fields used for Quality of Service (QoS) differentiation, though often repurposed for Explicit Congestion Notification (ECN).
How eBPF accesses it: After parsing the Ethernet header, the eBPF program advances its pointer to the IP header. By casting this to an iphdr (IPv4) or ipv6hdr (IPv6) structure, it can directly read fields like saddr (source IP), daddr (destination IP), protocol (next-layer protocol), and ttl.
Use Cases for an API Gateway/Networking:
- IP-based Filtering and Firewalling: This is a cornerstone of network security. eBPF can implement highly efficient IP-based access control lists (ACLs), blocking known malicious IP ranges or allowing traffic only from authorized networks. An API gateway often relies on these rules to protect its backend services.
- Load Balancing (L3): Directing traffic to different backend servers based on source or destination IP addresses. While less common for the fine-grained load balancing an API gateway often needs, it's useful for certain scenarios.
- DDoS Mitigation: Detecting and rate-limiting traffic from specific IP addresses that are part of a volumetric attack. XDP's ability to drop packets at this stage is incredibly powerful against IP floods.
- Routing Decisions: Dynamically altering routing paths based on IP addresses, perhaps for traffic engineering or multi-homing.
- Network Observability: Collecting statistics on IP flow, identifying top talkers, and monitoring network topology changes. This helps in understanding who is accessing which API endpoints.
- Source IP spoofing detection: eBPF can detect common forms of source IP spoofing by checking if the source IP address belongs to the same network segment as the incoming interface, though this requires careful implementation.
Layer 3 insights are fundamental for any network device, and eBPF's ability to manipulate this data at kernel speeds provides a robust foundation for building high-performance and secure gateway solutions.
Layer 4: The Transport Layer – Ports and Connection State
The Transport Layer (Layer 4) provides end-to-end communication services, primarily through TCP (Transmission Control Protocol) and UDP (User Datagram Protocol). Once the eBPF program has identified the IP protocol (e.g., TCP or UDP), it can parse the respective header.
Critical data points extractable at Layer 4 include:
- Source Port: The port number used by the sending application.
- Destination Port: The port number used by the receiving application. These are crucial for identifying specific services (e.g., HTTP on 80/443, DNS on 53, database connections, API service ports).
- TCP Flags: For TCP, flags like SYN (synchronize), ACK (acknowledgment), FIN (finish), RST (reset), PSH (push), URG (urgent) indicate the state of a connection (e.g., connection establishment, data transfer, connection termination).
- Sequence Number and Acknowledgment Number: Used by TCP for reliable data transfer and ordering.
- Window Size: Used by TCP for flow control.
- UDP Length: The length of the UDP payload.
How eBPF accesses it: The eBPF program advances its pointer past the IP header to the TCP or UDP header. By casting to tcphdr or udphdr structures, it can access fields like source (source port), dest (destination port), and specific TCP flags.
Use Cases for an API Gateway/Networking:
- Port-based Filtering/Firewalling: Blocking access to specific ports or only allowing traffic to predefined API service ports. This is a common and essential security measure for any gateway.
- Load Balancing (L4): Distributing incoming connections to different backend servers based on destination IP and port. This is a very common technique for API gateway traffic distribution, often using algorithms like round-robin or least connections.
- Connection Tracking: Monitoring the state of TCP connections (SYN, SYN-ACK, ACK handshake, FIN/RST for termination). This helps identify half-open connections (potential SYN floods), long-lived connections, or unexpected connection resets, which can be critical for API availability.
- Rate Limiting: Applying rate limits based on source IP and destination port, preventing a single client from overwhelming an API service.
- Protocol Identification: Accurately identifying the application protocol running on a specific port (e.g., confirming that traffic on port 80 is indeed HTTP).
- Network Observability: Tracking active connections, connection setup times, and connection teardown events for services managed by the API gateway.
The granular control eBPF offers at Layer 4 is invaluable for modern gateway solutions, enabling sophisticated traffic management, robust security, and deep observability into connection dynamics.
Layer 7: The Application Layer – Unveiling API Calls and Application Data
Inspecting data at the Application Layer (Layer 7) is where the true semantic meaning of network traffic often resides. This layer contains the actual application data and protocols like HTTP, HTTPS, DNS, gRPC, and specific API payloads. While eBPF's direct access to raw packet data is excellent for L2-L4, L7 inspection presents unique challenges, primarily due to packet fragmentation, reassembly requirements, statefulness of protocols, and most significantly, encryption.
For unencrypted traffic (e.g., HTTP on port 80, or internal unencrypted API calls), eBPF can parse basic L7 protocol headers. For example, for HTTP, it can extract:
- HTTP Request Method: GET, POST, PUT, DELETE, etc.
- URL/Path: The requested resource path (e.g.,
/users/profile,/api/v1/data). - Query Parameters: Key-value pairs in the URL (e.g.,
?id=123&type=json). - HTTP Headers:
Host,User-Agent,Content-Type,Authorization,Accept, custom API headers. - HTTP Status Codes (for responses): 200 OK, 404 Not Found, 500 Internal Server Error, etc.
- Request/Response Body (partial): For smaller payloads, eBPF might be able to inspect parts of the body, but full reassembly of potentially fragmented TCP streams is complex and generally performed in userspace.
Challenges and eBPF's Approaches for L7:
- Packet Reassembly: TCP traffic can arrive in out-of-order packets and fragments. Reassembling a full L7 message from raw packet data is a stateful operation that is difficult and resource-intensive to perform efficiently within the constrained eBPF kernel environment. Typically, this is handled by userspace applications.
- TLS/SSL Encryption: The most significant barrier. For HTTPS traffic, the payload is encrypted from the client to the server. eBPF programs, running in the kernel, cannot decrypt this traffic without access to the private keys, which is generally not feasible or desirable for security reasons.
How eBPF tackles L7 (indirectly or for unencrypted traffic):
- Direct Parsing (for unencrypted, simple L7 protocols): For protocols like unencrypted HTTP or DNS, an eBPF program can advance its pointer beyond the TCP/UDP header and attempt to parse the application layer header if it's contained within a single packet and is simple enough. It can identify methods, paths, and simple headers.
- Kprobes/Uprobes on Userspace Applications: This is the most powerful method for L7 inspection, especially for encrypted traffic. Instead of inspecting raw packets, eBPF programs can attach Kprobes to kernel functions involved in network operations or, more commonly, Uprobes to specific functions within userspace applications that process network traffic. For example:
- Attaching a Uprobe to the
read()orwrite()syscalls used by annginxserver or an API gateway can capture the raw (decrypted) data being sent to or from the application after the TLS handshake and decryption have occurred. - Attaching Uprobes to specific functions within an API gateway application (e.g., functions that parse HTTP headers, route requests, or apply policies) can provide deep insights into the processed request, including decrypted HTTP headers, URLs, and even parts of the API payload.
- Attaching a Uprobe to the
- eBPF Maps for State: eBPF programs can use maps to maintain state across multiple packets or for aggregation. For example, a program might track requests per API endpoint by storing counts in a map.
Use Cases for an API Gateway/Networking:
- Advanced API Monitoring: Tracking specific API endpoint usage, latency per API call, error rates (e.g., 4xx, 5xx responses). This is invaluable for understanding API health and performance.
- API Security: Detecting specific patterns in HTTP headers or URLs that indicate attacks (e.g., SQL injection attempts, cross-site scripting, unauthorized API access attempts). This is crucial for protecting the backend API services.
- Fine-grained Rate Limiting: Imposing rate limits based on API paths, query parameters, or specific HTTP headers (e.g., limiting requests per user ID or client IP for a particular API).
- Custom API Gateway Policies: Implementing dynamic routing based on HTTP headers, content-based routing, or custom authentication/authorization logic by inspecting L7 data.
- Microservice Observability: Gaining deep visibility into inter-service communication within a microservices architecture, especially when services communicate over HTTP/gRPC.
- Traffic Shaping for APIs: Prioritizing or throttling specific API traffic based on its L7 characteristics.
The ability of eBPF to perform highly granular L7 inspection, especially through Uprobes on API gateway applications, empowers developers and operators to build incredibly robust, observable, and secure API infrastructures. It bridges the gap between low-level network operations and high-level application logic, offering unparalleled control and insight.
Summary of Data Accessibility Across Layers:
To summarize the vast landscape of data eBPF can tap into from incoming packets, consider the following table which delineates the capabilities at various critical hook points. This showcases how eBPF offers a granular spectrum of access, from raw hardware-level details to application-specific insights.
| eBPF Hook Point | Typical Layer Focus | Primary Data Accessible | Common Use Cases for Networking & API Gateways |
|---|---|---|---|
| XDP (eXpress Data Path) | L2, L3, L4 | Raw packet data, MAC addresses (source/destination), EtherType, VLAN tags, IP addresses (source/destination), IP protocol, TTL, TCP/UDP headers (ports, flags). Minimal L7 parsing possible for simple, unencrypted protocols. | High-performance DDoS mitigation (blocking by MAC/IP/Port), L2/L3 Load Balancing, custom firewalling, early packet discard for efficiency, telemetry at ingress for network health, pre-processing for API Gateway traffic (e.g., whitelist known IPs before reaching the gateway's full stack). |
tc (Traffic Control) |
L2, L3, L4, (limited L7) | Same as XDP, but with richer context from the kernel's network stack (e.g., routing decisions). More flexibility for packet modification, re-routing, or queueing. | Ingress/Egress traffic shaping, advanced routing decisions (e.g., routing specific API traffic to different backends), QoS for API services, categorizing API requests for custom API gateway policies, applying network policies based on source/destination IP/Port. Can be used to implement API rate-limiting at a network level. |
| Socket Filters | L4 | Raw packet data available to a specific socket. Can inspect IP, TCP/UDP headers and filter based on them before data reaches the application. | Application-specific firewalls (e.g., protecting a specific API service), specialized API monitoring for particular ports, allowing only certain types of connections to reach an application, isolating vulnerable applications. Useful for restricting which API consumers can connect. |
| Kprobes/Uprobes | Kernel/Userspace (L7) | Function arguments, return values, and memory contents within kernel functions or userspace applications (e.g., an API gateway or reverse proxy like Nginx/Envoy). This allows access to decrypted HTTP headers, URLs, API payload fragments, and internal application logic. | Deep L7 API monitoring (latency, errors, specific API endpoint usage post-decryption), application performance tracing for API gateway components, custom security audits of API request handling logic, observability into internal API calls within microservices, dynamic policy enforcement based on decrypted API request attributes. Can track user authentication/authorization events within the gateway. |
| Tracepoints | Kernel (various layers) | Pre-defined kernel event data, offering insights into specific kernel operations related to networking (e.g., TCP connection states, network device events, packet drops). | System-wide network tracing, debugging kernel network behavior, identifying bottlenecks in the network stack, general network observability for API traffic by correlating kernel events with application behavior, detecting unusual network activity. |
This table underscores that eBPF is not a monolithic tool but a versatile framework whose capabilities are defined by the specific hook points chosen and the ingenuity of the eBPF programs written. Its ability to operate across these diverse layers makes it uniquely powerful for comprehensive network and API management.
eBPF in the Age of Gateways and APIs: A Symbiotic Relationship
The discussion of data extraction would be incomplete without contextualizing eBPF's profound impact on modern network architectures, particularly in the realm of gateway and API gateway solutions. These components are critical for managing the ingress and egress of traffic to and from backend services, enforcing security policies, managing traffic, and providing a unified entry point for API consumers.
An API gateway stands at the forefront of an application ecosystem, acting as a single entry point for all API calls. It handles tasks such as authentication, authorization, rate limiting, traffic management, caching, and often, protocol translation. The efficiency and security of this gateway are paramount, as it directly impacts the performance and reliability of the entire system.
eBPF offers significant advantages for enhancing and extending the capabilities of API gateway implementations:
- Unprecedented Performance: By offloading certain packet processing tasks (like filtering, DDoS mitigation, and even early-stage load balancing) to XDP or
tchooks, eBPF can dramatically reduce the overhead on the userspace API gateway application. This allows the gateway to focus its resources on more complex L7 tasks, leading to higher throughput and lower latency for API requests. - Deep Observability without Instrumentation: Traditional API monitoring often requires integrating specific agents or sidecars, or relies heavily on application-level logging. eBPF provides a non-invasive way to gain deep, kernel-level insights into API traffic, including connection metrics, latency distributions, and even decrypted HTTP payload details (via Uprobes on the gateway process itself). This offers a "ground truth" view of what's happening on the wire, complementing application-level metrics.
- Enhanced Security: eBPF can implement powerful, kernel-level firewalling rules that are more efficient and flexible than traditional
iptablesrules. It can detect and mitigate various attacks (e.g., SYN floods, IP spoofing, port scanning) at the earliest possible stage. For an API gateway, this means a stronger defense against network-level threats before they even reach the gateway's application logic, allowing the gateway to focus on application-layer security. - Dynamic Traffic Management: eBPF enables highly programmable traffic management policies. For instance, an eBPF program can dynamically adjust load balancing decisions based on real-time backend health perceived at the kernel level, or implement sophisticated QoS policies for different classes of API traffic. This allows for highly responsive and adaptive API traffic routing.
- Sidecar-less Service Mesh Potential: In microservices architectures, service meshes often rely on sidecar proxies (like Envoy) for inter-service communication, adding overhead. eBPF is paving the way for "sidecar-less" service mesh implementations, where many proxy functionalities (like traffic interception, policy enforcement, and telemetry) are handled directly in the kernel via eBPF, offering significant performance benefits and reduced resource consumption. This directly impacts how API services communicate internally.
While eBPF provides the foundational layer for high-performance packet processing and observability, managing the entire lifecycle of APIs, from design to deployment, and providing a developer portal for consumption, requires a robust API gateway and management platform. Tools like APIPark, an open-source AI gateway and API management platform, complement eBPF's capabilities by offering comprehensive solutions for integrating AI models, standardizing API formats, prompt encapsulation, and end-to-end API lifecycle management. APIPark's ability to achieve high TPS (over 20,000 TPS on modest hardware) demonstrates the importance of efficient underlying network handling, which eBPF can significantly enhance. Its detailed API call logging and powerful data analysis features further underscore the value of deep packet insights, which eBPF programs can feed into for advanced monitoring and security. By integrating eBPF-powered kernel-level insights, platforms like APIPark can offer an even more comprehensive and efficient solution for governing the modern API landscape.
APIPark is a high-performance AI gateway that allows you to securely access the most comprehensive LLM APIs globally on the APIPark platform, including OpenAI, Anthropic, Mistral, Llama2, Google Gemini, and more.Try APIPark now! 👇👇👇
Mechanisms and Tools: How eBPF Programs Extract and Use Data
Writing eBPF programs involves more than just understanding hook points; it requires leveraging specific eBPF mechanisms and a suite of development tools to bring these programs to life and extract meaningful data.
Key eBPF Mechanisms:
- eBPF Maps: These are versatile kernel data structures that eBPF programs can access to store state, counters, histograms, or configuration data. Maps can be shared between different eBPF programs and between eBPF programs and userspace applications. For data extraction, eBPF programs can:
- Store Metrics: Increment counters for specific API endpoints, track latency buckets, or count unique source IPs.
- Store Configuration: Allow userspace to dynamically update firewall rules (e.g., block lists of IP addresses or API keys), rate limiting thresholds, or routing policies that the eBPF program then enforces.
- Store State: For more complex, stateful packet processing (e.g., tracking TCP connection states for Layer 7 reassembly heuristics), maps can hold connection information.
- eBPF Helper Functions: The kernel exposes a set of well-defined helper functions that eBPF programs can call to perform specific tasks, such as:
bpf_map_lookup_elem()/bpf_map_update_elem(): For interacting with eBPF maps.bpf_ktime_get_ns(): To get the current kernel time in nanoseconds, crucial for latency measurements in API calls.bpf_perf_event_output(): To send data (e.g., detailed event logs, packet samples) from the kernel to userspace via a shared perf event ring buffer. This is a primary mechanism for real-time telemetry from eBPF.bpf_trace_printk(): A simple debugging function to print messages to the kernel's trace buffer, useful during development.
- Context Pointers: At each hook point, the eBPF program receives a context pointer (e.g.,
xdp_mdfor XDP,sk_bufffortcand socket filters). This context provides access to the raw packet data and metadata relevant to that specific hook, enabling the program to navigate headers and extract information.
Development Ecosystem:
The eBPF ecosystem has matured significantly, offering powerful tools that simplify development and deployment:
- BCC (BPF Compiler Collection): A toolkit that allows users to write eBPF programs in Python (or Lua) by embedding C code. BCC handles the compilation, loading, and attachment of eBPF programs, and provides Python wrappers for interacting with eBPF maps and perf event outputs. It's excellent for rapid prototyping and creating dynamic tracing tools.
- bpftrace: A high-level tracing language built on BCC and LLVM. It provides a simple, domain-specific language for writing powerful one-liners to observe kernel and userspace events, making it ideal for quick debugging and system analysis without writing full C programs.
- libbpf: A C/C++ library that serves as the official, low-level interface for working with eBPF programs and maps. It's preferred for building production-grade eBPF applications due to its efficiency and stability. It often works in conjunction with
BPF CO-RE(Compile Once – Run Everywhere), which allows eBPF programs to be compiled once and run on different kernel versions by automatically adjusting for kernel data structure changes. - Go, Rust, and other language bindings: Modern eBPF development often involves writing the eBPF kernel program in C and then a userspace "agent" or "controller" in a high-level language like Go or Rust to load, attach, and interact with the eBPF program (e.g., read data from maps, consume events from ring buffers). These languages provide robust libraries for this interaction.
The combination of powerful in-kernel mechanisms and a rich, evolving toolchain makes eBPF a highly accessible yet profoundly capable technology for detailed network data extraction and dynamic policy enforcement, directly benefiting the agility and security of an API gateway and underlying API services.
Challenges and Considerations: Navigating the eBPF Frontier
While eBPF is undeniably powerful, its adoption and implementation come with a set of challenges and considerations that developers and operators must be aware of:
- Complexity and Learning Curve: Writing efficient and safe eBPF programs requires a deep understanding of kernel internals, networking protocols, and the eBPF instruction set. Debugging eBPF programs, which run in the kernel and have limited debugging tools, can also be challenging. This steep learning curve can be a barrier for new users, though high-level tools like bpftrace are easing this.
- Security Implications (and Safeguards): eBPF programs run with kernel privileges, meaning a malicious or buggy program could potentially compromise the entire system. However, the eBPF verifier is a robust safeguard, enforcing strict rules:
- Termination Guarantee: Programs must always terminate; no infinite loops are allowed.
- Memory Safety: Programs cannot access arbitrary memory addresses or out-of-bounds memory.
- Resource Limits: Programs have size limits and instruction limits to prevent excessive resource consumption.
- Privilege: Only privileged users (root or CAP_BPF capability) can load eBPF programs. Despite these safeguards, careful program design and testing are crucial.
- Performance Overhead: While eBPF is designed for high performance, a poorly written or overly complex eBPF program can still introduce significant overhead. Programs that perform extensive computations, parse large amounts of data, or interact frequently with maps can impact system performance. Optimization and profiling are essential.
- TLS/SSL Encryption as a L7 Barrier: As discussed, inspecting encrypted (HTTPS) traffic at Layer 7 remains a significant hurdle for eBPF when operating on raw packets. While Uprobes offer a workaround by tapping into userspace applications after decryption, this approach requires knowledge of the application's internals and might not be universally applicable without modification. This is a fundamental limitation for deep packet inspection of encrypted API traffic.
- Kernel Version Compatibility: The eBPF feature set is rapidly evolving. Newer eBPF features, helper functions, and map types are frequently added to the Linux kernel. This means an eBPF program developed for a specific kernel version might not run on older kernels or might require adjustments for newer ones. Tools like
BPF CO-RE(Compile Once – Run Everywhere) andlibbpfhelp mitigate this by generating programs that can adapt to different kernel layouts. - Resource Constraints: eBPF programs operate within tight resource constraints (e.g., stack size, map limits). Complex stateful logic or large data buffers are typically pushed to userspace. This means eBPF is best suited for efficient, atomic operations, while complex analytics or long-term storage are handled by companion userspace applications.
- Ecosystem Maturity: While rapidly growing, the eBPF ecosystem is still maturing. Documentation can be fragmented, and best practices are still emerging, particularly for advanced use cases in areas like
api gatewaymanagement.
Addressing these challenges requires a blend of technical expertise, careful architectural design, and a commitment to staying abreast of the latest developments in the eBPF community. Despite these considerations, the benefits of eBPF for deep, high-performance packet data extraction and control often outweigh the complexities, especially for demanding environments like modern API gateway infrastructures.
Real-world Use Cases and Future Trends
The ability of eBPF to extract granular data from incoming packets has opened up a plethora of real-world applications and is driving significant innovation across various domains.
Network Observability: The Eyes of the Network
eBPF has become the gold standard for network observability. It can monitor every packet, connection, and flow without modifying application code or incurring significant overhead.
- Latency and Throughput Analysis: Accurately measuring the latency of network packets and API requests, identifying bottlenecks, and monitoring throughput for individual applications, services, or API endpoints.
- Connection Tracking and Flow Monitoring: Tracking active TCP connections, their states, duration, and data transfer volumes. This is invaluable for understanding service dependencies and resource utilization, especially for an API gateway managing hundreds or thousands of concurrent connections.
- Packet Drops and Errors: Identifying precisely where and why packets are being dropped in the kernel's network stack, which is critical for debugging network issues and ensuring API reliability.
- DNS Resolution Monitoring: Observing DNS queries and responses to diagnose resolution issues that can impact API connectivity.
Security: Fortifying the Digital Perimeter
eBPF's kernel-level access makes it a formidable tool for network security.
- Advanced Firewalling and Access Control: Implementing highly dynamic and context-aware firewall rules (L2-L7) that can block traffic based on granular criteria, such as specific HTTP headers for API calls, or dynamically updating blocklists for malicious IPs.
- DDoS Mitigation: Leveraging XDP for high-performance packet dropping and rate limiting at the earliest possible stage, effectively blunting volumetric attacks before they can overwhelm upstream API gateway services.
- Intrusion Detection/Prevention: Detecting anomalous network behavior, such as port scans, unusual connection patterns, or even specific attack signatures within unencrypted API payloads, and taking immediate action (e.g., dropping packets, alerting administrators).
- Network Forensics: Recording detailed metadata about network events, which can be invaluable during post-incident analysis for understanding how a breach occurred.
Load Balancing and Traffic Management: Orchestrating the Flow
eBPF is transforming how traffic is managed and distributed, especially for API gateway and microservices environments.
- High-Performance Load Balancing: Implementing sophisticated Layer 4 and Layer 7 load balancing algorithms directly in the kernel, often surpassing the performance of userspace proxies for certain workloads. This allows an API gateway to distribute API requests with minimal latency.
- Custom Routing Policies: Dynamically altering routing decisions based on granular packet characteristics (e.g., directing specific API traffic to a canary deployment).
- Quality of Service (QoS): Prioritizing critical API traffic or applications based on their L3/L4/L7 characteristics, ensuring that high-priority API calls receive preferential treatment.
Service Mesh and Cloud-Native Networking: The Future of Distributed Systems
eBPF is central to the evolution of cloud-native architectures, particularly in Kubernetes and service mesh implementations.
- Sidecar-less Service Mesh: As mentioned, eBPF can offload many functions of a traditional sidecar proxy (like Envoy), such as traffic interception, policy enforcement, and observability, directly into the kernel. This significantly reduces resource consumption and improves performance for inter-service API communication.
- Kubernetes CNI and Kube-Proxy Replacement: eBPF-based Container Network Interface (CNI) plugins (like Cilium) offer high-performance networking, security, and load balancing for Kubernetes pods, often replacing or augmenting
kube-proxyfor service discovery and load balancing within the cluster. This directly impacts how API services deployed in Kubernetes communicate. - Cloud Native Gateways: The capabilities of eBPF are being integrated into next-generation cloud-native gateway solutions, providing them with unparalleled agility, performance, and security features for managing diverse API workloads.
The trajectory of eBPF points towards an increasingly intelligent and responsive kernel, capable of dynamically adapting to network conditions and application demands. This will profoundly impact how we design, deploy, and operate services, particularly those exposed via APIs, setting new benchmarks for performance, security, and observability in the digital age.
Conclusion
The journey through the capabilities of eBPF in extracting data from incoming packets reveals a technology of remarkable depth and transformative potential. From the foundational MAC addresses at Layer 2 to the intricate HTTP headers and API payloads at Layer 7, eBPF provides an unparalleled vantage point into the heart of network communication. Its ability to operate securely and efficiently within the Linux kernel, coupled with its flexible hook points, empowers developers and operators to gain insights and enforce policies that were previously arduous or impossible to achieve.
For the crucial roles of gateway and API gateway solutions, eBPF is not just an enhancement; it's a game-changer. It offers the promise of dramatically improved performance by offloading critical network tasks, deeper and more granular observability without invasive instrumentation, and a robust security posture capable of mitigating threats at their earliest entry points. The synergy between eBPF's kernel-level prowess and comprehensive API management platforms like APIPark unlocks a new era of efficiency, security, and insight for developers and enterprises navigating the complexities of modern distributed systems and API ecosystems.
As the digital landscape continues to evolve, with an ever-increasing reliance on distributed services and API-driven architectures, the power to understand, control, and secure network traffic at such a fundamental level will remain an indispensable asset. eBPF stands at the forefront of this evolution, continuously pushing the boundaries of what is possible in network data extraction and system control.
5 Frequently Asked Questions (FAQs)
1. What is the main advantage of eBPF for network data extraction compared to traditional methods? The main advantage of eBPF is its ability to perform high-performance, kernel-level data extraction and processing without requiring kernel source code modifications or the loading of traditional, potentially unstable kernel modules. This provides unparalleled efficiency, security (due to the in-kernel verifier), and flexibility. Unlike userspace tools that incur context switching overhead, eBPF operates directly where packets are processed, offering significantly lower latency and higher throughput, which is crucial for demanding environments like an API gateway.
2. Can eBPF inspect encrypted (HTTPS) traffic at Layer 7? Directly inspecting encrypted HTTPS traffic by parsing raw packets from kernel hook points (like XDP or tc) is generally not possible because the data payload is encrypted. eBPF programs, running in the kernel, do not have access to the private keys needed for decryption. However, eBPF can inspect decrypted L7 traffic by attaching Uprobes to specific functions within userspace applications (such as an API gateway, web server, or reverse proxy) after the TLS handshake and decryption have occurred. This allows eBPF to gain deep insights into decrypted HTTP headers, URLs, and even portions of API payloads as they are processed by the application.
3. How does eBPF compare to traditional packet capture tools like Wireshark or tcpdump? While Wireshark and tcpdump are invaluable for interactive packet analysis and debugging, they are primarily userspace tools designed for capturing and displaying packet data. They often involve copying full packets from the kernel to userspace, which can be resource-intensive, especially for high-traffic environments. eBPF, in contrast, operates directly in the kernel. It can filter, analyze, and even modify packets before they are copied to userspace or even before they fully enter the kernel's network stack (with XDP). This makes eBPF far more efficient for real-time, high-volume data extraction, policy enforcement, and monitoring, whereas Wireshark/tcpdump are better suited for offline analysis or targeted debugging sessions.
4. What are the performance implications of using eBPF for deep packet inspection? eBPF is designed for high performance, but the actual performance implications depend heavily on the complexity and efficiency of the eBPF program itself. Simple eBPF programs (e.g., basic filtering with XDP) can run with near-native CPU efficiency and introduce negligible overhead, sometimes even improving overall system performance by shedding unwanted traffic early. More complex programs that perform extensive parsing, map lookups, or generate frequent events to userspace can introduce more overhead. The eBPF verifier helps ensure programs are efficient by enforcing resource limits, but careful design, profiling, and optimization of eBPF code are always crucial to maintain low latency and high throughput, particularly for an API gateway handling critical API traffic.
5. How can eBPF enhance an API Gateway? eBPF significantly enhances an API Gateway in several ways: * Performance: It enables offloading tasks like basic firewalling, DDoS mitigation, and even some load balancing to the kernel, reducing the load on the userspace API Gateway application and improving overall throughput and latency for API requests. * Deep Observability: Through Uprobes, eBPF can provide unparalleled insights into API call metrics (latency, errors, specific endpoint usage) at a very low level, even for decrypted traffic, without modifying the API Gateway's code. This enriches monitoring and troubleshooting. * Enhanced Security: eBPF facilitates highly efficient kernel-level security policies (e.g., IP/port filtering, rate limiting) that protect the API Gateway and its backend services from various network attacks. * Dynamic Traffic Management: It allows for flexible and context-aware routing, load balancing, and Quality of Service (QoS) policies for API traffic, enabling more sophisticated and responsive API management.
🚀You can securely and efficiently call the OpenAI API on APIPark in just two steps:
Step 1: Deploy the APIPark AI gateway in 5 minutes.
APIPark is developed based on Golang, offering strong product performance and low development and maintenance costs. You can deploy APIPark with a single command line.
curl -sSO https://download.apipark.com/install/quick-start.sh; bash quick-start.sh

In my experience, you can see the successful deployment interface within 5 to 10 minutes. Then, you can log in to APIPark using your account.

Step 2: Call the OpenAI API.