How to Circumvent API Rate Limiting: Effective Strategies



The modern digital landscape is increasingly powered by application programming interfaces (APIs), acting as the nervous system connecting disparate software systems, services, and applications. From fetching real-time stock quotes and processing payments to integrating AI models and synchronizing data across cloud platforms, APIs are indispensable. However, the ubiquitous nature of APIs comes with a critical operational challenge: rate limiting. Implemented by API providers to protect their infrastructure, ensure fair usage, and manage operational costs, rate limits dictate how many requests a client can make within a specified timeframe. For developers and businesses relying on these external services, encountering a rate limit wall can halt operations, degrade user experience, and incur significant costs.
Circumventing API rate limits isn't about breaching security or engaging in unethical practices; rather, it’s about understanding the underlying mechanisms, respecting the provider's intent, and employing intelligent, robust strategies to ensure your application remains operational, performs optimally, and scales effectively without hitting those artificial ceilings. It's about designing your systems to be resilient and efficient, capable of navigating the ebb and flow of API availability. This comprehensive guide will delve deep into the nuances of API rate limiting, explore various algorithms used, and, most importantly, provide an exhaustive array of strategies—from fundamental client-side tactics to advanced infrastructure-level solutions involving API gateways—that empower you to effectively manage, anticipate, and circumvent the common pitfalls of stringent API usage policies. We will equip you with the knowledge to build applications that not only consume API resources responsibly but also thrive in environments where resource access is carefully metered and controlled.
1. Understanding API Rate Limiting Mechanics: The Foundation of Effective Management
Before one can effectively navigate or "circumvent" API rate limits, a profound understanding of their mechanics is paramount. Rate limiting is not an arbitrary restriction but a fundamental protective measure, a digital speed bump designed to regulate traffic and maintain service stability. Grasping its purpose and implementation details is the first step towards building resilient API consumers.
1.1. What Exactly is Rate Limiting?
At its core, API rate limiting is a technique used by service providers to control the number of requests a user or client can make to an API within a given time window. Imagine a bustling highway with a speed limit; without it, traffic would become chaotic, leading to congestion and potential accidents. Similarly, without rate limits, a single malicious actor or even a poorly optimized legitimate application could overwhelm an API server, leading to denial-of-service for all users, increased operational costs for the provider, and potential data integrity issues. It's an enforced policy, typically implemented at the API gateway or server-side, that monitors incoming requests and, once a predefined threshold is crossed, temporarily blocks or delays subsequent requests from that client. This enforcement ensures a predictable and stable experience for the entire user base while safeguarding the underlying infrastructure.
1.2. Why Do APIs Impose Rate Limits? The Provider's Perspective
Understanding the motivations behind rate limits provides critical context for developing effective circumvention strategies. Providers don't impose these limits to be obstructive; they do so for a multitude of valid reasons, each designed to ensure the health and longevity of their service:
- Preventing Abuse and Malicious Activity: The most immediate reason is protection against attacks like Distributed Denial of Service (DDoS), brute-force login attempts, or aggressive web scraping. By limiting the request volume from a single source, providers can mitigate the impact of such activities, preventing their services from becoming unresponsive. A sudden spike in requests from an unusual IP address or API key can be indicative of nefarious intent, and rate limits act as a first line of defense.
- Ensuring Fair Usage for All Clients: In a shared resource environment, one "greedy" client could hog all available server capacity, leaving other legitimate users with slow responses or outright service unavailability. Rate limits distribute access equitably, ensuring that all clients receive a reasonable share of the system's resources, thus maintaining a positive user experience across the board. This is particularly crucial for public APIs with a diverse user base.
- Managing Infrastructure Load and Costs: Every API request consumes server CPU, memory, network bandwidth, and database operations. Unchecked request volumes can quickly escalate infrastructure costs, especially in cloud-based environments where scaling resources dynamically can be expensive. Rate limits help providers keep their operational expenses under control by preventing runaway resource consumption and allowing for more predictable capacity planning.
- Protecting Data Integrity and Database Load: Frequent, high-volume write operations or complex read queries can put immense strain on backend databases, potentially leading to performance degradation, locking issues, or even data corruption. Rate limits act as a buffer, preventing a flood of database operations that could jeopardize the integrity and availability of critical data stores.
- Enabling Tiered Service and Monetization Strategies: Many API providers offer different service tiers (e.g., free, basic, premium, enterprise), each with varying rate limits. Higher tiers typically come with higher limits, allowing providers to monetize their services by offering enhanced access to clients who require greater scale or reliability. Understanding this commercial aspect can sometimes open doors for negotiating higher limits when your business truly needs them.
1.3. Common Rate Limiting Algorithms and Their Implications
The method an API provider chooses to implement rate limiting significantly impacts how a client should respond. Different algorithms have distinct characteristics, affecting reset windows, burst capacity, and overall fairness. Understanding these nuances is crucial for predicting behavior and designing intelligent retry logic.
- Fixed Window Counter:
- Mechanism: This is the simplest method. The API gateway tracks the number of requests within a fixed time window (e.g., 60 seconds). Once the window starts, a counter increments with each request. If the counter exceeds the limit before the window ends, subsequent requests are blocked until the next window begins.
- Implications for Clients: This method is prone to "burst" problems. If clients make many requests just before a window resets, and then many more immediately after, they can effectively double their request rate across the window boundary, potentially overwhelming the API briefly. Clients need to be wary of window resets and distribute requests evenly.
- Sliding Window Log:
- Mechanism: Instead of a single counter, this algorithm stores a timestamp for every request made by a client. When a new request arrives, the system counts how many timestamps fall within the defined window (e.g., the last 60 seconds). If this count exceeds the limit, the request is denied. Old timestamps are eventually purged.
- Implications for Clients: This is more accurate and generally fairer than the fixed window, as it avoids the "burst" issue around window boundaries. However, it requires more memory to store all timestamps. Clients still need to space out their requests, but they don't have to worry as much about hitting a "reset" sweet spot.
- Sliding Window Counter:
- Mechanism: This offers a compromise between the simplicity of the fixed window and the accuracy of the sliding window log. It divides the time window into smaller sub-windows (e.g., 60-second window divided into 1-second sub-windows). It then estimates the current request rate by combining the request count from the current sub-window with a weighted average of past sub-windows.
- Implications for Clients: This approach offers better distribution than fixed windows and is more resource-efficient than sliding window logs. Clients will find their requests throttled more smoothly if they exceed limits, making predictable pacing a good strategy.
- Leaky Bucket:
- Mechanism: Visualize a bucket with a hole in the bottom. Incoming requests are like water filling the bucket. The water "leaks" out at a constant rate, representing the allowed processing rate. If requests come in faster than they can leak out, the bucket fills up. If the bucket overflows, new requests are dropped (denied).
- Implications for Clients: This algorithm ensures a constant output rate, smoothing out bursts. Clients should view this as a system that processes requests at a steady pace. Rapid bursts will quickly fill the bucket, leading to denials. The key is to maintain a steady, predictable flow of requests.
- Token Bucket:
- Mechanism: This algorithm maintains a "bucket" of tokens. Tokens are added to the bucket at a fixed rate. Each API request consumes one token. If a request arrives and there are no tokens in the bucket, the request is denied or queued. The bucket has a maximum capacity, preventing an infinite buildup of unused tokens.
- Implications for Clients: This is highly flexible. It allows for bursts (as long as there are tokens in the bucket) but then enforces a steady rate once tokens are depleted. Clients can make a few rapid calls, but then must wait for tokens to replenish. This is often preferred by providers as it allows for some flexibility while still ensuring overall rate control.
Table 1: Comparison of Common API Rate Limiting Algorithms from a Client Perspective
| Algorithm | Burst Tolerance | Fairness Across Time | Memory Usage | Implementation Complexity | Client Strategy Implication |
|---|---|---|---|---|---|
| Fixed Window Counter | High (at reset) | Poor (edge case) | Low | Low | Avoid bursts near window boundaries; distribute requests evenly. |
| Sliding Window Log | Moderate | High | High | High | Maintain steady request pace; less concern about window resets. |
| Sliding Window Counter | Moderate | Good | Moderate | Moderate | Similar to sliding log, focus on consistent pacing. |
| Leaky Bucket | Low | High | Low | Moderate | Strict pacing required; bursts will quickly lead to denials. |
| Token Bucket | High (initially) | Good | Low | Moderate | Allows for initial bursts; then requires steady pace until tokens replenish. |
1.4. Identifying Rate Limit Responses: The Signals
When an API consumer hits a rate limit, the API provider typically signals this through specific HTTP response codes and headers. Recognizing these signals programmatically is crucial for implementing effective retry and backoff strategies.
- HTTP Status Code
429 Too Many Requests: This is the standard, most common HTTP status code indicating that the user has sent too many requests in a given amount of time. Your application should always be prepared to catch and handle this specific response code. - Response Headers: Many APIs include custom or standard headers to provide more detailed information about the rate limit status:
X-RateLimit-Limit: The total number of requests allowed in the current time window.X-RateLimit-Remaining: The number of requests remaining in the current time window.X-RateLimit-Reset: The timestamp (often in Unix epoch seconds) when the current rate limit window will reset. This is the most critical piece of information, telling your application exactly when it can safely retry requests.Retry-After: A standard HTTP header that specifies how long the client should wait before making a new request. This value can be in seconds (e.g.,Retry-After: 60) or a specific date/time (e.g.,Retry-After: Tue, 01 Jan 2030 14:00:00 GMT). Always prioritizeRetry-Afterif present, as it's a direct instruction from the server.
- Custom Error Messages: Some APIs might also include specific JSON or XML error bodies with more verbose messages explaining the rate limit violation. While useful for debugging, programmatic handling should primarily rely on status codes and standard headers.
By thoroughly understanding these foundational elements, developers can move beyond simple trial-and-error, building intelligent API clients that proactively manage their request patterns and gracefully recover from rate limit encounters. This deep understanding forms the bedrock for all the advanced strategies we will explore.
2. Fundamental Client-Side Strategies for Respecting and Managing Rate Limits
Once the mechanics of API rate limiting are understood, the next crucial step involves implementing robust client-side strategies. These are the front-line defenses and proactive measures that your application can take to minimize rate limit hits, recover gracefully, and ensure continuous operation. These strategies focus on intelligent request management rather than overwhelming the API.
2.1. Implementing Robust Error Handling for Rate Limits
The most basic yet critical client-side strategy is to anticipate and correctly handle 429 Too Many Requests responses. Simply allowing the application to crash or display a generic error is unacceptable for a production-ready system.
- Catching
429Errors: Your API client code must explicitly check for and react to the HTTP status code429. This often involves wrapping API calls intry-catchblocks or using higher-order functions in asynchronous programming paradigms that specifically look for this status. The moment a429is received, your application should immediately cease sending further requests to that specific endpoint or API for a period. - Understanding and Parsing Rate Limit Headers: As discussed, the
X-RateLimit-Limit,X-RateLimit-Remaining, and especiallyX-RateLimit-Resetheaders (orRetry-After) are invaluable. Your error handling logic should extract these values.X-RateLimit-Reset(orRetry-After) tells you exactly when to retry. If it's a Unix timestamp, convert it to a local date-time and calculate the sleep duration. If it'sRetry-Afterin seconds, use that directly.- Failing to parse these headers means guessing the wait time, which can lead to either waiting too long (wasting time) or not waiting long enough (hitting the limit again, potentially getting a longer penalty).
Example Implementation Sketch (Conceptual Python): ```python import requests import time from datetime import datetimedef make_api_request(url, headers=None, data=None, max_retries=5): for attempt in range(max_retries): response = requests.get(url, headers=headers, json=data)
if response.status_code == 429:
print(f"Rate limit hit! Attempt {attempt+1}/{max_retries}")
retry_after = response.headers.get('Retry-After')
x_ratelimit_reset = response.headers.get('X-RateLimit-Reset')
wait_time = 0
if retry_after:
try:
wait_time = int(retry_after)
print(f"Waiting for {wait_time} seconds as per Retry-After header.")
except ValueError:
# Handle date format for Retry-After if necessary
print(f"Could not parse Retry-After: {retry_after}")
wait_time = 60 # Fallback
elif x_ratelimit_reset:
try:
reset_time_unix = int(x_ratelimit_reset)
current_time_unix = int(time.time())
wait_time = max(0, reset_time_unix - current_time_unix) + 1 # Add a buffer
print(f"Waiting until {datetime.fromtimestamp(reset_time_unix)} (approx {wait_time}s).")
except ValueError:
print(f"Could not parse X-RateLimit-Reset: {x_ratelimit_reset}")
wait_time = (2 ** attempt) * 10 # Exponential backoff fallback
else:
# Fallback to exponential backoff if no specific headers are provided
wait_time = (2 ** attempt) * 10 # Example: 10, 20, 40, 80... seconds
print(f"No explicit retry info. Using exponential backoff: {wait_time}s.")
time.sleep(wait_time)
continue # Retry the request after waiting
elif response.status_code == 200:
return response.json() # Success
else:
print(f"API Error: {response.status_code} - {response.text}")
return None # Other errors
print("Max retries reached. Request failed.")
return None
```
2.2. Backoff and Retry Mechanisms
Simply waiting and retrying immediately is often insufficient and can exacerbate the problem. Sophisticated retry strategies, often coupled with "backoff," are essential for respectful API consumption.
- Exponential Backoff: This is the gold standard for retry logic. When a request fails (e.g., with a
429or a5xxserver error), the client waits for an increasingly longer period before retrying.- Mechanism: The wait time typically doubles with each successive failed attempt. For example, if the first retry waits 1 second, the second waits 2 seconds, the third 4 seconds, and so on. This prevents hammering the API during periods of high load or when limits are actively being hit.
- The Importance of Jitter: Pure exponential backoff can still lead to "thundering herd" problems if many clients independently retry at the exact same exponentially increasing intervals after a widespread API outage. Jitter introduces a small, random delay (e.g., within 50% of the calculated wait time) to the backoff period. This randomness spreads out retry attempts, reducing contention and improving the chances of success for all clients. Instead of waiting exactly
2^nseconds, you might wait anywhere between0.5 * 2^nand1.5 * 2^nseconds. - Max Retries and Circuit Breakers: Always define a maximum number of retries. Beyond this, the request should be considered failed, and appropriate action should be taken (e.g., logging an error, notifying an operator, or gracefully degrading functionality). A "circuit breaker" pattern can further enhance resilience by temporarily preventing further requests to a failing API endpoint once a certain error threshold is crossed, allowing it to recover before new requests are sent.
- Linear Backoff: A simpler alternative where the wait time increases by a fixed amount with each retry (e.g., 5 seconds, then 10, then 15). Less effective than exponential for widely varying load conditions but can be suitable for predictable short-term congestion.
- Fixed Backoff: The simplest, least effective method, where the client waits for a constant period before each retry. Only appropriate for very specific, low-concurrency scenarios or when combined with explicit
Retry-Afterheaders.
Implementing a well-tuned exponential backoff with jitter is often the most significant immediate improvement you can make to your API client's resilience against rate limits.
2.3. Client-Side Caching: Reducing Unnecessary API Calls
One of the most effective ways to circumvent rate limits is to simply make fewer requests. Client-side caching plays a pivotal role here by storing responses to frequently accessed or relatively static API data locally, thereby avoiding repeat calls.
- When to Cache and What to Cache:
- Static Data: Data that rarely changes (e.g., a list of countries, product categories, configuration settings).
- Frequently Accessed Data: Information that many users or parts of your application repeatedly request (e.g., user profiles that are displayed across multiple pages).
- Idempotent GET Requests: Caching is best suited for read-only
GETrequests where the response is predictable and doesn't change based on side effects.
- Cache Invalidation Strategies: The biggest challenge with caching is ensuring data freshness.
- Time-to-Live (TTL): Data expires after a set period. Simple and effective for data that can tolerate some staleness.
- Event-Driven Invalidation: The API provider (or your own backend, if applicable) sends an event (e.g., a webhook) when data changes, triggering your client to invalidate or refresh its cache. This is more complex but ensures immediate consistency.
- Cache-Aside Pattern: Your application first checks the cache. If data is present and valid, it uses it. If not, it fetches from the API, stores the new data in the cache, and then returns it.
- Impact on Reducing API Calls: By serving cached data, your application reduces the number of requests sent to the external API, directly lowering your consumption against the rate limit. This not only helps with rate limits but also improves your application's response time and reduces network traffic. Caching should be an integral part of any high-volume API consumer design.
2.4. Batching Requests (Where Supported)
Some APIs offer specific endpoints or mechanisms for batching multiple operations into a single request. This is a powerful optimization if available.
- Combining Multiple Operations: Instead of making
Nindividual requests forNpieces of data orNsmall updates, a batch API call allows you to send allNoperations in one go. The server processes them and returns a single response, often containing the results for each sub-operation. - API Design Considerations: Not all APIs support batching, as it requires specific server-side implementation. Consult the API documentation to see if this feature is available. Common examples include bulk user updates, retrieving multiple product details, or sending multiple notifications.
- Reducing Round Trips: Batching significantly reduces the number of HTTP requests (round trips) made, which not only saves on rate limit counts but also reduces network latency and overhead. If an API counts a batch request as one call regardless of the number of operations it contains, this offers a direct and highly effective way to stretch your rate limit.
2.5. Optimizing Request Frequency and Size
Beyond caching and batching, fundamental optimization of your request patterns can significantly circumvent rate limit issues.
- Only Request Necessary Data: Avoid
SELECT *if you only need a few fields. Many APIs allow specifying fields to include in the response (e.g.,?fields=name,email). Smaller responses mean less network bandwidth and less processing for both your application and the API server. While this doesn't directly reduce the number of requests, it often leads to faster responses, which can free up your client to make the next request sooner. - Pagination Strategies: When retrieving large datasets, always use pagination if the API supports it. Fetching thousands of records in a single request is inefficient and often forbidden. Instead, request data in smaller, manageable chunks (e.g.,
?page=1&limit=100). This ensures that no single request is excessively large and allows your application to process data incrementally, rather than waiting for one massive response. - Webhooks vs. Polling:
- Polling: Your application repeatedly checks an API endpoint at fixed intervals to see if new data or status updates are available. This is inefficient, often leads to many unnecessary requests, and is a common cause of hitting rate limits.
- Webhooks: The API provider proactively notifies your application (by making an HTTP POST request to a URL you provide) whenever a relevant event occurs (e.g., data updated, payment processed). This "push" mechanism eliminates the need for constant polling, drastically reducing API calls and ensuring real-time updates. If an API supports webhooks, prioritize them over polling for event-driven data.
2.6. Distributing Workloads Across Multiple Clients/IPs (Advanced and Cautionary)
This strategy involves more advanced infrastructure and should be approached with caution and a clear understanding of the API provider's terms of service. It's often used in scenarios requiring very high throughput.
- Proxy Rotation and IP Pools: Some APIs rate limit based on IP address. By routing requests through a pool of rotating proxy servers with different IP addresses, an application can appear as multiple distinct clients, each potentially having its own rate limit bucket.
- Ethical Considerations: This practice can often be seen as an attempt to evade rate limits and might violate the API provider's terms of service. Providers can detect and block such behavior (e.g., by analyzing user-agent strings, request patterns, or through CAPTCHAs).
- Risks and Benefits: While it offers potential for higher throughput, the risk of getting your access blocked or your API keys revoked is substantial. It also adds significant complexity to your infrastructure and operational overhead. Only consider this for very specific, high-volume legitimate use cases, and ideally, only after explicit approval or discussion with the API provider.
- Using Multiple API Keys/Service Accounts: If an API's rate limits are per-API key, an organization might use multiple legitimate API keys, each associated with a different application or service account, to distribute requests. This is generally more acceptable than IP rotation if the provider's policy allows multiple keys for a single organization.
- Management Overhead: Managing and rotating multiple API keys adds complexity, especially in terms of security and access control. A robust API gateway or secret management system would be essential here.
These fundamental client-side strategies form the bedrock of responsible and effective API consumption. By diligently implementing these techniques, applications can significantly reduce their footprint on external APIs, stay within their allocated rate limits, and maintain high levels of performance and reliability.
3. Leveraging API Gateways and Infrastructure for Advanced Rate Limit Management
While client-side strategies are crucial, modern, large-scale applications often require more sophisticated, centralized approaches to manage API interactions, especially concerning rate limits. This is where API gateways and other infrastructure-level solutions come into play, offering powerful tools for traffic shaping, orchestration, and resilience.
3.1. The Role of an API Gateway in Rate Limit Management
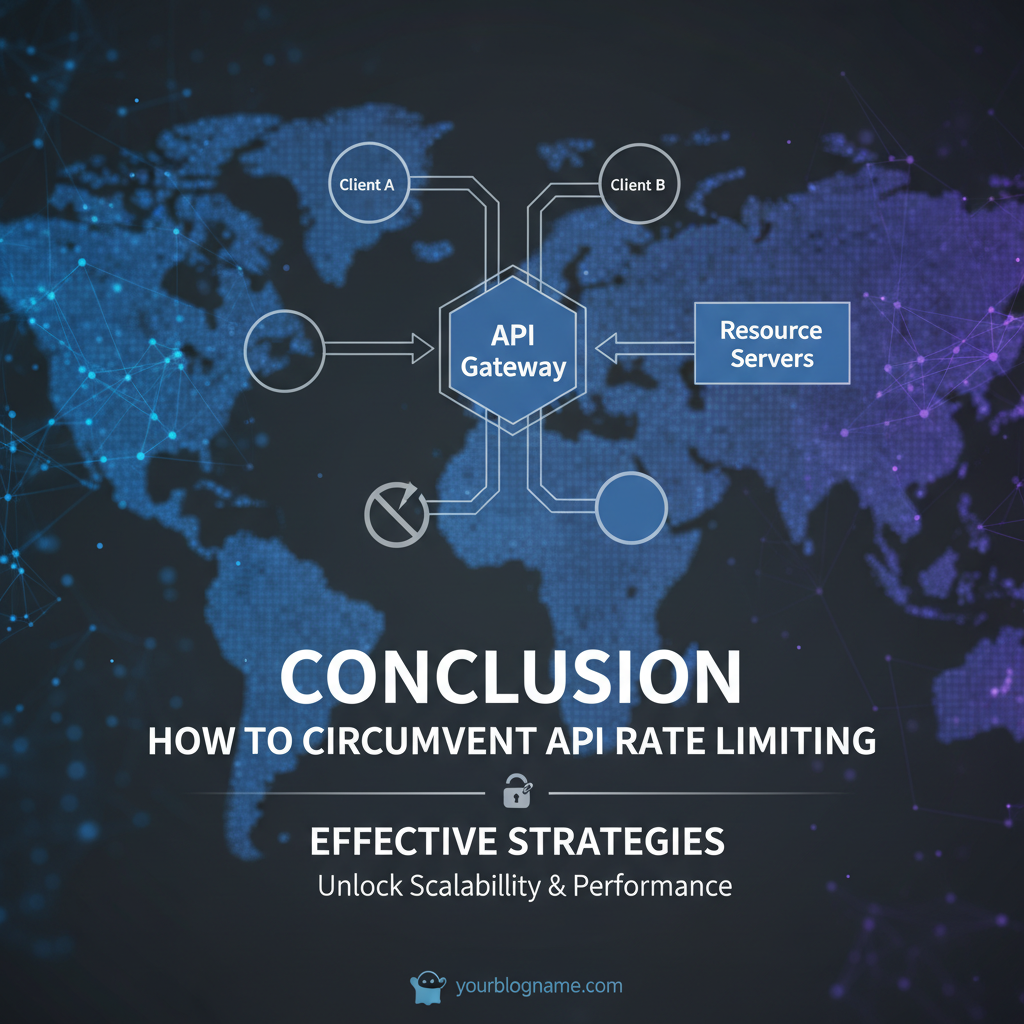
An API gateway is a critical component in many microservices architectures and enterprise API ecosystems. It acts as a single entry point for all client requests, routing them to the appropriate backend services. More importantly, it provides a centralized location to enforce cross-cutting concerns, including rate limiting.
- Centralized Traffic Management: An API gateway sits between clients and backend APIs, allowing all incoming and outgoing traffic to be monitored and controlled from a single point. This centralization is invaluable for applying consistent rate limiting policies.
- Rate Limiting Enforcement (Provider Side): For API providers, the API gateway is the primary mechanism for enforcing rate limits. It can apply different policies based on client identity (e.g., API key, IP address, user token), endpoint, or service tier. This ensures that their infrastructure is protected and fair usage is maintained for all consumers. The gateway can implement any of the algorithms discussed earlier (Fixed Window, Token Bucket, etc.).
- Traffic Shaping and Throttling: Beyond simple denials, a sophisticated API gateway can queue requests, introduce artificial delays, or prioritize certain types of traffic to smooth out bursts and prevent backend services from being overwhelmed. This traffic shaping can be crucial during peak loads.
- Authentication and Authorization: Before even considering rate limits, an API gateway can handle authentication and authorization, ensuring that only legitimate and authorized clients consume resources, thereby preventing abuse that might otherwise contribute to rate limit pressure.
- From a Consumer's Perspective (Internal Gateway): While primarily used by providers, a consumer organization can also deploy an internal API gateway or a proxy. This internal gateway can act as a single point for all outbound API calls from various internal microservices to external APIs.
- It can implement its own rate limiting logic (e.g., a token bucket) to ensure that the collective calls from all internal services to a particular external API do not exceed the external API's rate limit.
- It can manage API keys, implement centralized caching, and provide robust retry mechanisms for all external calls, abstracting these complexities away from individual microservices. This is particularly valuable in complex architectures where many services might depend on the same external API.
3.2. Client-Side API Gateways/Proxies for Rate Limit Orchestration and AI Management
Extending the concept of an internal gateway, specialized client-side API gateways or sophisticated proxies can be deployed within a consumer's infrastructure specifically to orchestrate and manage their outbound API calls, especially when dealing with numerous external dependencies or complex integration patterns. This approach centralizes the logic for API interaction, making it far easier to manage rate limits.
Imagine an organization integrating with dozens of external APIs, including various AI models, payment processors, and data providers. Each of these APIs will have its own rate limits, authentication schemes, and data formats. Manually managing this in every microservice quickly becomes an operational nightmare.
This is precisely where platforms like APIPark come into their own. APIPark is an open-source AI gateway and API management platform designed to help developers and enterprises manage, integrate, and deploy AI and REST services with ease. By sitting in front of your applications, it can:
- Unify API Formats and Simplify AI Invocation: APIPark standardizes the request data format across different AI models, abstracting away their unique quirks. This means your application always sends a consistent request, and APIPark handles the translation. This standardization inherently helps manage rate limits by optimizing the request process, ensuring that applications are sending precisely what's needed in the correct format, thus reducing malformed or inefficient calls that might contribute to hitting limits faster.
- Centralized Rate Limit Enforcement (Outbound): While APIPark serves as an AI gateway, it can also act as an intelligent proxy for your outbound calls. It can implement its own rate limiting policies, ensuring that the aggregate traffic from your internal services to an external API (especially for frequently invoked AI models) stays within the provider's limits. Instead of each microservice trying to manage its share of the limit, APIPark can act as the single traffic cop.
- Lifecycle Management and Traffic Forwarding: APIPark assists with managing the entire lifecycle of APIs, including design, publication, invocation, and decommission. It helps regulate API management processes, manage traffic forwarding, load balancing, and versioning of published APIs. This comprehensive control allows for smarter routing and throttling decisions, which are directly beneficial for rate limit management. For example, if one external AI service is being rate-limited, APIPark could be configured to temporarily route requests to an alternative service if available, or queue them intelligently until the limit resets.
- Performance and Scalability: With performance rivaling Nginx, APIPark can handle over 20,000 TPS on modest hardware and supports cluster deployment. This robust performance means it won't become a bottleneck itself when managing high volumes of outbound API calls, ensuring that your rate limit circumvention strategy doesn't introduce new performance problems. Its detailed API call logging and powerful data analysis features also provide invaluable insights into your usage patterns, helping you identify bottlenecks and optimize your calls before you even hit a rate limit.
Utilizing a platform like ApiPark as a sophisticated client-side gateway transforms rate limit management from a decentralized, error-prone task spread across many microservices into a centralized, intelligent, and observable process. It allows your developers to focus on business logic, confident that the complexities of external API integration, including rate limits, are being expertly handled by a dedicated platform.
3.3. Horizontal Scaling of Consumers
For applications that need to process a truly massive volume of requests, simply optimizing a single client might not be enough. Scaling your own application horizontally can help, but it comes with its own set of challenges regarding shared rate limits.
- Distributing Requests Across Multiple Instances: If your application is deployed as multiple instances (e.g., in a container orchestration platform like Kubernetes), each instance will ideally run its own API client logic. This distributes the load and increases processing capacity.
- Challenges with Shared Rate Limits: The problem arises if the external API's rate limit is tied to a single API key or a single user account. In this scenario, all your horizontally scaled instances are competing for the same bucket of requests. Without coordination, they will collectively hit the rate limit much faster.
- Solutions: Centralized Rate Limit Management: To overcome this, you need a shared, distributed rate limiter within your own infrastructure. This could be a centralized Redis instance or a dedicated service that all your application instances consult before making an external API call. This central service acts as a "token bucket" for your entire application, distributing the allowed requests among its various instances and ensuring the collective limit is not exceeded. This is another area where a sophisticated gateway or management platform could play a critical role, acting as that central coordinator.
3.4. Utilizing Service Accounts/API Keys
Many API providers offer the ability to create multiple API keys or service accounts, each with its own rate limit bucket.
- Understanding Per-Key Rate Limits: If an API documents that its rate limits are applied per API key, this presents a direct opportunity to increase your effective throughput. By generating multiple API keys and distributing them among your different application modules, microservices, or even individual users, you can multiply your available rate limit.
- Strategies for Using Multiple Keys:
- Dedicated Keys per Service: Assign a unique API key to each microservice or component of your application that interacts with the external API. This also improves auditing and security.
- Round-Robin Key Rotation: Implement a simple load-balancing mechanism that cycles through a pool of API keys for outgoing requests. When one key approaches its limit, switch to another.
- Dynamic Key Assignment: Monitor the
X-RateLimit-Remainingheader for each key and dynamically route requests to the key with the most remaining capacity.
- Management Considerations: Managing many API keys requires a robust secret management system. Keys should never be hardcoded and should be securely stored and rotated. A dedicated API gateway can help manage this pool of keys and handle the rotation logic transparently.
3.5. Advanced Load Balancing and Traffic Management
While commonly associated with inbound traffic to your services, advanced load balancing principles can also be applied to outbound API calls for better rate limit management.
- DNS-based Load Balancing (for multiple API endpoints): If an API provider offers geographically distributed endpoints or multiple hostnames, you could use DNS-based strategies to route your requests to the closest or least-loaded endpoint, potentially benefiting from different regional rate limit pools or reduced latency.
- Application-level Load Balancing (Outbound): Similar to using multiple API keys, if an external service has multiple, independent endpoints (e.g., different regional instances that are rate-limited independently), your application's internal load balancer could distribute requests across these endpoints.
- Geo-distributed Requests: For global applications, routing API calls from application instances in different geographic regions to the closest corresponding regional API endpoint can reduce latency and might tap into separate, regionally enforced rate limits, effectively increasing your global throughput.
These infrastructure-level strategies demand a higher degree of architectural planning and implementation complexity but offer the most robust and scalable solutions for managing high-volume API consumption and effectively circumventing rate limits without violating API provider policies. They shift the burden of rate limit management from individual developers to a centralized, managed layer.
APIPark is a high-performance AI gateway that allows you to securely access the most comprehensive LLM APIs globally on the APIPark platform, including OpenAI, Anthropic, Mistral, Llama2, Google Gemini, and more.Try APIPark now! 👇👇👇
4. Proactive Communication and Partnership with API Providers
Beyond technical strategies, one of the most often overlooked yet highly effective ways to manage API rate limits is through direct engagement and proactive communication with the API providers themselves. This fosters a partnership approach that can yield custom solutions and prevent unforeseen disruptions.
4.1. Understanding API Documentation: The First Line of Defense
Before even writing a single line of code, developers must thoroughly review the API documentation. This isn't just about understanding endpoints and data formats; it's crucially about grasping the provider's expectations and limitations.
- Explicit Rate Limit Policies: Most reputable API providers clearly document their rate limit policies, including the number of requests per time window, the specific headers they use for reporting remaining limits, and the expected behavior upon hitting a limit (e.g.,
429status code,Retry-Afterheader). This documentation is your primary source of truth. Deviating from documented best practices is an invitation for trouble. - Best Practices and Recommended Usage Patterns: Beyond explicit limits, documentation often includes recommended usage patterns, such as preferred caching strategies, optimal batch sizes, and whether webhooks are available. Adhering to these recommendations can significantly reduce your consumption footprint and signal to the provider that you are a responsible consumer. For example, if an API suggests polling no more frequently than once every 5 minutes, and you poll every 10 seconds, you are actively working against the provider's stated intent.
- Version Control and Deprecation Notices: Staying informed about API version changes and deprecation notices is vital. New versions might introduce different rate limits or new features (like batching or webhooks) that could help you manage limits more effectively. Neglecting these updates can lead to unexpected errors or reduced functionality.
4.2. Contacting API Support for Higher Limits: Making Your Case
If your application genuinely requires a higher throughput than the default rate limits allow, the most direct approach is to formally request an increase from the API provider. This isn't a guaranteed success, but a well-reasoned request significantly increases your chances.
- Justification for Increased Limits (Use Case, Business Value): Don't just ask for more; explain why. Clearly articulate your use case, describing your application's functionality, its user base, and the business value it creates for both you and, indirectly, for the API provider. Quantify your current and projected API usage. For example, "Our e-commerce platform processes 10,000 orders per day, each requiring two calls to your payment API. Our current limit of 50 requests per second is insufficient during peak checkout times, leading to abandoned carts. Increasing our limit to 100 requests per second would allow us to maintain a smooth customer experience and grow our business, translating to increased transaction volume for your service."
- Providing Usage Patterns and Technical Details: Share details about your current API consumption, including your average request rate, peak request rate, and how you are currently handling rate limit errors (e.g., with exponential backoff). Demonstrate that you are already using best practices and that an increase is a genuine necessity, not a substitute for poor client design. This shows you are a responsible and technically proficient consumer.
- Negotiating Custom Tiers or Service Level Agreements (SLAs): For critical business operations, you might be able to negotiate a custom service tier with dedicated limits or a specific Service Level Agreement (SLA) that guarantees a certain throughput. This often comes with a higher cost but provides essential peace of mind and operational stability. Be prepared to discuss commercial terms.
4.3. Exploring Enterprise/Paid Tiers: When to Invest
Many API providers structure their offerings into free, paid, and enterprise tiers, with rate limits being a primary differentiator.
- Understanding the Value Proposition: Evaluate whether upgrading to a paid or enterprise tier makes financial and operational sense. Higher tiers typically offer:
- Significantly Higher Rate Limits: Often orders of magnitude greater than free tiers.
- Dedicated Support: Faster response times for issues, including rate limit concerns.
- Advanced Features: Access to batch APIs, webhooks, or dedicated endpoints not available in lower tiers.
- Improved SLAs: Guarantees on uptime and performance.
- Cost-Benefit Analysis: Weigh the cost of upgrading against the benefits. What is the financial impact of hitting rate limits (e.g., lost revenue from failed transactions, degraded user experience, operational overhead of retries)? What is the cost of implementing complex internal rate limit management systems? Often, paying for a higher tier from a reputable provider is more cost-effective and reliable than trying to circumvent strict free-tier limits with elaborate technical workarounds.
4.4. Designing for Scalability and Resilience from the Outset
While not directly about communication, adopting a resilient design philosophy from the project's inception naturally leads to better API rate limit management and can simplify conversations with providers.
- Architectural Considerations: Design your application with external dependencies in mind.
- Decoupling Services: Avoid tight coupling between your core business logic and external API calls. Use message queues or event buses to process API calls asynchronously. If an external API becomes unavailable or starts rate-limiting, your core application can continue functioning by queuing requests for later processing.
- Event-Driven Architectures: Embrace event-driven patterns where your application reacts to events (like a successful API call or a rate limit notification) rather than constantly polling. This reduces the number of speculative API calls.
- Building Redundancy: For mission-critical functions, consider building redundancy by integrating with multiple API providers for the same service (e.g., two different payment APIs). If one provider enforces strict limits or experiences downtime, you can failover to the other.
By engaging proactively, transparently, and strategically with API providers, organizations can often unlock higher limits, gain access to better support, and secure more stable API access, ultimately achieving their desired throughput without resorting to overly complex or potentially unethical circumvention tactics.
5. Ethical Considerations and Best Practices for API Consumption
Successfully navigating API rate limits goes beyond mere technical implementation; it extends into the realm of ethical responsibility and good citizenship within the API ecosystem. A balanced approach respects the provider's infrastructure while ensuring your application's reliability.
5.1. Respecting API Terms of Service
The terms of service (ToS) for an API are not just legal boilerplate; they are a critical document outlining the rules of engagement. Ignoring them can lead to severe consequences, including account suspension or legal action.
- Avoiding Practices that Violate Terms: Many ToS explicitly prohibit activities that could be considered abusive, such as:
- Bot Activity: Using automated scripts to perform actions typically reserved for human users in a way that generates excessive traffic or bypasses security measures.
- Excessive Scraping: Aggressively extracting large volumes of data without explicit permission, especially if it negatively impacts service performance for others.
- Bypassing Rate Limits: Attempts to intentionally circumvent rate limit enforcement mechanisms (e.g., through IP rotation without consent, creating numerous fake accounts) are usually prohibited.
- Misrepresentation: Falsifying user-agent strings or other identification headers to hide your identity or impersonate legitimate clients.
- Understanding the Provider's Perspective: Always consider the API provider's perspective. They invest significant resources in building and maintaining their API. Your actions directly impact their operational costs, system stability, and the experience of their other users. Responsible API consumption contributes to a healthy ecosystem for everyone. When you respect their terms, you're more likely to receive support and potentially even get higher limits when needed.
5.2. Graceful Degradation: Maintaining User Experience Under Duress
Even with the best rate limit management strategies, there will be times when external APIs are unavailable, experience high latency, or enforce stricter-than-expected limits. Designing for graceful degradation is about ensuring your application remains functional, albeit with reduced capabilities, rather than completely failing.
- What Happens When Limits Are Hit? Plan for the worst-case scenario. If a critical API dependency becomes unresponsive due to rate limits:
- Non-Essential Features: Can certain features be temporarily disabled or offer reduced functionality? For example, if a weather API is limited, show cached weather data or a general message instead of a blank screen.
- Delayed Processing: Can requests be queued for later processing once the API becomes available? This is crucial for non-real-time operations. Use message queues to temporarily store requests that couldn't be processed due to rate limits.
- Fallbacks: Implement fallback data or default behaviors. If a content recommendation API is down, simply show popular items or a generic list instead of personalized recommendations.
- Providing Fallback Experiences for Users: Communicate clearly and transparently with your users. Instead of a cryptic error message, inform them that a particular feature is temporarily unavailable or experiencing delays. "We're currently experiencing high demand for our analytics features. Please try again in a few moments." This manages user expectations and prevents frustration.
- Circuit Breakers: Implement the circuit breaker pattern. If an API consistently fails or hits rate limits for a period, the circuit breaker "trips," preventing further calls to that API endpoint. This gives the API time to recover and prevents your application from wasting resources on doomed requests. After a set period, the circuit breaker enters a "half-open" state, allowing a few test requests to see if the API has recovered.
5.3. Monitoring and Alerting: Early Detection is Key
Effective rate limit management requires proactive monitoring. You can't fix what you don't know is broken or about to break.
- Tracking API Usage and Remaining Limits: Instrument your API client code to log and report key metrics:
- Total requests made to each external API.
- Number of
429responses received. - Parsed values of
X-RateLimit-RemainingandX-RateLimit-Resetheaders. - Average and peak request latency.
- Success rate of API calls.
- Setting Up Alerts for Approaching Limits: Configure monitoring systems to trigger alerts when your usage approaches predefined thresholds (e.g., 80% or 90%) of your allowed rate limit. This gives your team crucial lead time to investigate, adjust request patterns, or contact the API provider before a hard limit is hit. Alerts should be actionable and notify the right personnel (e.g., operations, development teams).
- Performance Monitoring: Beyond rate limits, monitor the overall performance of your API calls. Increased latency or error rates might indicate that the API provider is under stress, even if you haven't technically hit a
429. This early warning can allow you to proactively reduce your request rate. A comprehensive API gateway like APIPark, with its detailed API call logging and powerful data analysis, can provide these crucial insights, helping businesses with preventive maintenance before issues occur.
5.4. Security Implications: Protecting Your Credentials
Finally, the security of your API access is paramount. Compromised credentials can lead to unauthorized usage, data breaches, and rapid depletion of your rate limits.
- Protecting API Keys and Tokens:
- Never Hardcode: API keys should never be hardcoded directly into your application's source code.
- Secure Storage: Use environment variables, secret management services (e.g., HashiCorp Vault, AWS Secrets Manager, Azure Key Vault), or dedicated credential stores.
- Principle of Least Privilege: Grant API keys only the minimum necessary permissions.
- Regular Rotation: Periodically rotate your API keys to mitigate the impact of potential compromises.
- Input Validation: Ensure that any user-provided data sent to an API is thoroughly validated to prevent injection attacks or malformed requests that could trigger unexpected behavior or consume unnecessary rate limit capacity.
- Preventing Denial-of-Service Attacks Against Your Application by External API Providers: While the focus is often on avoiding rate limits from the provider, it's also important to prevent an external API's rate limiting from causing a denial-of-service against your application. If your application blocks and waits indefinitely when an external API is rate-limiting, it could exhaust its own resources (e.g., thread pools, memory), leading to internal service unavailability. This highlights the importance of asynchronous API calls, non-blocking I/O, and robust error handling with timeouts and circuit breakers.
By adhering to these ethical considerations and best practices, developers can build API-consuming applications that are not only resilient and high-performing but also respectful of the broader API ecosystem, fostering a sustainable relationship with API providers. This holistic approach ensures long-term success in the dynamic world of interconnected services.
Conclusion: Mastering the Art of API Rate Limit Navigation
Navigating the intricate world of API rate limits is a crucial skill for any developer or organization operating in today's interconnected digital landscape. It's a delicate balance between maximizing the utility of external services and respecting the infrastructure and policies of API providers. As we have meticulously explored, circumventing rate limits is not about breaking rules, but rather about deploying a multi-faceted strategy built on understanding, intelligence, and proactive design.
Our journey began with a deep dive into the fundamental mechanics of API rate limiting, dissecting the various algorithms from Fixed Window to Token Bucket, and learning how to interpret the critical HTTP 429 status code and accompanying X-RateLimit-* and Retry-After headers. This foundational knowledge empowers developers to not just react to limits, but to anticipate and proactively manage them.
We then moved to the essential client-side strategies: implementing robust error handling with intelligent backoff and retry mechanisms (especially exponential backoff with jitter), leveraging client-side caching to reduce unnecessary API calls, batching requests where supported, and meticulously optimizing request frequency and size through smart pagination and the judicious use of webhooks over polling. These tactics form the bedrock of a well-behaved and resilient API consumer.
The discussion then ascended to more sophisticated, infrastructure-level solutions, highlighting the pivotal role of an API gateway. Whether it's an API provider using a gateway for enforcement or an API consumer deploying an internal gateway for outbound traffic orchestration, these central components offer unparalleled control. We specifically noted how platforms like ApiPark, an open-source AI gateway and API management platform, can significantly streamline the integration and management of diverse APIs, particularly AI models, by unifying formats, centralizing request logic, and offering high-performance traffic management—all of which indirectly but powerfully contribute to effective rate limit circumvention. Horizontal scaling of consumers and the strategic use of multiple API keys further enhance an application's capacity to handle high volumes within aggregate limits.
Finally, we underscored the importance of proactive communication and partnership with API providers, emphasizing the value of understanding documentation, making well-justified requests for higher limits, and considering paid service tiers. This symbiotic relationship fosters mutual benefit and can often unlock solutions that purely technical workarounds cannot. Coupled with ethical considerations and best practices—respecting terms of service, designing for graceful degradation, implementing robust monitoring, and safeguarding API credentials—we painted a holistic picture of responsible and effective API consumption.
In essence, mastering API rate limits is an ongoing journey of continuous optimization, vigilance, and strategic planning. By integrating these effective strategies, from the simplest client-side adjustments to advanced gateway deployments and proactive provider engagement, organizations can build applications that are not only performant and scalable but also robust, resilient, and considerate of the shared resources that power our digital world.
Frequently Asked Questions (FAQs)
1. What is API rate limiting and why is it implemented?
API rate limiting is a control mechanism that restricts the number of requests a user or client can make to an API within a specific timeframe (e.g., 100 requests per minute). It is primarily implemented by API providers for several critical reasons: to protect their infrastructure from abuse like DDoS attacks or aggressive scraping, to ensure fair usage and equitable access to resources for all clients, to manage operational costs by preventing excessive resource consumption, and to maintain the stability and integrity of their backend services and data. Understanding these motivations helps developers design API clients that respect these boundaries.
2. What are the common HTTP status codes and headers to look for when hitting a rate limit?
When an API client hits a rate limit, the most common HTTP status code returned is 429 Too Many Requests. In addition to this status code, API providers often include specific response headers that provide crucial information for effective handling: * X-RateLimit-Limit: Indicates the maximum number of requests allowed in the current time window. * X-RateLimit-Remaining: Shows how many requests are still available in the current window. * X-RateLimit-Reset: Provides a Unix timestamp (or similar time unit) when the current rate limit window will reset, telling you exactly when to retry. * Retry-After: A standard HTTP header that directly specifies the minimum amount of time (in seconds or as a specific date) to wait before making another request. Always prioritize this header if present.
3. What is exponential backoff with jitter, and why is it recommended for handling rate limits?
Exponential backoff with jitter is a sophisticated retry mechanism. When an API request fails (e.g., due to a 429 error), the client waits for an increasingly longer period before making the next retry attempt, typically doubling the wait time with each successive failure. "Jitter" introduces a small, random variation to this calculated wait time. This strategy is highly recommended because it: * Reduces Server Load: Prevents your application from hammering an already overloaded or rate-limited API. * Improves Success Rates: Allows the API provider's systems to recover, increasing the likelihood of successful retries. * Prevents "Thundering Herd" Problems: Jitter helps distribute retries over time, avoiding situations where many clients retry simultaneously after an API issue, which could re-overwhelm the service.
4. How can an API Gateway help in managing API rate limits, both for providers and consumers?
An API gateway plays a central role in rate limit management. * For API Providers: It acts as the primary enforcement point, applying rate limiting policies (e.g., using algorithms like token bucket or fixed window) based on client identity, API key, or subscription tier. This protects backend services and ensures fair usage. * For API Consumers (Internal Gateway/Proxy): An organization can deploy an internal API gateway to manage its outbound calls to external APIs. This gateway can centralize rate limit logic for all internal services (e.g., ensuring the collective calls don't exceed an external API's limit), manage API keys, implement caching, and provide robust retry mechanisms. Platforms like APIPark, an AI gateway and API management platform, are examples of such solutions that can unify API access, optimize requests, and help orchestrate calls to multiple external services, thereby indirectly assisting in rate limit circumvention by improving efficiency and control.
5. What are some ethical considerations when trying to circumvent API rate limits?
While the goal is to manage rate limits effectively, it's crucial to operate ethically and respect the API provider's terms of service (ToS). Ethical considerations include: * Respecting ToS: Avoid practices explicitly prohibited by the API provider, such as aggressive data scraping, using bot activity to bypass security, or intentionally creating numerous fake accounts to multiply rate limits. * Fair Usage: Understand that API resources are shared. Excessive or abusive behavior impacts other legitimate users and increases the provider's operational costs. * Transparency: If you genuinely need higher limits, communicate openly with the API provider, explain your use case, and provide evidence of responsible usage. * Graceful Degradation: Design your application to handle API unavailability or rate limits gracefully, providing a fallback experience to your users instead of completely failing. This shows respect for your users and acknowledges the realities of external dependencies.
🚀You can securely and efficiently call the OpenAI API on APIPark in just two steps:
Step 1: Deploy the APIPark AI gateway in 5 minutes.
APIPark is developed based on Golang, offering strong product performance and low development and maintenance costs. You can deploy APIPark with a single command line.
curl -sSO https://download.apipark.com/install/quick-start.sh; bash quick-start.sh

In my experience, you can see the successful deployment interface within 5 to 10 minutes. Then, you can log in to APIPark using your account.

Step 2: Call the OpenAI API.