Master Asynchronous Sending to Two APIs


In the intricate tapestry of modern software architecture, APIs serve as the crucial threads that connect disparate services, allowing them to communicate, exchange data, and collaborate to deliver complex functionalities. From microservices orchestrating a user's e-commerce transaction to large enterprise systems synchronizing data across various departments, the ability to interact with external and internal services via their programmatic interfaces is fundamental. However, as systems grow in complexity and user expectations for responsiveness skyrocket, simply making an API call often isn't enough. The challenge intensifies when a single logical operation within your application necessitates interacting with not one, but two or more distinct APIs. This scenario, common in data synchronization, notification systems, and distributed transactions, introduces a unique set of performance, resilience, and consistency concerns.
Consider a retail application where a user places an order. This seemingly simple action might trigger a cascade of API calls: one to a payment gateway to process the transaction, another to an inventory management system to reserve stock, and perhaps a third to a customer relationship management (CRM) system to update purchase history or send a confirmation email. If these calls are made sequentially, or "synchronously," the entire process is bottlenecked by the slowest API call. A delay in the inventory system, for instance, could leave the user staring at a loading spinner, potentially leading to frustration and abandonment. Furthermore, a failure in one of these critical steps could leave the system in an inconsistent state, where the payment is processed but inventory isn't updated, or vice-versa.
This is where the mastery of asynchronous sending becomes not just an optimization, but a necessity. Asynchronous programming allows your application to initiate an operation, such as an API call, and then immediately move on to other tasks without waiting for the operation to complete. The completion (or failure) is handled at a later point, often via callbacks, promises, or messages. When dealing with two APIs, this paradigm allows you to initiate calls to both simultaneously, or in a non-blocking fashion, dramatically improving perceived performance and system throughput. Moreover, it provides robust mechanisms for handling failures, retries, and ensuring data consistency across distributed boundaries. This comprehensive guide delves deep into the principles, patterns, and practical considerations for effectively mastering asynchronous sending to two APIs, equipping you with the knowledge to build highly performant, resilient, and scalable distributed systems. We will explore various programming models, architectural patterns, and crucial considerations like error handling and idempotency, ultimately highlighting how judicious use of an API Gateway can further simplify and secure these complex interactions.
The Landscape of API Integration: Synchronous vs. Asynchronous Paradigms
Before we delve into the intricacies of sending data to multiple APIs asynchronously, it's crucial to firmly grasp the distinction between synchronous and asynchronous operations, as this forms the bedrock of our discussion. Understanding their fundamental differences, advantages, and limitations is paramount for making informed architectural decisions.
Synchronous Operations: The Blocking Nature
At its core, a synchronous operation implies that a task must complete before the program can proceed to the next task. When your application makes a synchronous API call, it sends a request to the external service and then blocks its execution. This means your application thread (or process) essentially pauses, waiting actively for the external service to process the request and send back a response. Only once the response is received (or a timeout occurs) will your application resume its execution and continue with subsequent operations.
Pros: * Simplicity: Synchronous code is often easier to write and reason about initially. The flow is linear and predictable, following the familiar top-down execution model. * Direct Error Handling: Errors are typically immediate and can be handled right after the blocking call, making debugging straightforward in single-call scenarios.
Cons: * Performance Bottlenecks: This is the most significant drawback. If an API call takes 500 milliseconds, your application thread is idle for that entire duration. In a web server context, this means a worker thread is tied up, unable to serve other requests, leading to reduced throughput and increased latency for users. * Poor User Experience: For client-side applications (web or mobile), synchronous operations can freeze the user interface, creating a sluggish and frustrating experience. * Resource Inefficiency: While waiting, the thread consumes system resources without performing useful work, which can lead to inefficient resource utilization, especially under high load. * Reduced Scalability: A blocking operation limits the number of concurrent tasks a single application instance can handle, thereby impacting overall system scalability.
Asynchronous Operations: Embracing Non-Blocking Execution
In stark contrast, an asynchronous operation allows a program to initiate a task and immediately move on to other work without waiting for the task's completion. When an asynchronous API call is made, your application sends the request and then releases the current thread to perform other computations or handle other incoming requests. The actual API call is typically handled by a background mechanism (like an I/O thread pool, an event loop, or a dedicated runtime), and once the response arrives, a predefined callback function, promise, or event handler is triggered to process the result.
Pros: * Enhanced Responsiveness: Applications remain responsive, as the UI thread or main application thread is not blocked, providing a smoother user experience. * Improved Throughput and Scalability: By not blocking threads, an application can handle many more concurrent operations with fewer resources. This is particularly beneficial for I/O-bound tasks like network requests, where the majority of the time is spent waiting. * Efficient Resource Utilization: Threads are used more effectively, spending less time idle and more time processing. * Resilience: Asynchronous patterns, especially when coupled with message queues, naturally lend themselves to building more resilient systems that can handle temporary failures, retries, and back pressure more gracefully.
Cons: * Increased Complexity: Asynchronous code can be harder to write, debug, and reason about due to its non-linear flow. Managing state across asynchronous operations requires careful design. * Error Handling Challenges: Errors might occur at a later point in time or in a different execution context, making structured error handling and propagation more intricate. * Debugging Difficulties: Tracing the flow of execution through multiple callbacks or promise chains can be more challenging than following a synchronous stack trace.
Common Scenarios for Dual API Calls
The necessity of calling two APIs (or more) within a single logical workflow is ubiquitous in modern distributed systems. Understanding these common scenarios helps frame the practical application of asynchronous patterns:
- Data Replication and Synchronization:
- Scenario: A user updates their profile. This update needs to be written to a primary relational database and also indexed in a search engine (e.g., Elasticsearch) for quick retrieval.
- Challenge: Both updates must ideally reflect the latest state. Synchronously waiting for both can introduce latency. Asynchronously, one can proceed while the other is handled in the background, with mechanisms to ensure eventual consistency.
- Cross-System Updates:
- Scenario: A new order is placed in an e-commerce system. This requires updating the order status in the order management system and simultaneously deducting items from inventory in a separate inventory management system.
- Challenge: These are often transactional in nature; if one fails, the other might need to be rolled back or compensated. Asynchronous communication provides a framework for such distributed transactions (e.g., Sagas).
- Notifications and Side Effects:
- Scenario: After a user successfully registers, an API call is made to a user service to create the account. Simultaneously, another API call needs to be made to an email service to send a welcome email and yet another to an analytics service to log the registration event.
- Challenge: The user should not have to wait for the email or analytics logging. These are side effects that can occur asynchronously without blocking the primary workflow.
- Data Enrichment and Aggregation:
- Scenario: A client requests a user's detailed profile. This profile might involve fetching basic user data from one internal API and then enriching it with geographic information from a third-party mapping API.
- Challenge: Fetching data from independent sources can be done in parallel to minimize the total response time, and the results then aggregated before being returned to the client.
- A/B Testing or Shadow Mode:
- Scenario: A new version of an internal service (API B) is being rolled out, replacing an older version (API A). During a testing phase, requests are sent to both API A and API B, but only API A's response is returned to the client. API B's response is used for validation and monitoring.
- Challenge: The calls to API B must not impact the latency of the primary call to API A. Asynchronous fire-and-forget is ideal here.
In all these scenarios, the ability to initiate and manage multiple API calls without blocking the main execution path is paramount for building performant, responsive, and scalable applications. The asynchronous paradigm empowers developers to design systems that are not only faster but also more robust in the face of network latency, external service unreliability, and varying workloads.
Understanding Asynchronous Programming Paradigms
The shift from synchronous, linear execution to non-blocking, event-driven asynchronous processing requires understanding various programming paradigms. Different languages and frameworks offer distinct constructs to manage asynchronicity, each with its own advantages and learning curve.
Callbacks: The Foundation of Non-Blocking I/O
Callbacks are one of the most fundamental ways to handle asynchronous operations. In this pattern, you pass a function (the "callback") as an argument to another function that initiates an asynchronous task. When the asynchronous task completes, it invokes the provided callback function, passing along any results or errors.
Explanation: Imagine calling an API to fetch user data. Instead of waiting for the data, you tell your program, "Go fetch user data, and when you're done, call this processUserData function with the result."
// Conceptual JavaScript example
function fetchUserData(userId, callback) {
// Simulate an async API call
setTimeout(() => {
const userData = { id: userId, name: "Alice", email: "alice@example.com" };
if (Math.random() > 0.1) { // Simulate success 90% of the time
callback(null, userData); // Call callback with error (null) and data
} else {
callback(new Error("Network error"), null); // Call callback with error
}
}, 1000);
}
function processUserData(error, data) {
if (error) {
console.error("Failed to fetch user data:", error.message);
return;
}
console.log("User data received:", data);
// Now make a second async call based on this data
fetchUserOrders(data.id, processUserOrders);
}
function fetchUserOrders(userId, callback) {
// Another async call
setTimeout(() => {
const orders = [{ orderId: "123", amount: 100 }, { orderId: "456", amount: 250 }];
callback(null, orders);
}, 800);
}
function processUserOrders(error, orders) {
if (error) {
console.error("Failed to fetch user orders:", error.message);
return;
}
console.log("User orders received:", orders);
}
// Initiate the first call
fetchUserData("user123", processUserData);
console.log("Request sent, doing other things..."); // This executes immediately
"Callback Hell" Problem: While effective for simple cases, nesting multiple asynchronous operations using callbacks can quickly lead to deeply indented, difficult-to-read, and harder-to-maintain code, famously known as "callback hell" or the "pyramid of doom." Error handling also becomes cumbersome, as each callback needs to check for errors independently.
Promises/Futures: Managing Asynchronous Results
Promises (in JavaScript, TypeScript) or Futures (in Java, Scala, C#, Python) represent a significant improvement over raw callbacks for managing asynchronous operations. A Promise is an object that represents the eventual completion (or failure) of an asynchronous operation and its resulting value. It acts as a placeholder for a value that is not yet available but will be at some point.
Explanation: A Promise can be in one of three states: * Pending: Initial state, neither fulfilled nor rejected. * Fulfilled (or Resolved): The operation completed successfully, and the promise has a resulting value. * Rejected: The operation failed, and the promise has a reason for the failure (an error).
Promises allow for a more linear and readable way to chain asynchronous operations. Instead of nesting callbacks, you attach handlers (using .then() for success and .catch() for failure) to the promise.
// Conceptual JavaScript example using Promises
function fetchUserDataPromise(userId) {
return new Promise((resolve, reject) => {
setTimeout(() => {
const userData = { id: userId, name: "Alice", email: "alice@example.com" };
if (Math.random() > 0.1) {
resolve(userData); // Resolve the promise with data
} else {
reject(new Error("Network error during user data fetch")); // Reject with an error
}
}, 1000);
});
}
function fetchUserOrdersPromise(userId) {
return new Promise((resolve, reject) => {
setTimeout(() => {
const orders = [{ orderId: "123", amount: 100 }, { orderId: "456", amount: 250 }];
if (Math.random() > 0.05) { // Simulate success 95% of the time
resolve(orders);
} else {
reject(new Error("Database error during order fetch"));
}
}, 800);
});
}
// Chaining operations
fetchUserDataPromise("user123")
.then(userData => {
console.log("User data received (Promise):", userData);
return fetchUserOrdersPromise(userData.id); // Return another promise to chain
})
.then(orders => {
console.log("User orders received (Promise):", orders);
})
.catch(error => {
console.error("An error occurred in the Promise chain:", error.message);
});
console.log("Promise chain initiated, doing other things...");
Benefits of Promises: * Readability: Flatter code structure, avoids callback hell. * Chaining: Easily sequence multiple asynchronous operations. * Unified Error Handling: A single .catch() block can handle errors from any point in the chain. * Composition: Methods like Promise.all() (wait for all promises to resolve) and Promise.race() (resolve/reject as soon as one promise resolves/rejects) are incredibly powerful for managing multiple concurrent API calls.
Async/Await: Syntactic Sugar for Promises/Futures
async/await is a modern syntactic feature built on top of Promises (or Futures) that allows you to write asynchronous code that looks and behaves much like synchronous code, making it significantly more readable and easier to reason about.
Explanation: * The async keyword is placed before a function declaration to denote that the function will perform asynchronous operations and will implicitly return a Promise. * The await keyword can only be used inside an async function. It pauses the execution of the async function until the Promise it's "awaiting" resolves or rejects. While the async function is paused, the underlying event loop or thread is not blocked, allowing other tasks to proceed.
// Conceptual JavaScript example using Async/Await
async function getUserAndOrders(userId) {
try {
console.log("Fetching user data asynchronously...");
const userData = await fetchUserDataPromise(userId); // Pause here, but non-blocking
console.log("User data received (Async/Await):", userData);
console.log("Fetching user orders asynchronously...");
const orders = await fetchUserOrdersPromise(userData.id); // Pause again
console.log("User orders received (Async/Await):", orders);
return { userData, orders };
} catch (error) {
console.error("An error occurred in Async/Await function:", error.message);
throw error; // Re-throw to propagate the error
}
}
getUserAndOrders("user123")
.then(result => console.log("Final combined result:", result))
.catch(error => console.error("Caught error from getUserAndOrders:", error.message));
console.log("Async function initiated, doing other things...");
Benefits of Async/Await: * Readability: Code looks synchronous, which is much easier to follow. * Simpler Error Handling: Traditional try...catch blocks can be used, similar to synchronous code. * Debugging: Debugging asynchronous flows becomes significantly easier as the execution path is more linear.
Event Loops: The Heart of Non-Blocking I/O
For single-threaded environments like Node.js or Python's asyncio, the event loop is the core mechanism enabling asynchronous, non-blocking I/O. Instead of using multiple threads for concurrency, these environments use a single main thread that manages an event queue.
How it works: 1. When an I/O-bound operation (like an API call, file read, or database query) is initiated, it's offloaded to the operating system or a worker pool. 2. The main thread doesn't wait; it continues processing other tasks from the event queue. 3. When the I/O operation completes, an event is pushed back onto the event queue. 4. The event loop picks up this event and executes the associated callback function.
This model makes these runtimes incredibly efficient for I/O-heavy applications because the single thread is rarely idle, always doing useful work while waiting for I/O operations to complete in the background.
Threading/Concurrency Primitives (Java, C#): Managing Parallelism
In languages like Java or C#, which inherently support multi-threading, concurrency can be achieved through explicit thread management or higher-level concurrency primitives. While an event loop is excellent for I/O-bound tasks in single-threaded environments, multi-threading can provide true parallelism on multi-core processors, especially for CPU-bound tasks.
Key Constructs: * Threads: The most basic unit of execution. Creating and managing threads manually can be complex (race conditions, deadlocks). * Thread Pools: A collection of pre-initialized threads that can be reused to execute tasks. This reduces the overhead of creating and destroying threads and helps manage resource consumption. * Executors (Java): High-level API for managing thread pools and submitting tasks. ExecutorService allows for tasks to be submitted and their results (wrapped in Future objects) to be retrieved. * CompletableFuture (Java): A powerful class that extends Future with additional capabilities for chaining, combining, and composing asynchronous computations, similar to JavaScript Promises but often more feature-rich for handling complex dependency graphs and error recovery. * Tasks (C#): The Task Parallel Library (TPL) in C# provides robust constructs (Task, Task<TResult>) for asynchronous and parallel programming, often used in conjunction with async/await.
When to use: While async/await and event loops excel at non-blocking I/O, traditional threads and thread pools are still highly relevant for: * CPU-bound tasks: Where heavy computation is involved, running tasks in parallel on different CPU cores can significantly speed up execution. * Fine-grained control: When you need very specific control over thread lifecycle and synchronization. * Integrating with blocking APIs: When interfacing with legacy libraries or external services that only offer synchronous APIs, you can wrap these calls in a separate thread to prevent blocking your main application.
Each of these paradigms offers powerful tools for managing asynchronous operations. The choice often depends on the programming language, the nature of the tasks (I/O-bound vs. CPU-bound), and the specific requirements for control, readability, and error handling. For sending to two APIs, we will often combine these, leveraging the non-blocking nature for I/O and sometimes parallel execution for data processing if needed.
Architectural Patterns for Asynchronous Dual-API Sending
When the requirement arises to interact with two APIs (or more) as part of a single business process, merely understanding asynchronous programming constructs is not enough. You need to apply specific architectural patterns that address the complexities of coordination, data consistency, and failure handling across distributed services. These patterns provide blueprints for building robust and scalable solutions.
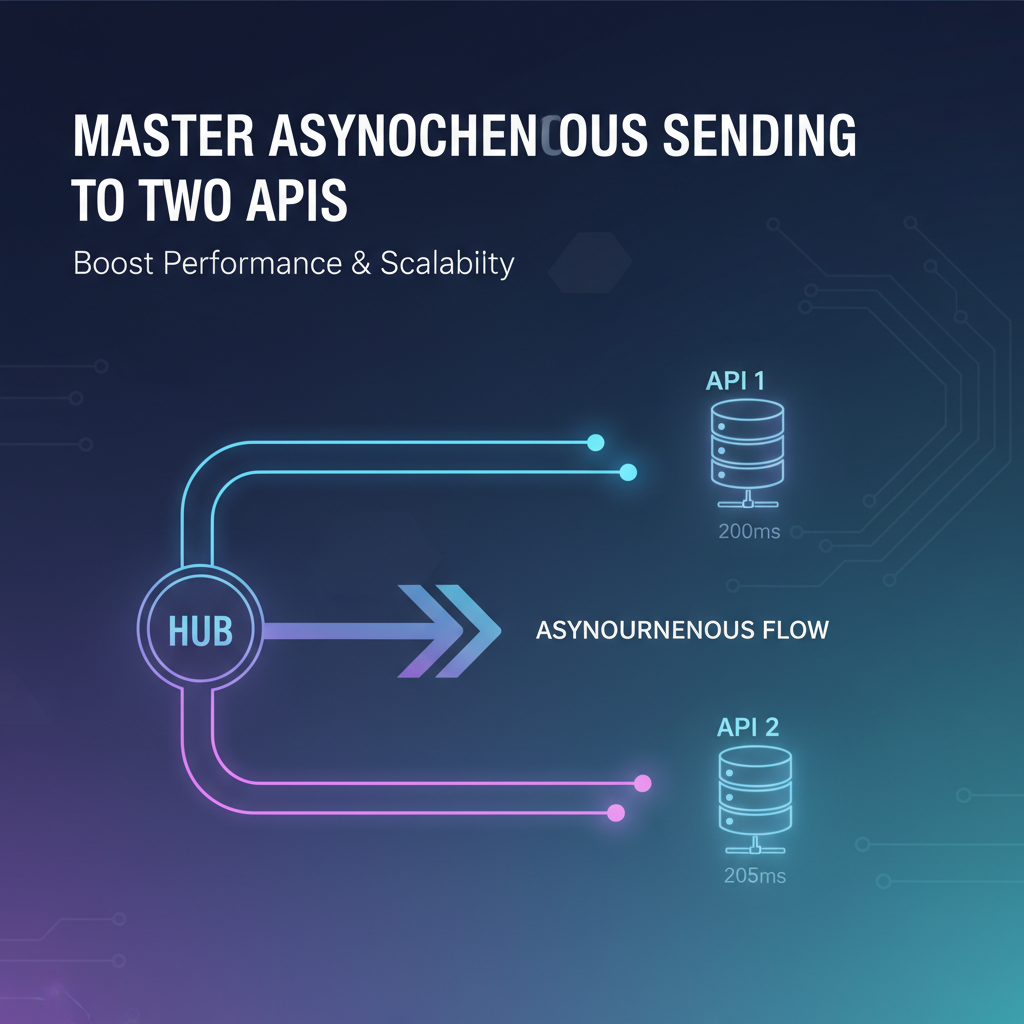
1. Fan-out Pattern: Parallel Execution and Aggregation
The fan-out pattern is perhaps the most straightforward and commonly used approach for making multiple independent asynchronous API calls concurrently. In this pattern, a single incoming request or event triggers multiple outgoing requests to different services, all executed in parallel. The results from these parallel calls can then be aggregated before being returned to the client or further processed.
Description: Imagine your application receives a request to create a new user account. This action might involve: 1. Calling the UserService to persist user details. 2. Calling the NotificationService to send a welcome email. 3. Calling the AnalyticsService to log the registration event.
These three calls are largely independent; the user doesn't need to wait for the email to be sent to confirm their account creation. The fan-out pattern allows all three API calls to be initiated almost simultaneously.
Implementation (Conceptual): * Using Promise.all() (JavaScript/TypeScript): Collect all the promises representing the individual API calls into an array and pass it to Promise.all(). This will wait until all promises in the array have either resolved or one has rejected. * Using CompletableFuture.allOf() (Java): Similar to Promise.all(), CompletableFuture.allOf() takes an array of CompletableFuture instances and returns a new CompletableFuture that completes when all of them have completed. * Using Thread Pools/Executors (General): Submit each API call as a separate task to a thread pool. Each task can perform a blocking call to its respective API, but since they are running on different threads from the pool, they execute in parallel relative to each other, and the main thread is not blocked.
Considerations: * Error Handling: If one of the fanned-out calls fails, how should the overall operation respond? Promise.all() will reject immediately if any promise rejects. You might need to adjust this behavior (e.g., using Promise.allSettled() in JS for individual status of each promise, or custom error handling in other languages) if a partial success is acceptable. * Result Aggregation: If the client needs a combined response from all fanned-out services, you'll need logic to collect and merge the individual responses once they all complete. * Timeouts: Each fanned-out call should have a reasonable timeout to prevent one slow API from indefinitely delaying the overall operation. * Resource Limits: Be mindful of the number of concurrent connections or requests your application and the target APIs can handle to avoid overwhelming them.
2. Publish-Subscribe (Pub/Sub) with Message Queues: Decoupling and Resilience
For scenarios requiring strong decoupling, guaranteed delivery, retries, and eventual consistency, the Publish-Subscribe (Pub/Sub) pattern, typically implemented with a message queue, is a superior choice. This pattern fundamentally alters how services communicate.
Description: Instead of your service directly calling two APIs, it publishes a "message" or "event" to a central message broker (the message queue). This message signifies that something notable has happened (e.g., "UserRegisteredEvent," "OrderPlacedEvent"). Other services, known as "subscribers" or "consumers," are configured to listen for specific types of messages from the queue. When a relevant message arrives, a consumer picks it up and performs its designated action, which might involve calling one of the target APIs.
Examples of Message Queues: Apache Kafka, RabbitMQ, AWS SQS/SNS, Google Cloud Pub/Sub, Azure Service Bus.
How it works for Dual API Calls: 1. Your application (the "publisher") performs its primary action (e.g., saves user data). 2. It then publishes an event (e.g., UserCreatedEvent) to a message queue. 3. Consumer 1: A separate microservice or worker process (a "consumer") is subscribed to UserCreatedEvent messages. When it receives one, it calls API 1 (e.g., the email service to send a welcome email). 4. Consumer 2: Another microservice or worker process (a different "consumer") is also subscribed to UserCreatedEvent messages. When it receives one, it calls API 2 (e.g., the analytics service to log the event).
Benefits: * Decoupling: The publisher doesn't need to know who the consumers are or how they process the event. It just publishes. This makes the system more flexible and easier to evolve. * Resilience and Reliability: * Asynchronous Nature: The publishing service isn't blocked waiting for API calls. It publishes and moves on. * Guaranteed Delivery: Message queues typically offer features like message persistence and acknowledgments, ensuring messages are not lost even if consumers fail. * Retries: If a consumer fails to process a message (e.g., the target API is down), the message can be automatically retried later. Messages can be moved to a Dead-Letter Queue (DLQ) after a configured number of retries for manual inspection. * Back Pressure: If an API is overwhelmed, the message queue acts as a buffer, allowing the publishing service to continue operating while consumers process messages at a sustainable rate. * Scalability: You can easily scale out consumers by adding more instances to handle increased message load. * Eventual Consistency: This pattern inherently supports eventual consistency. The primary operation completes quickly, and the secondary API calls eventually catch up, bringing the entire system to a consistent state.
Trade-offs: * Increased Complexity: Introducing a message queue adds another component to manage and monitor. * Message Ordering: Ensuring strict message ordering across multiple consumers can be challenging or require specific queue configurations. * Idempotency: Consumers must be designed to be idempotent, meaning processing the same message multiple times (due to retries) should have the same effect as processing it once. * Monitoring: Distributed tracing across message queues and multiple services requires robust monitoring tools.
3. Sagas and Orchestration: Managing Distributed Transactions
When dual API calls are part of a larger, multi-step business process that requires transactional integrity across multiple services (a "distributed transaction"), the Saga pattern becomes relevant. A Saga is a sequence of local transactions, where each local transaction updates data within a single service and publishes an event that triggers the next step of the saga. If a step fails, compensation transactions are executed to undo the changes made by preceding steps.
Description: Consider an order fulfillment process involving an Order Service, Payment Service, and Inventory Service. 1. Order Service: Creates an order, publishes OrderCreatedEvent. 2. Payment Service: Subscribes to OrderCreatedEvent, processes payment, publishes PaymentProcessedEvent (or PaymentFailedEvent). 3. Inventory Service: Subscribes to PaymentProcessedEvent, reserves inventory, publishes InventoryReservedEvent (or InventoryFailedEvent).
If InventoryFailedEvent occurs, the saga needs to initiate compensation: 1. Payment Service receives InventoryFailedEvent, refunds payment, publishes PaymentRefundedEvent. 2. Order Service receives PaymentRefundedEvent, cancels the order.
Orchestration vs. Choreography: Sagas can be implemented in two ways: * Orchestration: A central "orchestrator" service coordinates all steps of the saga, invoking local transactions in each service and handling compensation logic. This is often easier to implement for complex workflows. * Choreography: Each service performs its local transaction and publishes events, with other services reacting to these events. There's no central coordinator; services react in a decentralized manner. This is more flexible but can be harder to reason about and debug.
Relevance to Dual API Calls: If your two API calls are not entirely independent but need to succeed together (or be consistently rolled back), a Saga might be appropriate. For instance, if updating a user's subscription status in one API and updating their billing details in another API must be treated as an atomic unit, a Saga can define the sequence, events, and compensation steps to ensure this distributed atomicity.
Table: Common Use Cases for Asynchronous Dual-API Calls and Suitable Patterns
| Use Case Category | Example Scenario | Primary Driver | Suitable Asynchronous Patterns | Key Considerations |
|---|---|---|---|---|
| Data Replication/Audit | Update primary database and search index/data warehouse | Data consistency, secondary query speed | Fan-out (with error handling for consistency), Pub/Sub | Eventual consistency, retry logic, partial failure handling |
| Notifications/Side Effects | User registration triggers email and analytics event | User responsiveness, background processing | Fan-out (fire-and-forget), Pub/Sub | Non-critical, can tolerate minor delays/failures |
| Data Enrichment/Aggregation | Fetch user profile and external weather data | Combine data, reduce latency for client | Fan-out (with result aggregation) | Timeouts, handling slow/failed external APIs, data merging |
| Cross-System Updates (Loose Coupling) | Order placed updates inventory and CRM status | Decoupling services, resilience | Pub/Sub | Eventual consistency, idempotency, retry policies |
| Distributed Transactions (Strong Coupling) | Bank transfer (debit one account, credit another) | Transactional integrity across services | Sagas (Orchestrated or Choreographed) | Compensation logic, complex error handling, state management |
| A/B Testing/Shadowing | Send request to old and new API for comparison | Non-disruptive testing, performance insights | Fan-out (fire-and-forget for shadow API, primary for client) | Minimal impact on primary response latency |
This table highlights that the "best" pattern depends heavily on the specific requirements for consistency, latency, coupling, and resilience. For many dual API scenarios, a simple fan-out or a Pub/Sub mechanism will suffice, with Sagas reserved for more complex, business-critical distributed transactions.
Practical Implementations and Code Examples (Conceptual, Language Agnostic Focus)
Translating these architectural patterns into actual code requires leveraging the specific asynchronous constructs of your chosen programming language. While we'll maintain a language-agnostic focus, the conceptual examples will use common paradigms like Promises or async/await which are widely applicable.
Scenario 1: Simple Fire-and-Forget (No Result Aggregation Needed)
This scenario is common for operations like logging, analytics, or sending non-critical notifications where the primary business process does not depend on the success or response of the secondary API calls. The goal is to initiate the calls and move on immediately.
Example: A user performs an action (e.g., clicks a button). This action needs to be recorded in two different analytics systems (API A and API B). The user should not wait for these calls.
Conceptual Implementation:
// Assuming 'makeApiClientCallAsync' is a generic function that returns a Promise/Task
// and does not block the main execution thread.
// Function to handle user action and fire-and-forget to two APIs
async function handleUserAction(actionDetails) {
try {
// Perform the primary action immediately (e.g., save to DB, respond to user)
console.log("Primary action initiated for:", actionDetails.type);
// ... (primary, synchronous or quick async operations) ...
console.log("Primary action completed. Now firing off analytics.");
// Initiate API A call
const apiACall = makeApiClientCallAsync("analytics_api_a", {
event: actionDetails.type,
user: actionDetails.userId,
timestamp: new Date()
});
// Initiate API B call
const apiBCall = makeApiClientCallAsync("analytics_api_b", {
eventType: actionDetails.type,
userID: actionDetails.userId,
time: new Date().toISOString()
});
// Use Promise.allSettled or just await in a non-critical way,
// or even not await if strictly fire-and-forget and errors don't matter.
// For robustness, it's often good to log potential issues even if not blocking.
Promise.allSettled([apiACall, apiBCall])
.then(results => {
results.forEach((result, index) => {
if (result.status === 'fulfilled') {
console.log(`API Call ${index + 1} succeeded:`, result.value);
} else {
console.warn(`API Call ${index + 1} failed:`, result.reason);
// Potentially log to an error monitoring system
}
});
})
.catch(err => {
// This catch only for Promise.allSettled itself, not individual rejections
console.error("Error in allSettled processing:", err);
});
console.log("Analytics requests fired. Returning control to user/main thread.");
return { status: "success", message: "Action processed" };
} catch (primaryError) {
console.error("Error during primary action:", primaryError);
// Handle primary action failure
throw primaryError;
}
}
// Example usage:
handleUserAction({ type: "product_view", userId: "user456" });
console.log("Application continues processing other tasks...");
Explanation: * makeApiClientCallAsync is a placeholder for your actual asynchronous HTTP client calls. * We initiate both apiACall and apiBCall without awaiting them immediately. This makes them execute concurrently. * Promise.allSettled (available in many modern async runtimes) is used here. Unlike Promise.all, it doesn't short-circuit on the first rejection. It waits for all promises to settle (either fulfill or reject) and provides an array of objects describing the outcome of each promise. This is ideal for fire-and-forget where you want to know if something went wrong in the background but don't want to block. * The handleUserAction function returns immediately after initiating the API calls, providing a highly responsive experience.
Scenario 2: Parallel Calls with Result Aggregation
This pattern is essential when your application needs data from two independent APIs to construct a single, comprehensive response for the client. The goal is to fetch both pieces of data concurrently and then combine them.
Example: A request comes in for a user's dashboard. This requires fetching the user's basic profile from UserProfileService (API A) and their recent activity feed from ActivityService (API B). Both are needed before rendering the dashboard.
Conceptual Implementation:
// Function to fetch user profile (API A)
async function fetchUserProfile(userId) {
console.log(`Fetching profile for user ${userId} from API A...`);
// Simulate API call delay
return new Promise(resolve => setTimeout(() => {
resolve({ id: userId, name: "Charlie", email: "charlie@example.com", avatarUrl: "..." });
}, 700));
}
// Function to fetch user activity (API B)
async function fetchUserActivity(userId) {
console.log(`Fetching activity for user ${userId} from API B...`);
// Simulate API call delay
return new Promise((resolve, reject) => setTimeout(() => {
if (Math.random() < 0.9) { // 90% success rate
resolve([
{ type: "liked_post", postId: "p1", timestamp: "..." },
{ type: "commented_on", postId: "p2", timestamp: "..." }
]);
} else {
reject(new Error("Activity service temporarily unavailable."));
}
}, 500));
}
// Function to combine results for the dashboard
async function getDashboardData(userId) {
try {
console.log(`Initiating parallel fetches for dashboard data for user ${userId}.`);
// Initiate both API calls concurrently
const profilePromise = fetchUserProfile(userId);
const activityPromise = fetchUserActivity(userId);
// Wait for both promises to resolve using Promise.all
const [userProfile, userActivity] = await Promise.all([profilePromise, activityPromise]);
console.log("Both API calls completed. Aggregating results.");
return {
profile: userProfile,
activityFeed: userActivity,
lastUpdated: new Date().toISOString()
};
} catch (error) {
console.error("Failed to retrieve complete dashboard data:", error.message);
// Depending on requirements, you might return partial data,
// throw the error, or return a default/error state.
throw new Error(`Could not fetch dashboard data due to: ${error.message}`);
}
}
// Example usage:
getDashboardData("user789")
.then(data => console.log("Dashboard data ready:", JSON.stringify(data, null, 2)))
.catch(err => console.error("Error displaying dashboard:", err.message));
console.log("Application continues while dashboard data is fetched...");
Explanation: * fetchUserProfile and fetchUserActivity simulate independent asynchronous calls. * Promise.all([profilePromise, activityPromise]) is the key here. It takes an array of promises and returns a single promise that: * Resolves with an array of resolved values in the same order as the input promises, if all input promises resolve successfully. * Rejects with the reason of the first promise that rejects, if any promise rejects. * The await keyword then gracefully pauses the getDashboardData function until Promise.all settles. * Error handling with try...catch ensures that if either API call fails, the entire dashboard data retrieval operation can be gracefully handled, preventing a partial or inconsistent state.
Scenario 3: Resilient Calls with Retries and Fallbacks (using Message Queue)
For critical operations where one or both API calls must eventually succeed, even in the face of temporary failures, or when strong decoupling and scalability are paramount, integrating a message queue is the most robust solution.
Example: An internal system processes a "PaymentApproved" event. This needs to update the order status in the OrderService (API A) and send a webhook notification to a partner system via PartnerNotificationService (API B). If either API is down or experiences transient errors, the operation must be retried.
Conceptual Implementation using a Message Queue (e.g., RabbitMQ, Kafka):
Step 1: Publisher Service (your application) The publisher's role is simple: publish an event to the message queue after its primary task is done.
// Assuming 'messageQueueClient' is an initialized client for your message queue
async function processPaymentApproval(paymentDetails) {
try {
console.log("Processing payment approval...");
// ... (Perform primary operations like marking payment as complete in local DB) ...
console.log("Payment approved locally. Publishing event to message queue.");
const event = {
eventType: "PaymentApproved",
payload: paymentDetails,
timestamp: new Date().toISOString()
};
// Publish the event. This call should be non-blocking.
// The message queue will handle persistence and delivery.
await messageQueueClient.publish("payment_events_topic", event);
console.log("PaymentApproved event published. Returning confirmation.");
return { status: "success", message: "Payment processed and event published" };
} catch (error) {
console.error("Error processing payment or publishing event:", error);
throw error;
}
}
// Example usage:
processPaymentApproval({ transactionId: "tx123", amount: 150.00, userId: "user456" });
console.log("Publisher service continues without waiting for API B calls.");
Step 2: Consumer Services (separate workers/microservices) Two independent consumer services listen to the payment_events_topic.
Consumer 1: Order Status Updater
// Consumer for OrderService API A
async function startOrderStatusConsumer() {
console.log("Order Status Consumer started, listening for PaymentApproved events.");
await messageQueueClient.subscribe("payment_events_topic", async (message) => {
const event = message.payload;
if (event.eventType === "PaymentApproved") {
try {
console.log(`Consumer 1: Received PaymentApproved for ${event.payload.transactionId}. Calling OrderService (API A)...`);
// Assume 'orderApiClient' is a client for OrderService
await orderApiClient.updateOrderStatus(event.payload.transactionId, "APPROVED");
console.log(`Consumer 1: Order status updated for ${event.payload.transactionId}.`);
message.acknowledge(); // Acknowledge successful processing
} catch (error) {
console.error(`Consumer 1: Failed to update order status for ${event.payload.transactionId}:`, error);
// The message queue will typically handle retries here based on NACK or lack of ACK.
// Potentially send to a Dead-Letter Queue after max retries.
message.nack(); // Negative acknowledgment, usually triggers retry
}
}
});
}
startOrderStatusConsumer();
Consumer 2: Partner Notification Sender
// Consumer for PartnerNotificationService API B
async function startPartnerNotificationConsumer() {
console.log("Partner Notification Consumer started, listening for PaymentApproved events.");
await messageQueueClient.subscribe("payment_events_topic", async (message) => {
const event = message.payload;
if (event.eventType === "PaymentApproved") {
try {
console.log(`Consumer 2: Received PaymentApproved for ${event.payload.transactionId}. Calling PartnerNotificationService (API B)...`);
// Assume 'partnerApiClient' is a client for PartnerNotificationService
await partnerApiClient.sendWebhookNotification(event.payload);
console.log(`Consumer 2: Partner notification sent for ${event.payload.transactionId}.`);
message.acknowledge();
} catch (error) {
console.error(`Consumer 2: Failed to send partner notification for ${event.payload.transactionId}:`, error);
message.nack();
}
}
});
}
startPartnerNotificationConsumer();
Explanation: * Decoupling: The processPaymentApproval function doesn't know about OrderService or PartnerNotificationService. It only interacts with the message queue. * Resilience: If OrderService or PartnerNotificationService is temporarily unavailable, the consumer's try...catch block will catch the error. By sending a negative acknowledgment (message.nack()), the message queue can be configured to retry delivering the message after a delay, ensuring eventual delivery. * Scalability: You can run multiple instances of OrderStatusConsumer and PartnerNotificationConsumer to handle high loads. * Idempotency: Both updateOrderStatus and sendWebhookNotification should ideally be idempotent. For instance, if updateOrderStatus is called twice for the same transaction with "APPROVED" status, it should only update it once or recognize it's already approved. For webhooks, the partner system should handle duplicate notifications gracefully. This is a critical design aspect for message queue consumers.
Error Handling and Idempotency: Pillars of Asynchronous Robustness
Regardless of the pattern chosen, two concepts are non-negotiable for robust asynchronous dual-API interactions: comprehensive error handling and careful consideration of idempotency.
Error Handling: * Individual Call Failures: What happens if only one of the two API calls fails? * Partial Success: For non-critical side effects (like analytics), a partial success might be acceptable, with logging to capture the failed attempt. * Rollback/Compensation: For critical, interdependent operations, a failure in one might require undoing the successful operations in the other. This is where Sagas come into play. * Retries: Transient network errors or temporary service unavailability should trigger retries, often with an exponential backoff strategy (increasing delay between retries) to avoid overwhelming the struggling service. * Circuit Breakers: Implement circuit breaker patterns (e.g., Hystrix, Resilience4j) to prevent a failing API from cascading failures throughout your system. If an API consistently fails, the circuit breaker "opens," preventing further calls and quickly failing requests locally until the API recovers. * Timeouts: Configure strict timeouts for all external API calls. An API that never responds is as bad as one that consistently fails. * Dead-Letter Queues (DLQ): For message queue patterns, messages that repeatedly fail processing after several retries should be moved to a DLQ for manual inspection, preventing them from endlessly blocking the queue or consuming resources.
Idempotency: When dealing with retries (whether from your code or a message queue), it's highly likely that an API call might be executed multiple times. An idempotent operation is one that can be applied multiple times without changing the result beyond the initial application.
- Example: A request to "Set user status to active" is idempotent. Calling it twice has the same effect as calling it once. A request to "Increment user's balance by $10" is not idempotent. Calling it twice would increment the balance by $20.
- Ensuring Idempotency:
- Unique Identifiers: Provide a unique, client-generated request ID (idempotency key) with each request. The receiving API can then store this key and, if it sees the same key again, return the original response without re-processing the request.
- Conditional Updates: For updates, use optimistic locking or conditional updates (e.g., "update if current version is X") to ensure you're not overwriting changes or applying outdated logic.
- Design for Side Effects: Carefully design operations that have side effects. If an operation inherently cannot be idempotent, extra care must be taken to ensure it's only executed once, or that subsequent executions are handled appropriately (e.g., using a transaction log on the receiving side).
Mastering these practical implementations and adhering to robust error handling and idempotency principles are critical for building asynchronous systems that are not only fast but also reliable and resilient in the face of the inevitable failures of distributed computing.
APIPark is a high-performance AI gateway that allows you to securely access the most comprehensive LLM APIs globally on the APIPark platform, including OpenAI, Anthropic, Mistral, Llama2, Google Gemini, and more.Try APIPark now! 👇👇👇
The Role of an API Gateway in Asynchronous Dual-API Sending
While implementing robust asynchronous patterns directly within your application code is powerful, organizations often find immense value in leveraging an API Gateway. An API Gateway acts as a crucial control plane, simplifying complex routing, security, and transformation tasks. It serves as a single entry point for all API consumers, abstracting away the complexities of your backend architecture.
What is an API Gateway?
At its core, an API Gateway is a server that acts as an API frontend, sitting between clients and your backend services. It handles common concerns that every API needs, rather than scattering that logic across individual services. These concerns typically include:
- Authentication and Authorization: Verifying client identity and permissions.
- Rate Limiting: Protecting backend services from being overwhelmed by too many requests.
- Routing: Directing incoming requests to the correct backend service based on the request path or other criteria.
- Transformation: Modifying request and response payloads to match client or backend expectations.
- Caching: Storing frequently accessed data to reduce load on backend services.
- Monitoring and Logging: Centralizing metrics and logs for all API traffic.
- Load Balancing: Distributing requests across multiple instances of a backend service.
- Circuit Breaking: Preventing cascading failures by quickly failing requests to unhealthy services.
How an API Gateway Can Facilitate Dual API Calls
An API Gateway can significantly simplify and enhance the management of asynchronous sending to two (or more) APIs, effectively offloading some of the orchestration logic from your application code.
- Request Fan-out at the Gateway: One of the most powerful features an API Gateway can offer in this context is the ability to fan out a single incoming request to multiple upstream backend services simultaneously.
- Description: A client makes one request to the API Gateway (e.g.,
POST /users/register). The Gateway is configured to, upon receiving this request, forward it (potentially with transformations) toUserService(API A) and also toNotificationService(API B) andAnalyticsService(API C) – all in parallel. - Benefits: This completely abstracts the dual/multi-API calling logic from the client. The client only sees a single, unified API endpoint. The gateway handles the parallelism, potentially waiting for all responses (similar to
Promise.all) and aggregating them, or simply performing fire-and-forget for secondary calls. - Example: An e-commerce gateway could receive an
/orderrequest, forward it to theOrder Processing Servicefor the primary transaction, and asynchronously send a copy of the order details to theCRM Servicefor customer history update and to theAnalytics Servicefor sales tracking.
- Description: A client makes one request to the API Gateway (e.g.,
- Transformation and Orchestration: Gateways can perform sophisticated request and response transformations. If API A and API B expect slightly different data formats for the same logical operation, the gateway can translate the incoming client request into the appropriate format for each backend. Advanced gateways can even perform basic orchestration, such as making a call to API A, then using a piece of API A's response to formulate a subsequent call to API B. This reduces the need for a dedicated orchestration layer in your application.
- Unified Monitoring, Logging, and Tracing: When fanning out requests to multiple backend services, tracking the entire flow can become complex. An API Gateway centralizes this. It can log every incoming request and every outgoing request to backend services, providing a single point of truth for observability. This is invaluable for debugging, performance analysis, and understanding how distributed operations are performing. Detailed logging provided by gateways helps in quickly identifying which of the dual API calls might be failing or causing latency.
- Load Balancing and Circuit Breaking: An API Gateway is inherently designed to manage the health and load of your backend services. If you're fanning out to two different APIs, the gateway can ensure that each backend API call is routed to a healthy instance, and it can open a circuit if one of the backend APIs becomes unresponsive, preventing your system from waiting indefinitely for a failed service.
- Asynchronous Processing within the Gateway: Some advanced API Gateways are built with asynchronous I/O models themselves, meaning they can efficiently handle a large number of concurrent connections and backend calls without blocking their own threads. They can also integrate with message queues internally, allowing for more robust asynchronous patterns where the gateway itself publishes events that trigger backend API calls.
APIPark: An Open Source Solution for API Management
Platforms like APIPark exemplify how a modern API Gateway can simplify API management, including complex asynchronous scenarios. APIPark, as an all-in-one AI gateway and API developer portal, offers capabilities that are highly relevant to mastering asynchronous sending to multiple APIs.
- End-to-End API Lifecycle Management: APIPark helps manage the entire lifecycle of APIs, from design to publication and invocation. This comprehensive management is crucial when dealing with multiple APIs, ensuring consistent design, versioning, and governance across all your integrated services. This directly assists in streamlining the process of defining and managing the two APIs you intend to interact with.
- Traffic Forwarding and Load Balancing: When you configure your API Gateway to fan out requests to two different backend APIs, APIPark's capabilities for managing traffic forwarding and load balancing become critical. It can intelligently route requests to the appropriate instances of your backend services, ensuring high availability and optimal resource utilization, even if one of your target APIs has multiple instances.
- Detailed API Call Logging and Data Analysis: For asynchronous dual-API calls, understanding the performance and failure rates of each individual call is paramount. APIPark provides comprehensive logging, recording every detail of each API call. This granular data allows businesses to quickly trace and troubleshoot issues in API calls, which is essential when one of your two backend APIs might be experiencing intermittent problems. Its powerful data analysis features can show long-term trends and performance changes, helping in preventive maintenance.
- Performance Rivaling Nginx: The high performance of APIPark, capable of achieving over 20,000 TPS, ensures that the gateway itself doesn't become a bottleneck when fanning out numerous requests to multiple APIs. Its ability to support cluster deployment further guarantees scalability for handling large-scale traffic, a common requirement when orchestrating many backend interactions.
- Unified API Format for AI Invocation & Prompt Encapsulation: While focused on AI, APIPark's ability to standardize request data formats and encapsulate prompts into REST APIs demonstrates its strength in abstraction. This capability can be extended to traditional REST APIs, allowing the gateway to transform and standardize requests before forwarding them to heterogeneous backend APIs, simplifying the integration logic for your client applications. For instance, if your two APIs expect different JSON structures, APIPark could handle the transformation.
- API Service Sharing within Teams & Independent API and Access Permissions: For organizations with multiple teams or tenants, APIPark facilitates secure and organized API consumption. This is important when different teams might be responsible for different backend APIs you're fanning out to. Centralized display and access permissions simplify collaboration and governance.
By centralizing common concerns and providing robust features, an API Gateway like APIPark not only simplifies the implementation of asynchronous dual-API sending but also significantly enhances the security, observability, and overall resilience of your distributed system. It allows application developers to focus more on core business logic rather than boilerplate integration complexities.
Performance Considerations and Optimization
Achieving mastery in asynchronous sending to two APIs isn't just about making the calls; it's about making them efficiently and performantly. Even with asynchronous patterns, bottlenecks can emerge if performance considerations are not addressed proactively.
Concurrency vs. Parallelism: A Crucial Distinction
While often used interchangeably, understanding the difference between concurrency and parallelism is vital for optimization: * Concurrency: Deals with managing multiple tasks at once. It's about structuring your code so that multiple tasks can make progress simultaneously, even if they're not all executing at the exact same instant (e.g., context switching on a single CPU core, or non-blocking I/O with an event loop). Asynchronous I/O with a single thread (like Node.js) achieves concurrency. * Parallelism: Deals with executing multiple tasks simultaneously at the exact same instant, typically on multiple CPU cores or processors. Multi-threading on a multi-core machine achieves true parallelism for CPU-bound tasks.
For I/O-bound tasks (like waiting for API responses), concurrency is generally the primary goal, and asynchronous patterns excel at this by minimizing idle thread time. For CPU-bound tasks (e.g., heavy data processing after receiving API responses), parallelism can offer additional speedups.
Resource Management: Preventing Bottlenecks
- Connection Pools: When making HTTP requests to external APIs, establishing a new TCP connection for every request is expensive. Use HTTP client libraries that implement connection pooling (e.g., Apache HttpClient in Java,
requestswithrequests-toolbeltin Python, built-in in Node.jshttpagent, or any modern HTTP client). A connection pool maintains a set of open, reusable connections, drastically reducing connection setup overhead. - Thread Pools (for Multi-threaded environments): If you're using threads for parallelism (e.g., in Java with
ExecutorService), manage them via thread pools. Creating and destroying threads is costly. A well-configured thread pool reuses threads, limits the number of concurrent tasks (preventing resource exhaustion), and provides control over task execution. Ensure the pool size is appropriate for your workload – too small, and you'll have tasks waiting; too large, and you risk excessive context switching and resource contention. - Memory Management: Asynchronous operations, especially when dealing with many concurrent tasks and large data payloads from APIs, can consume significant memory. Monitor your application's memory usage and look for leaks or inefficient data structures.
Latency vs. Throughput: Balancing Goals
- Latency: The time it takes for a single request to complete (from initiation to response). Asynchronous patterns primarily aim to improve perceived latency for the user by not blocking, and can reduce actual latency by parallelizing independent operations.
- Throughput: The number of requests your system can handle per unit of time. Asynchronous I/O significantly boosts throughput by allowing a single thread to manage many concurrent I/O operations.
When optimizing dual API calls, you might prioritize lower overall latency for a single combined response (e.g., using Promise.all for data aggregation) or higher throughput for fire-and-forget operations (e.g., publishing to a message queue). The choice dictates the specific optimization strategies.
Network Overhead: Minimizing Round Trips
- Reduce Request Size: Minimize the amount of data sent in each request to the APIs. Only send what's necessary.
- Compress Responses: If the APIs support it, enable GZIP or Brotli compression for responses to reduce data transfer time.
- Keep-Alive Connections: Utilize HTTP Keep-Alive to reuse TCP connections across multiple requests, reducing the overhead of connection establishment. This is usually handled by modern HTTP clients and connection pooling.
- Proximity: If possible, deploy your services geographically close to the external APIs they depend on to minimize network latency.
Monitoring and Observability: Knowing Your System
You can't optimize what you can't measure. Robust monitoring is crucial for identifying performance bottlenecks in asynchronous dual-API interactions: * Request Tracing: Implement distributed tracing (e.g., OpenTelemetry, Zipkin, Jaeger) to visualize the flow of a request across your application and the two external APIs. This helps pinpoint exactly where latency is being introduced. * API Metrics: Collect metrics for each API call: response times (average, p95, p99), error rates, timeouts. Distinguish between the two APIs. * System Metrics: Monitor CPU, memory, network I/O, and thread pool utilization of your application instances. * Logging: Ensure detailed logging of asynchronous operations, including start times, completion times, and any errors. Correlate logs with request IDs. As mentioned, an API Gateway like APIPark with its detailed API call logging and powerful data analysis features is invaluable for this purpose.
Caching Strategies
For read-heavy operations where one or both APIs provide data that doesn't change frequently, caching can dramatically improve performance and reduce the load on backend services: * Client-Side Caching: The client application can cache responses. * Application-Level Caching: Your service can cache responses from the external APIs in memory or a distributed cache (e.g., Redis). * API Gateway Caching: As discussed, an API Gateway can cache responses, serving cached data without forwarding the request to the backend at all, significantly reducing latency and load.
When implementing caching, consider cache invalidation strategies (e.g., time-based expiry, event-driven invalidation) to ensure data freshness.
By meticulously addressing these performance considerations and leveraging appropriate optimization techniques, you can ensure that your asynchronous dual-API sending mechanisms are not only robust and reliable but also deliver exceptional speed and efficiency, truly mastering the art of distributed system interaction.
Challenges and Best Practices in Asynchronous Dual-API Sending
Even with a solid understanding of paradigms and patterns, implementing robust asynchronous interactions with two APIs presents specific challenges that require careful design and adherence to best practices.
1. Data Consistency: Eventual vs. Strong
When data is updated across two independent APIs, maintaining consistency becomes complex. * Strong Consistency: Requires that all updates are immediately visible and consistent across all systems. This is difficult and often impractical in distributed systems without sacrificing availability or performance (CAP theorem). For critical operations like financial transactions, Sagas can help achieve "transactional consistency" via compensation. * Eventual Consistency: A more common and practical approach in distributed systems. It means that while data might be inconsistent for a brief period after an update, it will eventually converge to a consistent state. Message queues are excellent for achieving eventual consistency. * Best Practice: Understand the consistency requirements for each specific dual API interaction. For many scenarios (e.g., sending an email and logging an event), eventual consistency is perfectly acceptable. For others (e.g., deducting inventory and processing payment), stronger guarantees are needed, potentially calling for Sagas or more complex distributed transaction managers.
2. Error Propagation and Client Communication
When an asynchronous operation fails, how do you inform the client or the upstream service that initiated the request? * Partial Failures: If using Promise.allSettled or similar, you'll know which individual calls succeeded and which failed. Decide if partial success is acceptable. * Asynchronous Error Reporting: For fire-and-forget operations, errors might occur long after the initial request. These errors typically need to be logged (to an error tracking system like Sentry or PagerDuty) and potentially trigger alerts for operations teams. They cannot be directly returned to the originating client. * Callback/Promise Rejection: For operations where the client is waiting, errors should propagate through promise rejections or exceptions in async/await blocks, allowing the initiating code to handle them. * Best Practice: Design clear error contracts for your APIs. For critical failures, communicate specific error codes and messages to the client. For background asynchronous failures, ensure robust logging, monitoring, and alerting.
3. Debugging Complex Asynchronous Flows
The non-linear nature of asynchronous code can make debugging significantly harder than traditional synchronous code. * Stack Traces: Asynchronous stack traces can be fragmented, making it hard to follow the causal chain of events. * Race Conditions: Although less common with pure async I/O (which avoids shared mutable state), if you introduce shared state or multi-threading, race conditions can occur. * Best Practice: * Structured Logging: Use log correlation IDs (transaction IDs) that are passed through all asynchronous steps and API calls. This allows you to trace a single request's journey through multiple services and log entries. API Gateways like APIPark help immensely here by centralizing logs. * Distributed Tracing Tools: Tools like OpenTelemetry, Jaeger, or Zipkin are indispensable for visualizing request flows across microservices and asynchronous boundaries, providing insights into latency and errors. * Meaningful Naming: Give descriptive names to your promises, callbacks, and async functions to improve code readability and debuggability. * async Debugging Tools: Many IDEs and language runtimes offer enhanced debugging capabilities for asynchronous code (e.g., Chrome DevTools for Node.js).
4. Resource Contention
While asynchronous I/O helps avoid thread blocking, resource contention can still arise: * Database Connections: If multiple asynchronous tasks try to acquire database connections from a limited pool, contention can occur. * External API Rate Limits: Hitting rate limits on external APIs due to aggressive concurrent calls can lead to service degradation or blocking. * Best Practice: * Connection Pooling: As discussed, use connection pools for databases and HTTP clients. * Rate Limit Management: Implement client-side rate limiters or token buckets to control the outgoing request rate to external APIs. Respect Retry-After headers if provided by the external API. * Back Pressure: Design your system to handle back pressure, where overloaded downstream services can signal upstream services to slow down, preventing resource exhaustion. Message queues naturally provide this buffering.
5. Versioning and API Evolution
External APIs evolve. Changes in one of the two APIs you're calling can break your integration. * Breaking Changes: New versions of APIs might introduce breaking changes in request/response formats, authentication, or endpoint URLs. * Dependency Management: Managing dependencies on multiple external APIs adds complexity. * Best Practice: * Defensive Programming: Be prepared for changes. Use schema validation for API responses. * Versioned APIs: Prefer APIs that are explicitly versioned (e.g., /v1/users, /v2/users). * API Gateway as Abstraction: An API Gateway can act as an abstraction layer, shielding your internal services from direct external API changes. It can perform transformations to bridge differences between external API versions and what your internal services expect. * Testing: Implement comprehensive integration tests that validate your dual-API interactions. Monitor for deprecation notices from third-party APIs.
6. Security Considerations
Sending data to two APIs means you're potentially interacting with two different external entities, each with its own security requirements. * Authentication: Ensure you are securely authenticating to both APIs. This might involve different credential types (API keys, OAuth tokens, client certificates). * Authorization: Ensure your application has the necessary permissions to perform the requested actions on both APIs. Adhere to the principle of least privilege. * Data Encryption: Ensure all communication with external APIs uses strong encryption (HTTPS/TLS). * Data Minimization: Only send the minimum necessary data to each API. Avoid sending sensitive data to an API if it's not absolutely required. * Credential Management: Securely store and retrieve API credentials (e.g., using environment variables, secret management services like AWS Secrets Manager, HashiCorp Vault). Avoid hardcoding credentials. * Best Practice: An API Gateway can centralize security concerns. It can handle authentication to multiple backend services, often transforming a single incoming token into the appropriate credentials for each downstream API, greatly simplifying the security posture. APIPark's features for independent API and access permissions for each tenant and API resource access requiring approval directly contribute to a stronger security framework for your APIs.
By proactively addressing these challenges with robust best practices, developers can navigate the complexities of asynchronous dual-API sending, building systems that are not only performant and scalable but also resilient, secure, and maintainable in the long run. The journey to mastering asynchronous interactions is continuous, requiring vigilance, thoughtful design, and a commitment to operational excellence.
Conclusion
The journey to master asynchronous sending to two APIs is a fundamental undertaking for any developer or architect operating within today's interconnected, distributed computing landscape. We've traversed from the foundational concepts of synchronous versus asynchronous programming, understanding why non-blocking I/O is not merely an optimization but a necessity for building responsive and scalable systems. The intrinsic latency and potential unreliability of network calls, amplified when coordinating interactions with multiple external services, demand a paradigm shift from sequential execution to concurrent and parallel processing.
We explored the diverse palette of asynchronous programming paradigms, from the callback's raw power to the elegant structure of Promises and the synchronous-like readability offered by async/await. We delved into the underlying mechanisms like event loops and the strategic utility of thread pools for CPU-bound tasks in multi-threaded environments. Equipped with these tools, we then examined powerful architectural patterns: the fan-out pattern for parallel execution and aggregation, the highly decoupled and resilient publish-subscribe model facilitated by message queues, and the more intricate Saga pattern for ensuring transactional consistency across distributed services. Each pattern offers a distinct approach to orchestrating dual API interactions, tailored to specific requirements for coupling, consistency, and fault tolerance.
Crucially, we emphasized that true mastery extends beyond mere implementation to embrace the critical pillars of error handling and idempotency. Building systems that can gracefully recover from partial failures, retry transient errors with intelligence, and ensure that duplicate operations do not lead to unintended side effects is paramount for long-term stability and reliability. Without these considerations, the promise of asynchronous programming can quickly devolve into a nightmare of unpredictable behavior and data inconsistencies.
Furthermore, we highlighted the indispensable role of an API Gateway in modern architectures. Acting as a central nervous system for your APIs, a gateway can significantly simplify the complexities of asynchronous dual-API sending. By offloading concerns like request fan-out, transformation, centralized monitoring, load balancing, and security, a robust API Gateway empowers application developers to focus on core business logic rather than infrastructural plumbing. Platforms like APIPark exemplify this, providing comprehensive API lifecycle management, high-performance traffic handling, and invaluable analytics that are essential for governing the intricate dance of multiple API integrations. Its capabilities not only streamline the deployment and management of individual APIs but also fortify the overall resilience and observability of systems engaged in complex asynchronous communication.
Finally, we delved into crucial performance considerations and a comprehensive set of challenges and best practices. From managing connection and thread pools to understanding the nuances of latency versus throughput, and from grappling with data consistency models to navigating the complexities of debugging, security, and API evolution, the path to mastery is paved with thoughtful design and continuous refinement.
In conclusion, the ability to asynchronously send data to two APIs is a core competency for building modern, high-performance, and resilient distributed systems. It’s about leveraging the right tools, applying appropriate architectural patterns, and adhering to rigorous engineering best practices. By doing so, you can unlock unparalleled responsiveness, scalability, and robustness, ensuring your applications not only meet but exceed the demands of today’s dynamic digital landscape. This mastery transforms your systems from brittle, sequential dependencies into fluid, concurrent powerhouses, ready to tackle the complexities of an ever-evolving API-driven world.
Frequently Asked Questions (FAQ)
1. What is the primary benefit of sending data to two APIs asynchronously instead of synchronously? The primary benefit is significantly improved performance, responsiveness, and resilience. Synchronous calls block the application's execution, leading to increased latency and reduced throughput if one API is slow or unavailable. Asynchronous calls allow your application to initiate both API requests simultaneously or in a non-blocking fashion, immediately moving on to other tasks. This minimizes wait times, keeps the system responsive, and allows for more graceful handling of failures and retries without stalling the entire process.
2. When should I choose a Fan-out pattern over a Publish-Subscribe (Message Queue) pattern for dual API calls? * Fan-out Pattern (e.g., using Promise.all): Ideal for simpler scenarios where the two API calls are relatively independent, and your application needs to either wait for both results to aggregate them or simply "fire and forget" with minimal concern for individual failures. It's suitable for operations like fetching data for aggregation or sending non-critical side effects (e.g., logging, basic analytics) where direct, synchronous feedback to the calling application is often desired, or immediate failure detection of any component is needed. * Publish-Subscribe (Message Queue) Pattern: Preferred for scenarios requiring strong decoupling, high resilience, guaranteed delivery, retries, and eventual consistency. It's excellent when the publishing service should not be directly dependent on the availability or success of the consuming services. This pattern introduces a buffer (the message queue), making it highly scalable and robust against temporary API outages for critical background tasks (e.g., updating inventory and sending partner notifications after an order is placed).
3. What are the key challenges in implementing asynchronous dual API calls, and how can they be mitigated? Key challenges include data consistency across systems, complex error handling (especially partial failures), debugging non-linear flows, resource contention, and managing API evolution. * Mitigation: * Data Consistency: Understand if eventual consistency is acceptable or if stronger guarantees (e.g., Sagas) are needed. * Error Handling: Implement robust try...catch blocks, retries with exponential backoff, circuit breakers, and comprehensive logging. * Debugging: Use structured logging with correlation IDs, distributed tracing tools (e.g., OpenTelemetry), and meaningful code structures (async/await). * Resource Contention: Employ connection pools for HTTP clients and databases, manage thread pools (if applicable), and respect external API rate limits. * API Evolution: Use versioned APIs, defensive programming, and an API Gateway as an abstraction layer.
4. How can an API Gateway simplify asynchronous sending to two APIs? An API Gateway significantly simplifies this by acting as a central control plane. It can: * Perform Request Fan-out: Configure the gateway to automatically forward a single incoming client request to two or more backend APIs in parallel, abstracting this complexity from the client. * Orchestration and Transformation: Transform request/response payloads to match the specific requirements of different backend APIs. * Centralized Monitoring and Logging: Provide a unified view of all API interactions, including fanned-out requests, making it easier to troubleshoot and monitor performance. * Security: Handle authentication and authorization to multiple backend APIs securely. * Load Balancing & Circuit Breaking: Manage the health and load of the backend APIs, preventing cascading failures. Platforms like APIPark offer these capabilities, enhancing the management and resilience of your multi-API integrations.
5. Why is idempotency critical when dealing with asynchronous API calls and retries? Idempotency is critical because asynchronous systems, especially those using message queues or implementing retry mechanisms, are inherently susceptible to processing the same request multiple times. An idempotent operation is one that produces the same result regardless of how many times it is executed. If an operation isn't idempotent (e.g., "add $10 to balance"), a retried request could lead to incorrect states (e.g., $20 added instead of $10). Ensuring idempotency (e.g., by using unique transaction IDs or conditional updates) prevents these issues, guaranteeing data consistency and correctness even in the face of network delays or system failures.
🚀You can securely and efficiently call the OpenAI API on APIPark in just two steps:
Step 1: Deploy the APIPark AI gateway in 5 minutes.
APIPark is developed based on Golang, offering strong product performance and low development and maintenance costs. You can deploy APIPark with a single command line.
curl -sSO https://download.apipark.com/install/quick-start.sh; bash quick-start.sh

In my experience, you can see the successful deployment interface within 5 to 10 minutes. Then, you can log in to APIPark using your account.

Step 2: Call the OpenAI API.

