How to Asynchronously Send Information to Two APIs Efficiently
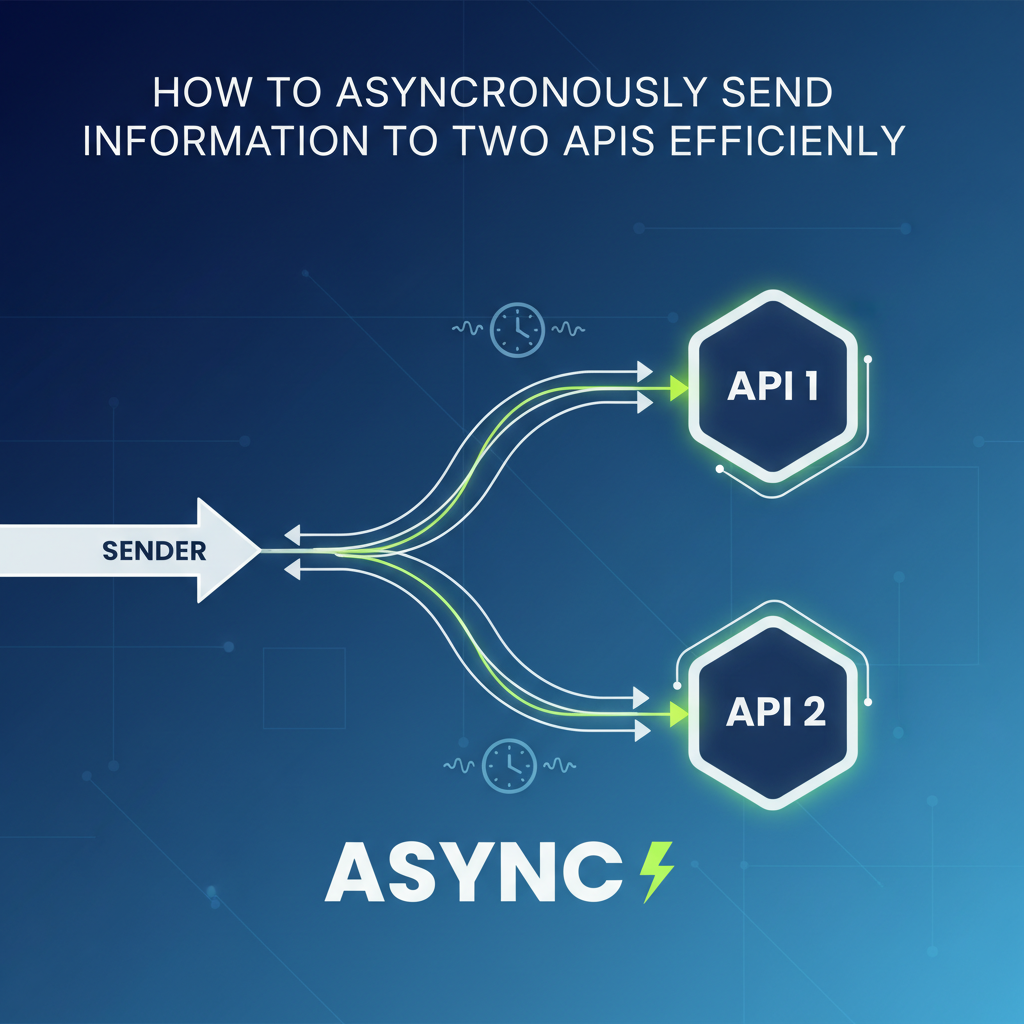


In the intricate tapestry of modern software architecture, where microservices reign supreme and external integrations are the norm, the ability to communicate with multiple Application Programming Interfaces (APIs) is not merely a feature, but a foundational requirement. From e-commerce platforms needing to simultaneously update inventory and process payments, to data aggregators fetching information from various sources to compile a comprehensive view, the scenarios are endless. However, the path to interacting with these external services is fraught with potential pitfalls, especially when dealing with the inherent latency and reliability issues of network communication. The traditional synchronous model, where an application waits for one API call to complete before initiating the next, quickly becomes a bottleneck, severely hindering performance, scalability, and user experience.
Imagine a user clicking a button in a web application. If that single action triggers two independent API calls, and each takes 500 milliseconds, a synchronous approach would force the user to wait for at least a full second before receiving a response, irrespective of whether the calls could have been executed in parallel. This cumulative waiting time escalates dramatically with more API integrations, leading to sluggish interfaces, frustrated users, and inefficient resource utilization on the server side. In a world that demands instant gratification and seamless interactions, such delays are simply unacceptable.
This article delves deep into the critical paradigm of asynchronous communication, exploring its profound importance when orchestrating interactions with two or more API endpoints. We will unpack various strategies, from client-side JavaScript constructs to robust server-side messaging patterns and the transformative power of an API gateway. Our journey will not only cover the theoretical underpinnings but also provide practical insights into implementing these techniques effectively, focusing on crucial aspects like error handling, retry mechanisms, and monitoring. By embracing asynchronicity, developers can build applications that are not just faster, but also more resilient, scalable, and responsive, ultimately delivering a superior experience for end-users and optimizing operational costs for businesses. Our goal is to equip you with the knowledge to navigate the complexities of multi-API communication with confidence, transforming potential bottlenecks into pathways for enhanced efficiency.
Understanding the Core Principles of Asynchronous Communication
To truly appreciate the efficiency gains offered by asynchronous communication, it's essential to first grasp its fundamental nature and how it starkly contrasts with its synchronous counterpart. In the realm of network interactions and computation, these two modes dictate how tasks are executed and how control flow is managed within an application. The choice between them profoundly impacts an application's responsiveness, resource consumption, and overall user experience, particularly when dealing with the inherent uncertainties of external API calls.
Synchronous vs. Asynchronous: A Fundamental Distinction
At its heart, synchronous communication implies a blocking operation. When an application initiates a synchronous task, such as an API request, it pauses its execution and waits for that task to complete before moving on to the next line of code. Think of it like making a phone call: you dial the number, and you wait on the line, doing nothing else, until the person answers or the call fails. This "wait-and-block" model is straightforward to reason about, as the execution flow is linear and predictable. However, when the task involves external network requests, which are inherently slow and prone to delays (due to network latency, server processing time, or external service availability), this blocking behavior becomes a significant liability. Resources (like CPU threads) remain idle, tied up waiting for I/O operations to complete, leading to inefficient utilization and bottlenecks under load. If you have two independent API calls to make, a synchronous approach would force them to execute one after the other, doubling the potential waiting time.
In stark contrast, asynchronous communication is non-blocking. When an application initiates an asynchronous task, it doesn't wait for its completion. Instead, it delegates the task (e.g., an API request) and immediately proceeds to execute other operations. Once the asynchronous task finishes, a predefined mechanism (like a callback function, a promise resolution, or an event) notifies the application, and the results can then be processed. Carrying on with our analogy, asynchronous communication is more like sending an email or leaving a voicemail: you send your message, then you immediately move on to other tasks, and you'll be notified later when you receive a reply. This model allows a single thread of execution to manage multiple I/O operations concurrently, without being tied up waiting for each one individually. This vastly improves resource utilization and overall application responsiveness, making it particularly well-suited for I/O-bound operations like fetching data from external APIs.
Why Asynchronicity is Crucial for Multiple API Calls
The advantages of an asynchronous approach become particularly pronounced when an application needs to interact with multiple API endpoints. Consider the following key benefits:
- Reduced Latency and Improved Responsiveness: The most immediate and significant benefit. When an application needs to call two independent APIs, an asynchronous approach allows these calls to be initiated almost simultaneously. Instead of waiting for
API_CALL_1(which might take 300ms) to finish before startingAPI_CALL_2(another 400ms), both can begin at roughly the same time. In the best-case scenario, the total waiting time for the client becomes dictated by the longest-running API call (400ms), rather than the sum of their durations (700ms). This parallel execution significantly cuts down on overall perceived latency, making applications feel snappier and more responsive. - Enhanced Resource Utilization: In server-side applications, particularly those built with frameworks that utilize a thread-per-request model, synchronous I/O can quickly exhaust server resources. If a thread is blocked waiting for an API response, it cannot serve other requests. Asynchronous I/O, on the other hand, allows a single thread or a limited pool of threads to handle a large number of concurrent connections. When an API call is made, the thread can temporarily relinquish control and serve other requests or perform other computations. Once the API response arrives, the thread can pick up where it left off. This non-blocking nature means fewer threads are needed to handle the same workload, reducing memory footprint and CPU overhead, thereby improving the server's capacity and scalability.
- Better User Experience: For client-side applications (web or mobile), asynchronous operations are paramount for maintaining a fluid user interface. If API calls were synchronous, interacting with a remote service would often freeze the UI, rendering the application unresponsive until the data is fetched. Asynchronicity ensures that network requests run in the background, allowing the UI thread to remain active, process user input, and update the display. This prevents the dreaded "spinning wheel" or frozen application state, providing a much smoother and more pleasant user experience.
- Increased Resilience and Fault Tolerance: Asynchronous patterns often lend themselves more readily to robust error handling and retry mechanisms. When one of two parallel API calls fails, the failure can be isolated and managed without necessarily blocking the entire application or impacting the other successful call. This allows for more granular error recovery, such as retrying only the failed call, providing partial results, or implementing fallbacks, making the application more resilient to transient network issues or external service outages.
- Improved Scalability: By making efficient use of resources and enabling concurrent execution, asynchronous architectures are inherently more scalable. They can handle a greater number of simultaneous requests without significant performance degradation, a critical factor for applications experiencing fluctuating or rapidly growing user bases.
Key Concepts in Asynchronous Programming
While the specific implementations vary across programming languages, several core concepts underpin asynchronous programming:
- Callbacks: This is one of the earliest and most fundamental patterns. A callback function is passed as an argument to an asynchronous function and is executed once the asynchronous task completes. For example, in older JavaScript, an
XMLHttpRequestmight take aonloadcallback. - Promises: A more structured approach, popularized in JavaScript but found in various forms across languages. A promise represents the eventual completion (or failure) of an asynchronous operation and its resulting value. It allows you to attach handlers to an asynchronous action that will be executed once the action completes. Promises help avoid "callback hell" by chaining operations.
- Async/Await: Syntactic sugar built on top of Promises (in JavaScript, C#, Python, etc.), making asynchronous code look and behave more like synchronous code, thereby improving readability and maintainability.
asyncfunctions implicitly return a promise, andawaitpauses the execution of theasyncfunction until the promise settles, allowing the rest of the application to continue. - Futures/Tasks: Similar to Promises, these constructs (found in languages like Java's
Future, Python'sasyncio.Task, C++'sstd::future) represent a result that may not yet be available, providing methods to check for completion or retrieve the result when ready. - Event Loops: Many asynchronous runtimes (like Node.js, Python's
asyncio) rely on an event loop. This is a single-threaded loop that continuously checks for new tasks, I/O events, and callbacks to execute, orchestrating the non-blocking nature of operations.
By understanding these principles and patterns, developers can strategically design their applications to leverage the power of asynchronicity, especially when orchestrating interactions with multiple APIs, leading to vastly more efficient and robust systems.
The Intricacies and Challenges of Coordinating Multiple API Calls
While the benefits of asynchronous communication are undeniable, orchestrating interactions with two or more APIs, especially asynchronously, introduces a new layer of complexity. It's not simply a matter of firing off requests and waiting for responses; a myriad of challenges related to concurrency, error handling, data integrity, and resource management must be meticulously addressed to ensure a robust and efficient system. Ignoring these complexities can lead to unexpected behavior, performance degradation, and even data corruption.
1. Concurrency Management and Resource Saturation
Making multiple asynchronous API calls concurrently can be incredibly efficient, but it's a double-edged sword. Unmanaged concurrency can quickly overwhelm both your client application and the target APIs.
- Client-side Overload: If a browser or mobile app initiates too many parallel network requests, it can exhaust its own network connection limits or consume excessive memory, leading to a sluggish UI or even crashes. Browsers, for instance, typically have a limit on the number of concurrent connections to a single domain.
- Server-side Strain: On the server, creating too many concurrent outbound connections can consume available sockets, file descriptors, and CPU cycles. Each connection has overhead. If your server is making hundreds or thousands of simultaneous API calls without proper management, it can become a bottleneck itself, unable to serve incoming user requests efficiently.
- Target API Overload: Critically, external APIs often have rate limits and throttling mechanisms in place to protect their infrastructure from abuse or excessive load. Firing off too many requests too quickly can lead to your application being temporarily (or permanently) blocked or blacklisted by the target API provider. This is a crucial consideration for maintaining good citizenship in the API ecosystem.
2. Robust Error Handling and Resiliency
The network is inherently unreliable. External APIs can fail for numerous reasons: transient network glitches, server outages, invalid request payloads, authentication failures, or even simply slow responses that time out. When dealing with two or more API calls, the permutations of success and failure multiply, making error handling significantly more complex.
- Partial Failures: What happens if one API call succeeds but the other fails? For example, in an e-commerce transaction, if payment is processed but inventory deduction fails, you have a critical inconsistency. Your system needs a strategy to detect, report, and potentially recover from these partial failures. This might involve rollbacks, compensation logic, or manual intervention.
- Retries with Backoff: Transient errors (like network timeouts or temporary service unavailability) can often be resolved by simply retrying the request. However, naive retries (e.g., immediate re-attempts) can exacerbate the problem, overwhelming an already struggling API. Implementing intelligent retry mechanisms, such as exponential backoff (waiting longer between successive retries) often combined with jitter (adding a small random delay), is crucial to give the target API time to recover and prevent a "thundering herd" problem.
- Circuit Breakers: To prevent cascading failures, especially in microservices architectures, the circuit breaker pattern is invaluable. If an API consistently fails, a circuit breaker can temporarily "open" (preventing further calls to that API), allowing it to recover while providing a fast-fail alternative (e.g., returning a default value or an error immediately) to the calling service. This prevents the caller from wasting resources on doomed requests and protects the failing service from being continuously hammered.
3. Data Consistency and Interdependencies
Many real-world scenarios involve API calls that are not entirely independent. One API call might depend on the result of another, or the combined outcome of multiple calls needs to maintain data consistency across different systems.
- Sequential Dependencies: If
API_CALL_2requires data fromAPI_CALL_1to construct its request, they cannot truly run in parallel. While the initiation ofAPI_CALL_1can be asynchronous,API_CALL_2must wait for its completion. Managing these sequences within an asynchronous framework requires careful orchestration, often using promises,async/await, or message queues. - Transactional Integrity: For operations that must be atomic (either all succeed or all fail), such as updating a user profile across two different services, maintaining consistency becomes paramount. If one update succeeds and the other fails, the data across your systems becomes inconsistent. This often requires complex distributed transaction patterns (like Saga patterns) or careful design to ensure idempotency.
4. Authentication, Authorization, and Security
Each API you interact with likely has its own authentication and authorization requirements. Managing these securely and efficiently across multiple services can be a headache.
- Credential Management: Storing and securely providing API keys, OAuth tokens, or other credentials for multiple distinct APIs needs a robust strategy. Hardcoding is a definite no-go. Centralized secrets management is often required.
- Token Refresh: OAuth tokens typically have an expiration time. Your application needs mechanisms to detect expired tokens and asynchronously refresh them without disrupting ongoing operations or requiring re-authentication from the user.
- Unified Security Policies: Without a centralized control point, applying consistent security policies (e.g., IP whitelisting, rate limiting, logging of access) across all outbound API calls can be challenging.
5. Increased Observability and Debugging Complexity
The asynchronous nature, while beneficial for performance, can make debugging significantly harder. The execution flow is no longer linear, and an error might originate from a call that completed long after it was initiated.
- Logging: Comprehensive and structured logging is essential, including unique request IDs to trace the entire lifecycle of a request across multiple asynchronous API calls.
- Monitoring and Alerting: Real-time monitoring of API call latency, success rates, and error counts for each external service is crucial. Proactive alerts can notify you of issues before they impact users.
- Distributed Tracing: Tools that provide distributed tracing (e.g., OpenTelemetry, Jaeger) can visualize the flow of a single request across multiple services and asynchronous operations, invaluable for identifying performance bottlenecks or points of failure.
- Performance Metrics: Tracking metrics like concurrent requests, queue depths (for message queues), and processing times helps in capacity planning and performance optimization.
Addressing these challenges requires careful design, choice of appropriate architectural patterns, and the strategic use of tooling, including client-side libraries, server-side frameworks, message queues, and perhaps most importantly, a robust API gateway. By proactively tackling these complexities, developers can unlock the true potential of asynchronous multi-API communication.
Core Strategies for Efficient Asynchronous API Calls to Two (and more) APIs
Having understood the benefits and challenges, let's explore the concrete strategies and architectural patterns for efficiently sending information to multiple APIs asynchronously. These approaches span from client-side code techniques to robust server-side infrastructure, each with its own trade-offs and best-fit scenarios.
1. Client-Side Asynchronous Orchestration
For many web and mobile applications, the initial interaction with multiple APIs might happen directly from the client. Modern JavaScript, for example, offers powerful constructs for this.
- Futures/Tasks (Python/Java Conceptual): Similar constructs exist in other languages. Python's
asynciomodule withasync/awaitandasyncio.gather()provides equivalent functionality. Java'sCompletableFuture.allOf()can be used to wait for multiple asynchronous computations to complete. The core idea remains the same: initiate multiple tasks concurrently and provide a mechanism to collect their results once all are done. - Event-Driven Programming: In some client-side architectures, especially with frameworks that use observers or reactive programming (like RxJS), API calls can trigger events, and other parts of the application can subscribe to these events. For two independent API calls, you might subscribe to both completion events and combine their results when both signals have been received.
Promises and Async/Await (JavaScript Example Conceptually): JavaScript's Promise object provides a way to handle asynchronous operations more cleanly than traditional callbacks. When you need to make two (or more) independent API calls and wait for all of them to complete before proceeding, Promise.all() is the go-to method.```javascript async function fetchDataFromTwoAPIs() { try { const [response1, response2] = await Promise.all([ fetch('https://api.example.com/data1'), // API call 1 fetch('https://api.another-example.com/data2') // API call 2 ]);
const data1 = await response1.json();
const data2 = await response2.json();
console.log('Data from API 1:', data1);
console.log('Data from API 2:', data2);
return { data1, data2 };
} catch (error) {
console.error('One of the API calls failed:', error);
throw error; // Propagate the error
}
}fetchDataFromTwoAPIs() .then(results => { // Process combined results }) .catch(err => { // Handle error }); `` In this example,fetch()returns a Promise.Promise.all()takes an array of Promises and returns a new Promise that resolves when all of the input Promises have resolved, or rejects if any of the input Promises reject. Theasync/awaitsyntax makes this highly readable, pausing thefetchDataFromTwoAPIsfunction until bothfetch` operations complete, without blocking the main event loop of the browser or Node.js application.
2. Server-Side Asynchronous Patterns
For more robust and scalable solutions, particularly when dealing with high throughput, complex business logic, or sensitive data, server-side asynchronous patterns are essential.
- Message Queues (e.g., RabbitMQ, Apache Kafka, AWS SQS): Message queues are powerful tools for decoupling services and handling asynchronous processing at scale.
- Producer-Consumer Model: An application (the producer) places a "message" onto a queue, indicating that an operation needs to be performed. This message might contain all the necessary information for two API calls.
- Decoupling: The producer doesn't wait for the message to be processed. It simply puts it on the queue and continues its own work, immediately responding to the client if needed.
- Asynchronous Processing: Separate worker processes (consumers) listen to the queue. When a message arrives, a consumer picks it up and performs the necessary API calls (e.g.,
API_CALL_1andAPI_CALL_2). - Reliability and Retries: Message queues typically offer features like message persistence, acknowledgment mechanisms, and dead-letter queues, which make them highly reliable. If an API call fails, the message can be requeued and retried later, or moved to a dead-letter queue for further investigation, preventing data loss.
- Load Leveling: They act as a buffer, smoothing out spikes in demand. If you have a sudden influx of requests needing two API calls, the queue can hold them, allowing your workers to process them at a sustainable rate without overwhelming the external APIs or your own backend. This pattern is ideal when the client doesn't need an immediate, synchronized response from both APIs, but rather an eventual confirmation or status update.
- Background Jobs/Workers (e.g., Celery for Python, Sidekiq for Ruby, Go routines): Similar to message queues, background job processors allow you to offload time-consuming or non-critical tasks from the main request-response cycle.
- When a request comes in that requires two API calls, the main application quickly initiates a background job.
- This job is then picked up by a separate worker process or thread.
- The worker executes the two API calls, handles their responses, and potentially updates a database or notifies the user upon completion.
- The main application can respond immediately to the client with a "processing" status, greatly improving perceived performance. This approach is particularly useful for tasks like sending notifications, processing images, or complex data calculations that involve multiple external service interactions.
3. Orchestration with an API Gateway
A pivotal component in modern microservices and distributed architectures, an API Gateway acts as a single entry point for all client requests. It sits in front of your backend services (and often external APIs), handling a multitude of concerns that would otherwise clutter your application logic. When it comes to efficiently sending information to two APIs, an API gateway can be a game-changer.
- What is an API Gateway? An API gateway is a service that provides a single, unified entry point for external client requests to various backend services. Instead of clients having to know the addresses and specific endpoints of multiple backend services, they communicate with the API gateway. The gateway then routes requests to the appropriate internal services, often performing additional functions like authentication, rate limiting, caching, and request/response transformation. It's essentially a reverse proxy with added intelligence and management capabilities, centralizing cross-cutting concerns.
- How an API Gateway Helps with Multiple API Calls:For organizations looking to streamline the management and integration of various services, including AI models and REST services, an API gateway like ApiPark offers a comprehensive solution. APIPark is an open-source AI gateway and API management platform designed to help developers and enterprises manage, integrate, and deploy services with ease. It provides capabilities like quick integration of 100+ AI models, unified API format for AI invocation, prompt encapsulation into REST API, and end-to-end API lifecycle management. By centralizing traffic forwarding, load balancing, and versioning of published APIs, APIPark naturally facilitates the efficient, asynchronous orchestration of calls to multiple backend services, making it a powerful tool for complex multi-API scenarios. Its robust features for detailed API call logging and powerful data analysis also provide the crucial observability needed when dealing with distributed asynchronous operations.
- Request Aggregation and Fan-out: One of the most powerful features of an API gateway for our specific problem is its ability to perform request aggregation (also known as "fan-out"). A single client request to the gateway can trigger multiple parallel calls to different backend APIs. The gateway then waits for all (or a defined subset) of these backend responses, aggregates them, transforms them if necessary, and compiles a single, unified response back to the client. This significantly reduces the chattiness between client and server, improves client-side performance, and simplifies client logic. For example, a single request like
/orders/123/detailscould cause the gateway to call/inventory/123and/payments/123simultaneously, combining the results. - Centralized Rate Limiting and Throttling: Instead of implementing rate limiting logic in each individual service or relying solely on external API providers, an API gateway provides a centralized control point to enforce rate limits for all inbound and outbound API traffic. This prevents your backend services from overwhelming external APIs and protects your own infrastructure from client abuse.
- Unified Authentication and Authorization: The gateway can handle authentication and authorization for all requests before they even reach your backend services. This offloads security concerns from individual microservices and ensures a consistent security posture across all APIs. It can inject user identity information into backend requests, simplifying the authentication burden on your internal services.
- Caching: An API gateway can cache responses from backend services. If multiple client requests ask for the same data from an external API (or internal API), the gateway can serve the cached response, reducing the load on the backend service and improving response times.
- Request/Response Transformation: The gateway can modify requests before sending them to backend APIs and transform responses before sending them back to clients. This is invaluable when integrating with legacy APIs or when an external API has a different data format than what your client expects. It can unify diverse API formats into a consistent interface.
- Circuit Breaker Implementation: As discussed earlier, circuit breakers are vital for resilience. Many API gateway solutions offer built-in circuit breaker functionality. If a backend API starts failing consistently, the gateway can automatically open the circuit, preventing further calls to that service and allowing it to recover, while providing a fallback response to the client.
- Service Discovery and Routing: In a dynamic microservices environment, services might scale up or down, or move to different network locations. An API gateway can integrate with service discovery mechanisms (like Consul, Eureka) to dynamically route requests to available service instances, ensuring high availability.
- Request Aggregation and Fan-out: One of the most powerful features of an API gateway for our specific problem is its ability to perform request aggregation (also known as "fan-out"). A single client request to the gateway can trigger multiple parallel calls to different backend APIs. The gateway then waits for all (or a defined subset) of these backend responses, aggregates them, transforms them if necessary, and compiles a single, unified response back to the client. This significantly reduces the chattiness between client and server, improves client-side performance, and simplifies client logic. For example, a single request like
In summary, the choice of strategy—client-side, server-side with queues, or an API gateway—depends heavily on the specific requirements of your application, the volume of traffic, the interdependencies between API calls, and the desired level of resilience and scalability. Often, a combination of these strategies provides the most effective solution.
APIPark is a high-performance AI gateway that allows you to securely access the most comprehensive LLM APIs globally on the APIPark platform, including OpenAI, Anthropic, Mistral, Llama2, Google Gemini, and more.Try APIPark now! 👇👇👇
Implementing Efficient Asynchronous Calls: Best Practices for Robustness and Performance
Merely adopting asynchronous patterns or deploying an API gateway isn't enough; the true efficiency and robustness come from adhering to a set of best practices that address the inherent complexities of distributed systems and network communication. These practices are critical for building reliable, performant, and maintainable applications that gracefully interact with multiple external APIs.
1. Comprehensive Error Handling and Fallbacks
The most fundamental best practice is to assume that any external API call will eventually fail. Your system must be designed to gracefully handle these failures.
- Granular Try-Catch Blocks: Encapsulate each API call (or a group of interdependent calls) within its own error handling construct. This allows you to specifically catch and differentiate errors from
API_CALL_1versusAPI_CALL_2, enabling targeted recovery or reporting. - Specific Error Types: Whenever possible, catch specific error types (e.g., network errors, HTTP status codes like 4xx, 5xx, timeouts) rather than generic exceptions. This allows for more precise handling logic.
- Fallback Mechanisms: For non-critical API calls or when specific data is not absolutely essential, implement fallbacks. This could involve:
- Default Values: Returning a predefined default value if an API call fails (e.g., if a weather API fails, show "weather unavailable" instead of crashing).
- Cached Data: Serving stale data from a cache if the live API call fails.
- Partial Responses: Returning a response that includes data from successful API calls and clearly indicates failures for others.
- Alternative Services: Using a backup API or internal service if the primary external API is down.
- Circuit Breaker Pattern: As highlighted previously, implement circuit breakers (e.g., using libraries like Hystrix, Polly, or built-in gateway features like those found in ApiPark) to prevent your service from repeatedly hammering a failing external API. This pattern quickly fails requests to a troubled service, giving it time to recover and protecting your application from cascading failures.
2. Intelligent Retry Mechanisms
Not all failures are permanent. Transient network issues or temporary API overload often resolve themselves.
- Exponential Backoff: Instead of immediately retrying a failed API call, wait for progressively longer periods between retries (e.g., 1s, then 2s, then 4s, then 8s). This prevents "thundering herd" scenarios where your application's retries exacerbate the problem for an already struggling API.
- Jitter: Add a small random component (jitter) to your exponential backoff delays. This helps prevent multiple instances of your application from retrying at precisely the same time after an outage, which could create a new spike in traffic.
- Maximum Retries: Define a sensible upper limit for the number of retries. Beyond this limit, the error should be escalated (logged, alerted, moved to a dead-letter queue) rather than continuing to retry indefinitely.
- Idempotency: Ensure that the API calls you are retrying are idempotent. An idempotent operation is one that can be applied multiple times without changing the result beyond the initial application. For example, updating a resource with a specific value is often idempotent, but incrementing a counter is not. If an API is not idempotent, retrying it blindly could lead to unintended side effects (e.g., duplicate orders, double charges). Design your API calls and backend logic to handle idempotency where retries are possible.
3. Concurrency Limits and Resource Management
While concurrency is good, unbounded concurrency is dangerous.
- Connection Pooling: Reuse existing network connections to target APIs rather than establishing a new one for each request. This reduces the overhead of TCP handshakes and TLS negotiations, improving efficiency, especially for HTTP/1.1 connections. HTTP/2 and HTTP/3 offer multiplexing over a single connection, further optimizing this.
- Thread/Process Pool Limits: On the server side, configure appropriate limits for thread pools or worker processes that handle outbound API calls. Too few can bottleneck your application; too many can exhaust server resources (CPU, memory, file descriptors).
- Semaphore/Rate Limiter Implementation: Implement client-side rate limiters or semaphores to control the maximum number of concurrent requests your application makes to a specific external API. This respects the API provider's limits and prevents your application from getting throttled or blocked. An API gateway is excellent for centralizing this control.
4. Robust Monitoring and Observability
When dealing with asynchronous calls across multiple services, visibility into their behavior is non-negotiable.
- Detailed Logging: Implement comprehensive, structured logging for every API call: request payload, response payload, latency, HTTP status code, and any errors. Crucially, correlate these logs using a unique
request_idortrace_idthat propagates across all services involved in a transaction. This allows you to trace a complete end-to-end flow, even across asynchronous boundaries. APIPark offers detailed API call logging, recording every detail of each call, which is invaluable for tracing and troubleshooting. - Metrics and Alerting: Collect metrics on success rates, error rates, average/p99 latency for each external API. Set up alerts for deviations from normal behavior (e.g., sudden increase in error rates, significant latency spikes). This helps in proactive problem detection.
- Distributed Tracing: Utilize distributed tracing tools (like OpenTelemetry, Jaeger, Zipkin) to visualize the entire path of a request as it flows through your system and interacts with multiple external APIs. This is incredibly powerful for debugging performance bottlenecks and identifying the root cause of failures in complex asynchronous workflows.
- Performance Analysis: Leverage tools that can analyze historical call data to display long-term trends and performance changes. This helps in preventive maintenance and capacity planning. APIPark also provides powerful data analysis features to help businesses with preventive maintenance before issues occur.
5. Idempotency by Design
As mentioned in retries, designing your API interactions and your own services to be idempotent is a cornerstone of robust distributed systems.
- If an API call that modifies state (e.g., creating a resource, transferring money) can be executed multiple times without producing different results after the first successful execution, it vastly simplifies retry logic and recovery from network failures.
- Achieve idempotency by using unique transaction IDs provided by the client or generated by your system, and ensuring that the backend API checks for these IDs to prevent duplicate processing.
6. Timeouts for All External Calls
Never make an external API call without a defined timeout. Without timeouts, a slow or unresponsive external API could tie up your application's resources indefinitely, leading to cascading failures.
- Set sensible timeouts for connection establishment and response reception.
- Different timeouts might be appropriate for different APIs based on their typical performance characteristics.
7. Versioning Strategy
External APIs evolve. A clear versioning strategy (e.g., api.example.com/v1/resource) helps manage changes and ensures that your application continues to function even as the API provider introduces new versions. This is part of the end-to-end API lifecycle management capabilities often found in API gateway platforms like ApiPark.
8. Choosing the Right Tool/Pattern
The "best" way to send information to two APIs asynchronously isn't universal. It depends on:
- Interdependence: Are the calls truly independent, or does one rely on the other?
- Latency Requirements: Does the client need an immediate, aggregated response, or is eventual consistency acceptable?
- Scale: Are you dealing with a few requests per second or thousands?
- Reliability: How critical is it that both calls succeed without data loss?
- Existing Infrastructure: What tools and platforms are already in use?
By diligently applying these best practices, developers can transform the inherent complexities of asynchronous multi-API communication into a powerful capability, building highly efficient, resilient, and scalable applications.
Comparison of Asynchronous Strategies
To further clarify the choice of strategy, let's look at a comparative table of the main approaches discussed:
| Feature/Criterion | Client-Side (Promises/Async-Await) | Server-Side (Message Queues/Background Jobs) | API Gateway (e.g., APIPark) |
|---|---|---|---|
| Complexity | Relatively low for simple parallel calls. | Higher setup and operational complexity. | Moderate to high, but centralizes many concerns. |
| Reliability | Dependent on client uptime; network issues can lead to data loss. | High. Messages persist; retry mechanisms built-in. | High. Centralized error handling, retries, circuit breakers. |
| Latency (to client) | Excellent for independent calls (longest call dictates wait). | Can be higher as processing is offloaded, but client gets immediate ack. | Excellent. Aggregates calls, reducing client chattiness. |
| Scalability | Limited by client resources and browser concurrency limits. | Very high. Decoupled workers can scale independently. | Very high. Acts as a scalable ingress/egress point. |
| Resource Usage | Client-side CPU/memory for processing. | Server-side CPU/memory for queue management and workers. | Dedicated server resources for gateway operations. |
| Error Handling | Needs explicit client-side logic (e.g., Promise.allSettled). |
Robust due to message re-queuing, dead-letter queues. | Centralized management of errors, retries, fallbacks. |
| Primary Use Case | UI responsiveness for fetching display data; independent operations. | Long-running tasks, high-volume data processing, decoupling microservices. | Centralized API management, request aggregation, security, traffic control. |
| Data Consistency | Requires client to manage dependencies or combine results. | Eventual consistency; can implement Saga patterns. | Gateway can enforce dependencies or aggregate consistent results. |
| Security | Client credentials often visible; relies on CORS/APIs' own auth. | Server-side security; credentials never exposed to client. | Centralized authentication, authorization, threat protection. |
This table provides a quick reference to guide your decision-making process when choosing the most appropriate strategy for your specific application requirements.
Case Study: An E-commerce Order Processing System
To solidify our understanding, let's walk through a conceptual case study in an e-commerce context, illustrating how asynchronous communication with two APIs can be efficiently managed.
Scenario: A customer places an order on an online store. This single user action triggers two critical backend operations: 1. Inventory Deduction API: Update the stock levels for the ordered products. 2. Payment Processing API: Authorize and capture payment for the order.
Both operations are essential, but they have different characteristics and requirements. The payment processing is external (e.g., Stripe, PayPal) and critical for revenue, while inventory deduction is often an internal or partner API, vital for operational consistency. If either fails, the order is in an invalid state.
The Problem with Synchronous Processing
If our e-commerce backend were to process this synchronously: 1. The customer clicks "Place Order." 2. The backend calls the Inventory Deduction API. It waits for 300ms. 3. Upon success, it then calls the Payment Processing API. It waits for another 500ms. 4. If both succeed, the order is confirmed, and the customer receives a response after 800ms (plus internal processing). 5. If the Inventory API is slow, the Payment API is delayed. If Inventory fails, Payment isn't even attempted, and the customer receives an error. This is inefficient and prone to long wait times.
Solution with Asynchronous Communication and an API Gateway
A more robust and efficient approach would leverage asynchronous communication, potentially orchestrated by an API Gateway.
- Client Request: The customer's browser sends a single "Place Order" request to the e-commerce application's API Gateway. This request contains order details (items, quantity, customer info, payment token).
- API Gateway Orchestration (with ApiPark):
- The API Gateway receives the request. Instead of routing to a single backend service, it's configured to trigger a fan-out pattern.
- Parallel Internal Calls: The gateway immediately makes two independent, asynchronous calls to its backend services:
- Internal Inventory Service: Sends a request to deduct items.
- Internal Payment Orchestration Service: Sends a request to initiate payment (which in turn calls the external
Payment Processing API).
- Unified Security and Rate Limiting: The gateway centrally handles authentication for the client and applies rate limits to protect both the internal services and the external payment provider.
- Request/Response Transformation: If the external
Payment Processing APIrequires a specific format, the gateway (or the Payment Orchestration Service) can transform the request. - Monitoring and Logging: APIPark provides detailed call logging, allowing the operations team to monitor the latency and success rate of both the internal inventory deduction and the external payment initiation in real-time.
- Backend Service Processing:
- Inventory Service: Processes the deduction. If successful, it updates its database and sends an acknowledgment back to the API Gateway (or a message queue if further decoupling is desired).
- Payment Orchestration Service: Calls the external
Payment Processing APIasynchronously. If the external API takes 500ms, this service waits for that response. It implements retry logic with exponential backoff for transient payment failures and uses a circuit breaker for repeated failures to protect the external API. Upon success or failure, it notifies the API Gateway.
- Gateway Aggregation and Response:
- The API Gateway waits for responses from both the
Inventory ServiceandPayment Orchestration Service. Since these were initiated in parallel, the total waiting time for the gateway is approximately the duration of the longest backend call (e.g., 500ms for payment, plus internal processing, significantly less than 800ms+). - Error Handling:
- If both succeed, the gateway sends a "Order Confirmed" response to the client.
- If
Inventoryfails butPaymentsucceeds, the gateway could trigger a "rollback" action on thePayment(e.g., void the transaction) and respond with an "Order Failed: Inventory Issue" message. - If
Paymentfails, the gateway responds with an "Order Failed: Payment Issue".
- Transaction Status: The gateway might also update an "Order Status" service asynchronously in the background via a message queue, providing eventual consistency for detailed order tracking.
- The API Gateway waits for responses from both the
- Client Response: The customer receives a much faster response (e.g., 550ms vs. 800ms+), improving their experience. If a background update is needed, the client might show "Processing" and then receive a real-time update via WebSockets or polling later.
Advantages of this Approach:
- Improved Performance: Parallel execution reduces overall latency.
- Enhanced Resilience: Individual service failures can be isolated and handled. Retries, circuit breakers, and fallbacks protect the system.
- Decoupling: The client only interacts with the API Gateway, unaware of the complex backend orchestration.
- Centralized Control: The API Gateway provides a single point for security, rate limiting, and observability. APIPark's end-to-end API lifecycle management capabilities would be instrumental here, from design and publication to invocation and monitoring.
- Scalability: Each backend service (Inventory, Payment Orchestration) can scale independently. The gateway itself can be deployed in a cluster for high availability and performance, rivalling Nginx, as APIPark promises.
This case study demonstrates how an API gateway serving as an orchestration layer can abstract away the complexities of interacting with multiple backend APIs, enabling highly efficient, resilient, and scalable asynchronous processing for critical business operations like order placement.
Advanced Considerations in Asynchronous API Interactions
As applications grow in complexity and demands for real-time responsiveness intensify, developers often need to look beyond basic asynchronous patterns to more advanced techniques. These considerations build upon the foundations we've discussed, offering even greater flexibility and efficiency in specific scenarios.
1. Webhooks: Inverting the Communication Flow
Traditional API calls follow a request-response model, where the client actively polls or requests information from a server. Webhooks, on the other hand, invert this flow, allowing the server to proactively "push" information to a client when a significant event occurs.
- How it Works: Instead of repeatedly asking an API "Has X happened yet?", your application registers a callback URL (its webhook endpoint) with the external API. When the event X occurs, the external API sends an HTTP POST request to your registered webhook URL, notifying your application in real-time.
- Efficiency for Multiple APIs: Imagine needing to know when an external payment is processed and when a shipping label is generated by a third-party logistics provider. Instead of your system constantly polling both services, each service can asynchronously send a webhook notification to your application. Your application's webhook listener then processes these incoming events, potentially triggering further internal asynchronous actions. This eliminates unnecessary polling, reduces network traffic, and provides near real-time updates without blocking resources.
- Use Cases: Payment confirmations, order status updates, new user registrations in an external identity provider, third-party service event notifications.
- Challenges: Securing webhook endpoints (authenticating incoming requests, verifying signatures), handling potential duplicate deliveries, and ensuring your endpoint is highly available to receive notifications.
2. Server-Sent Events (SSE) and WebSockets: Real-time Bidirectional Communication
For scenarios requiring continuous streams of data or truly interactive, real-time communication, SSE and WebSockets offer distinct advantages over traditional HTTP requests.
- Server-Sent Events (SSE):
- Provides a one-way, persistent connection from the server to the client.
- The client establishes an HTTP connection, and the server continuously pushes events down that connection.
- Ideal for scenarios where the client needs real-time updates from the server, but the client doesn't need to send frequent data back (e.g., stock tickers, news feeds, live dashboards).
- When multiple backend APIs contribute to a real-time feed, your server can asynchronously collect data from these APIs and then push aggregated updates to clients via SSE.
- WebSockets:
- Establishes a full-duplex, bidirectional communication channel over a single TCP connection.
- Allows both client and server to send messages to each other at any time, without the overhead of HTTP headers for each message.
- Perfect for highly interactive applications like chat, online gaming, collaborative editing, or any scenario where low-latency, two-way communication is critical.
- When your application acts as an intermediary, fetching data from two APIs and needing to relay updates to clients instantly, WebSockets provide the most efficient transport. Your backend can asynchronously call
API_1andAPI_2, combine their results, and push them to relevant WebSocket clients.
- Challenges: Managing persistent connections, scaling WebSocket servers, implementing robust reconnection logic, and handling message ordering and delivery guarantees.
3. Event Sourcing and CQRS: For Complex, Data-Intensive Systems
For highly complex enterprise applications, especially those dealing with significant data changes and auditability requirements, patterns like Event Sourcing and Command Query Responsibility Segregation (CQRS) can be extremely powerful.
- Event Sourcing:
- Instead of storing the current state of an entity, you store a sequence of all the state-changing events that have occurred. The current state is then derived by replaying these events.
- When an operation requires interaction with two APIs, this might involve publishing an "OrderPlaced" event. Different services (or "event handlers") can then asynchronously subscribe to this event. One handler might trigger the
Inventory Deduction APIcall, another might trigger thePayment Processing APIcall. - This provides a robust audit log, simplifies debugging (you can replay events to understand what happened), and naturally lends itself to asynchronous processing and eventual consistency across multiple services.
- CQRS (Command Query Responsibility Segregation):
- Separates the model for updating information (the "command" side) from the model for reading information (the "query" side).
- Commands often involve complex business logic and interactions with multiple external systems (e.g., calling two APIs). They can be processed asynchronously.
- Queries, on the other hand, are optimized for fast reads, often against denormalized data structures.
- When combined with Event Sourcing, CQRS allows commands to generate events (which are then stored) and query models to be asynchronously updated by consuming these events. This allows high read scalability and transactional integrity on the write path, even with multiple asynchronous API interactions.
- Challenges: High conceptual and operational complexity, increased infrastructure needs (event store, multiple read/write models), and a steeper learning curve.
4. Service Meshes: For Advanced Microservices Management
In highly distributed microservices environments, a service mesh (e.g., Istio, Linkerd) takes the concept of network control and observability to an even higher level, complementing an API Gateway.
- What it Does: A service mesh provides a dedicated infrastructure layer for managing service-to-service communication. It typically uses sidecar proxies (e.g., Envoy) deployed alongside each microservice. These proxies intercept all inbound and outbound network traffic for the service.
- Benefits for Multiple API Calls:
- Traffic Management: Fine-grained control over routing, load balancing, and traffic shifting between services, even across multiple versions.
- Resilience: Built-in circuit breakers, retries, and timeouts for inter-service communication, simplifying the implementation of these patterns at the application level.
- Observability: Provides deep insights into service communication, including tracing, metrics, and logging, without requiring application-level code changes.
- Security: Enforces mTLS (mutual TLS) between services, providing strong identity-based authentication and encryption for all communications.
- Relationship with API Gateway: An API Gateway (ApiPark as an example) handles "north-south" traffic (client-to-service), while a service mesh manages "east-west" traffic (service-to-service). They work together: the gateway secures and routes external requests to the correct initial microservice, and then the service mesh ensures robust and observable communication between that microservice and any subsequent internal services, which might involve calling multiple internal or external APIs.
- Challenges: Adds significant operational overhead and complexity to your infrastructure, requires Kubernetes (or similar container orchestration) experience.
These advanced considerations are not always necessary for every application but become invaluable as systems scale, demand higher levels of real-time interaction, or require more sophisticated data consistency and audit trails. Choosing the right pattern depends heavily on the specific domain, performance requirements, and engineering maturity of the team.
Conclusion
In the contemporary landscape of interconnected applications and distributed systems, the ability to efficiently send information to two or more APIs asynchronously is no longer a luxury but a fundamental necessity. We've journeyed through the core principles that differentiate asynchronous communication from its synchronous counterpart, highlighting how non-blocking operations are pivotal for enhancing responsiveness, optimizing resource utilization, and ultimately delivering a superior user experience. The compounding delays and resource wastage inherent in synchronous calls simply cannot meet the demands of modern digital interactions.
However, the path to multi-API asynchronous efficiency is not without its challenges. We've meticulously examined the complexities of managing concurrency, ensuring data consistency, implementing robust error handling and retries, navigating authentication nuances, and the critical need for comprehensive observability in a distributed environment. Overlooking these intricacies can quickly transform performance gains into operational nightmares.
To address these challenges, we explored a spectrum of powerful strategies. From client-side Promise.all() and async/await for immediate parallel fetching, to robust server-side patterns involving message queues and background workers for decoupled, scalable processing. Crucially, we delved into the transformative role of an API gateway. As a centralized control point, an API gateway like ApiPark can aggregate requests, manage traffic, enforce security, apply rate limiting, and implement resilience patterns such as circuit breakers. It acts as an intelligent orchestrator, abstracting away the complexity of multiple backend API interactions, and providing a unified, efficient interface for clients. By offering features for end-to-end API lifecycle management, detailed call logging, and powerful data analysis, APIPark exemplifies how a well-chosen API gateway can become an indispensable asset in mastering asynchronous multi-API communication.
Beyond these core strategies, we touched upon advanced considerations such as Webhooks for event-driven push notifications, Server-Sent Events and WebSockets for real-time bidirectional flows, and the architectural power of Event Sourcing and Service Meshes for highly complex and scalable microservices. Each of these offers further avenues for optimization, tailored to specific requirements for real-time interaction, data integrity, and operational control.
Ultimately, building efficient and robust applications that interact with multiple APIs asynchronously requires a thoughtful combination of design choices, architectural patterns, and adherence to best practices. By carefully considering the interdependencies of your API calls, the required latency, the desired level of reliability, and the scale of your operations, you can select and implement the most appropriate strategies. The goal is to create systems that are not only performant and scalable but also resilient to the inevitable failures of network communication, ensuring a seamless and reliable experience for all users. Embracing these principles is not just about writing faster code; it's about engineering a more responsive, reliable, and future-proof digital infrastructure.
Frequently Asked Questions (FAQ)
1. What is the main benefit of sending information to two APIs asynchronously instead of synchronously?
The primary benefit is significantly reduced latency and improved responsiveness. When API calls are asynchronous, they can be initiated in parallel, meaning the total time spent waiting for responses is dictated by the slowest API call, not the sum of all their durations. This prevents your application from blocking and allows it to process other tasks or maintain a responsive user interface, leading to a much better user experience and more efficient resource utilization.
2. When should I use a client-side asynchronous approach (e.g., Promise.all in JavaScript) versus a server-side one (e.g., message queues or an API Gateway)?
Client-side asynchronous approaches are ideal when the client needs an immediate, aggregated response from relatively independent API calls, and the total number of such calls is manageable. It's great for fetching data to populate a UI. Server-side approaches (message queues, background jobs, or an API Gateway like ApiPark) are preferred for high-volume transactions, long-running operations, or when you need greater reliability, security, and scalability. They decouple the client from complex backend orchestration, allowing for robust error handling, retries, and independent scaling of services.
3. How does an API Gateway help with asynchronous calls to multiple APIs?
An API Gateway acts as a central entry point that can orchestrate calls to multiple backend APIs on behalf of a single client request. It can perform "request aggregation" or "fan-out," initiating parallel calls to two or more internal/external APIs, waiting for their responses, and then compiling a single, unified response for the client. This reduces client-server chattiness, simplifies client logic, and allows the gateway to centrally manage cross-cutting concerns like authentication, rate limiting, caching, and implementing resilience patterns (e.g., circuit breakers) for all backend interactions.
4. What are common pitfalls when implementing asynchronous multi-API calls, and how can they be avoided?
Common pitfalls include: * Unmanaged Concurrency: Overwhelming target APIs or your own system with too many simultaneous requests. Avoid by implementing client-side concurrency limits, connection pooling, and leveraging an API Gateway for centralized rate limiting. * Poor Error Handling: Failing to account for partial failures or transient network issues. Mitigate with granular error handling, intelligent retry mechanisms (exponential backoff with jitter), and circuit breaker patterns. * Lack of Observability: Difficulty in debugging issues due to non-linear execution. Address with comprehensive, correlated logging, detailed metrics, and distributed tracing tools. * Data Inconsistency: Issues arising from interdependent API calls that don't complete transactionally. Design for idempotency and consider patterns like Saga for complex distributed transactions.
5. What is idempotency, and why is it important for asynchronous API calls and retries?
Idempotency means that an operation can be applied multiple times without changing the result beyond the initial application. For example, setting a user's status to "active" is idempotent (doing it once or five times results in the same "active" status), but incrementing a counter by one is not. Idempotency is crucial for asynchronous API calls because network unreliability often necessitates retries. If an API call that modifies state (like deducting inventory or processing a payment) is not idempotent, retrying it blindly could lead to unintended side effects like duplicate orders or double charges. Designing APIs and your calling logic to be idempotent ensures that even if a request is processed multiple times due to retries, the system's state remains consistent and correct.
🚀You can securely and efficiently call the OpenAI API on APIPark in just two steps:
Step 1: Deploy the APIPark AI gateway in 5 minutes.
APIPark is developed based on Golang, offering strong product performance and low development and maintenance costs. You can deploy APIPark with a single command line.
curl -sSO https://download.apipark.com/install/quick-start.sh; bash quick-start.sh

In my experience, you can see the successful deployment interface within 5 to 10 minutes. Then, you can log in to APIPark using your account.

Step 2: Call the OpenAI API.

