Mastering Sliding Window Rate Limiting



In the intricate tapestry of modern distributed systems, where services communicate through a myriad of Application Programming Interfaces (APIs), the sheer volume and velocity of incoming requests can quickly become a double-edged sword. While high demand often signals success, unchecked traffic can overwhelm backend infrastructure, degrade service quality, incur exorbitant costs, and even expose systems to malicious attacks. This precarious balance between accessibility and resilience necessitates sophisticated traffic management strategies, with rate limiting emerging as a foundational pillar. Among the various algorithms designed to govern the flow of requests, the Sliding Window Counter stands out as a particularly elegant and effective solution, offering a superior blend of accuracy and efficiency compared to its counterparts.
This article embarks on an exhaustive exploration of sliding window rate limiting. We will meticulously dissect its underlying principles, compare it against alternative methods, and provide a detailed roadmap for its implementation in diverse architectural contexts. Furthermore, we will delve into advanced considerations, best practices, and real-world applications, equipping developers, system architects, and operations teams with the knowledge to master this critical technique. Our journey will illuminate why the sliding window algorithm has become a preferred choice for managing API traffic, safeguarding system stability, and ensuring a fair experience for all consumers interacting with your digital services. By the end, you will possess a profound understanding of how to leverage this powerful mechanism to fortify your API landscape against the relentless tides of the internet.
The Imperative of Rate Limiting in Modern Systems: Guarding the Digital Gates
The digital ecosystem of today is characterized by an unprecedented level of interconnectedness. From mobile applications constantly fetching data to microservices orchestrating complex business processes, and third-party integrations extending platform capabilities, APIs serve as the crucial conduits through which information and commands flow. This pervasive reliance on APIs, while enabling rapid innovation and expansive reach, simultaneously introduces significant vulnerabilities and operational challenges that demand proactive mitigation. It is within this dynamic environment that rate limiting transitions from a mere technical feature to an absolute necessity for survival and sustained success.
At its core, rate limiting is a mechanism designed to control the number of requests a client can make to a server within a given timeframe. Think of it as a bouncer at a popular club, ensuring that the venue doesn't get overcrowded, that everyone inside has a good experience, and that the club itself isn't damaged by excessive enthusiasm. Without such controls, a digital service, much like an overpacked club, faces a multitude of potential catastrophes that can range from minor annoyances to catastrophic system failures.
One of the most immediate and tangible benefits of rate limiting is its pivotal role in preventing Denial-of-Service (DoS) and Distributed Denial-of-Service (DDoS) attacks. Malicious actors often attempt to overwhelm a service with an avalanche of requests, aiming to exhaust its resources (CPU, memory, network bandwidth, database connections) and render it unavailable to legitimate users. By setting intelligent limits, a service can identify and block or throttle requests from sources exhibiting abnormal patterns, effectively acting as a first line of defense against these destructive onslaughts. This not only protects the service's uptime but also shields its reputation and prevents potential financial losses associated with downtime.
Beyond protection against overt attacks, rate limiting is instrumental in ensuring fair resource allocation. In a multi-tenant environment or for public APIs where various consumers vie for shared resources, unchecked usage by a single greedy or misconfigured client can inadvertently starve others. Imagine a scenario where one API consumer initiates an infinite loop of requests due to a bug, or another launches a high-frequency data scraping operation. Without rate limits, these actions would disproportionately consume server resources, leading to degraded performance or even unavailability for all other clients. Rate limiting establishes a clear contract, guaranteeing a baseline quality of service for all by preventing any single entity from monopolizing the shared infrastructure. This principle of fairness is paramount in fostering a healthy and equitable API ecosystem.
The economic implications of uncontrolled API usage are also substantial. Many cloud-based services and third-party APIs operate on a usage-based billing model. An unexpected surge in requests, whether legitimate or malicious, can lead to unforeseen and astronomical infrastructure costs. For instance, excessive calls to a serverless function, database queries, or external APIs (each potentially incurring a charge) can quickly inflate operational expenses beyond budget. Rate limiting acts as a crucial cost-control mechanism, allowing organizations to manage and predict their spending by capping the volume of interactions at various service boundaries. This financial prudence is particularly vital for startups and businesses operating on tight margins.
Furthermore, rate limiting plays a critical role in maintaining service quality and reliability. Even without malicious intent, a sudden spike in legitimate traffic—perhaps due to a marketing campaign, a viral event, or peak seasonal demand—can strain backend systems beyond their capacity. Databases might suffer from connection pool exhaustion, application servers might struggle with CPU contention, and network queues might overflow. By intelligently throttling incoming requests, rate limiting allows the system to shed excess load gracefully, preventing cascading failures and ensuring that the services remain responsive, albeit perhaps at a slightly reduced throughput, rather than collapsing entirely. It enables a controlled degradation of service rather than a complete outage, preserving user experience to the greatest extent possible during high-load events.
Finally, rate limiting serves as a protective shield for backend services. Often, a robust api gateway or load balancer sits in front of core application logic, databases, and microservices. While these frontend components can handle significant traffic, the downstream services often have more stringent capacity constraints. An authentication service might handle thousands of requests per second, but the database it queries for user credentials might only efficiently process hundreds. Rate limiting at the gateway level acts as a buffer, safeguarding these sensitive and often less scalable backend components from being overwhelmed, thereby maintaining the overall stability and integrity of the entire system architecture.
In the rapidly evolving landscape of microservices architectures, serverless computing, and public API economies, the sophistication of traffic management needs to keep pace. Simple, static limits are often insufficient. The choice of rate limiting algorithm, therefore, becomes a critical design decision, impacting not just the technical resilience of a system but also its economic viability and the satisfaction of its users. It is this profound necessity that underscores our deep dive into the nuanced world of sliding window rate limiting.
A Survey of Rate Limiting Algorithms: Unpacking the Tools of Traffic Control
Before we fully immerse ourselves in the intricacies of the Sliding Window Counter, it is beneficial to understand the landscape of rate limiting algorithms from which it emerged. Each method presents a unique approach to measuring and controlling request traffic, offering distinct advantages and disadvantages in terms of simplicity, accuracy, memory footprint, and ability to handle bursts. By examining these alternatives, we can better appreciate the specific problems the sliding window algorithm aims to solve and why it often proves to be a superior choice for many modern API applications.
1. Leaky Bucket Algorithm
The Leaky Bucket algorithm provides a clear analogy for understanding its operation. Imagine a bucket with a hole in the bottom that allows water to leak out at a constant rate. Requests entering the system are like water being poured into the bucket. If the bucket is not full, the water (request) is accepted. If the bucket is already full, any additional water (request) simply overflows and is discarded. The fixed leak rate ensures that the output rate of requests processed by the system remains constant, regardless of how bursty the input traffic might be.
- How it Works:
- Requests arrive and are added to a queue (the bucket).
- A worker process (the leak) processes requests from the queue at a fixed rate.
- If the queue is full, incoming requests are rejected.
- The bucket size determines how many requests can be queued up before rejection.
- The leak rate determines the maximum processing throughput.
- Pros:
- Smooth Output Rate: Guarantees a constant rate of request processing, which is excellent for protecting downstream systems that require a predictable input load.
- Simple to Understand: The analogy makes it intuitive.
- Good for Preventing Bursts: Effectively smooths out bursty traffic into a steady stream.
- Cons:
- Can Drop Legitimate Bursts: If a legitimate surge of requests exceeds the bucket's capacity, even if the average rate is within limits, many requests will be dropped. This can negatively impact user experience during peak, non-malicious usage.
- Doesn't Handle Bursty Traffic Efficiently: While it smooths bursts, it doesn't allow for any temporary increase in throughput beyond the fixed leak rate, which might be acceptable or even desirable in certain scenarios.
- Queueing Latency: Requests might experience delays if they sit in the queue, potentially leading to timeouts for real-time applications.
2. Fixed Window Counter Algorithm
The Fixed Window Counter is perhaps the simplest rate limiting algorithm to comprehend and implement. It operates by dividing time into discrete, non-overlapping windows (e.g., one minute, one hour). For each window, a counter tracks the number of requests made by a specific client. If the counter exceeds a predefined limit within the current window, subsequent requests from that client are rejected until the next window begins.
- How it Works:
- Define a window size (e.g., 60 seconds) and a maximum request limit per window.
- When a request arrives, check the current timestamp to determine which window it falls into.
- Increment a counter associated with that window and client.
- If the counter exceeds the limit, reject the request.
- At the start of a new window, the counter resets to zero.
- Pros:
- Simplicity: Very straightforward to implement with minimal computational overhead.
- Low Memory Usage: Only needs to store a single counter per client per active window.
- Cons:
- "Burst at the Edge" Problem: This is the most significant flaw. Consider a limit of 100 requests per minute. A client could make 100 requests in the last second of window 1 and another 100 requests in the first second of window 2. This totals 200 requests within a two-second period around the window boundary, effectively doubling the allowed rate and potentially overwhelming the system. This problem significantly undermines the algorithm's effectiveness in protecting against rapid bursts.
- Inaccurate Over Short Periods: While accurate over the full window, its instantaneous rate control can be highly inaccurate at the boundaries.
3. Token Bucket Algorithm
The Token Bucket algorithm is often considered an enhancement to the Leaky Bucket, offering more flexibility, particularly in handling bursts. Instead of queueing requests, it models the availability of "tokens" that represent permission to make a request.
- How it Works:
- A bucket has a maximum capacity for tokens.
- Tokens are added to the bucket at a fixed rate.
- When a request arrives, the system attempts to consume one token from the bucket.
- If a token is available, the request is processed, and the token is removed.
- If no tokens are available, the request is rejected or queued (depending on implementation).
- Tokens that exceed the bucket's capacity are discarded.
- Pros:
- Allows for Bursts: Unlike the Leaky Bucket, if the bucket has accumulated a sufficient number of tokens, a client can make a burst of requests up to the bucket's capacity. This is ideal for scenarios where occasional high-volume usage is legitimate.
- Flexible: The refill rate (average rate) and bucket size (burst capacity) can be independently configured, offering greater control.
- No Queueing Delay for Bursts: Requests processed immediately if tokens are available, reducing latency for bursts.
- Cons:
- Complexity: Slightly more complex to implement and tune than Fixed Window.
- Still Can Have Issues with Large Bursts: While better than Leaky Bucket, extremely large, sustained bursts beyond the bucket's capacity will still be rejected or throttled.
- Resource Overhead: Requires tracking tokens per client, potentially more state than Fixed Window.
4. Sliding Window Log Algorithm
The Sliding Window Log is the most precise of the discussed algorithms but also the most resource-intensive. Instead of just a counter, it stores a timestamp for every single request made by a client within the current window.
- How it Works:
- When a request arrives, its timestamp is recorded.
- To determine the current rate, the system filters out all timestamps older than the start of the current window (e.g., if the window is 60 seconds, it removes all timestamps older than
current_time - 60_seconds). - The number of remaining timestamps represents the number of requests in the current window.
- If this count exceeds the limit, the new request is rejected.
- Pros:
- Highly Accurate: Provides the most accurate representation of the request rate over any given sliding window, completely eliminating the "burst at the edge" problem.
- Perfect Burst Handling: Naturally accommodates legitimate bursts as long as the total count within the sliding window does not exceed the limit.
- Cons:
- High Memory Consumption: This is its major drawback. Storing a timestamp for every request, especially for high-traffic
APIs and long window durations, can quickly consume vast amounts of memory. For example, 1000 requests per second for a 60-second window means storing 60,000 timestamps per client. - Computational Overhead: Filtering and counting timestamps for every request can be CPU-intensive, especially with large numbers of stored timestamps.
- Not Scalable for High Volume: The memory and computational costs make it impractical for very high-throughput, fine-grained rate limiting across many clients.
- High Memory Consumption: This is its major drawback. Storing a timestamp for every request, especially for high-traffic
Introduction to Sliding Window Rate Limiting (Focus Algorithm)
Given the limitations of the previous algorithms—the "burst at the edge" problem of Fixed Window, the rigidity of Leaky Bucket, and the resource intensity of Sliding Window Log—there arose a need for a more balanced approach. The Sliding Window Counter algorithm emerges as a powerful solution, cleverly combining the efficiency of fixed window counters with the accuracy benefits of a sliding window. It aims to mitigate the "edge effect" without incurring the prohibitive memory costs of storing every request timestamp. By providing a robust and performant way to enforce API rate limits, it has become a cornerstone of traffic management in scalable, distributed systems, often implemented within a sophisticated api gateway to protect downstream services. This hybrid nature makes it a highly attractive option for most API governance scenarios, striking an optimal balance between precision and practical implementability.
Deconstructing the Sliding Window Counter Algorithm: A Hybrid Approach to Precision
The Sliding Window Counter algorithm represents a clever compromise, designed to overcome the significant "burst at the edge" vulnerability of the simple Fixed Window Counter, without incurring the exorbitant memory and computational costs associated with the highly accurate but demanding Sliding Window Log. It achieves this by employing a hybrid methodology, combining elements of both fixed window counting and a weighted average that "slides" over time. This approach offers a more accurate approximation of the true request rate within a rolling time frame, making it a robust choice for API traffic management.
Core Concept: Blending Efficiency with Accuracy
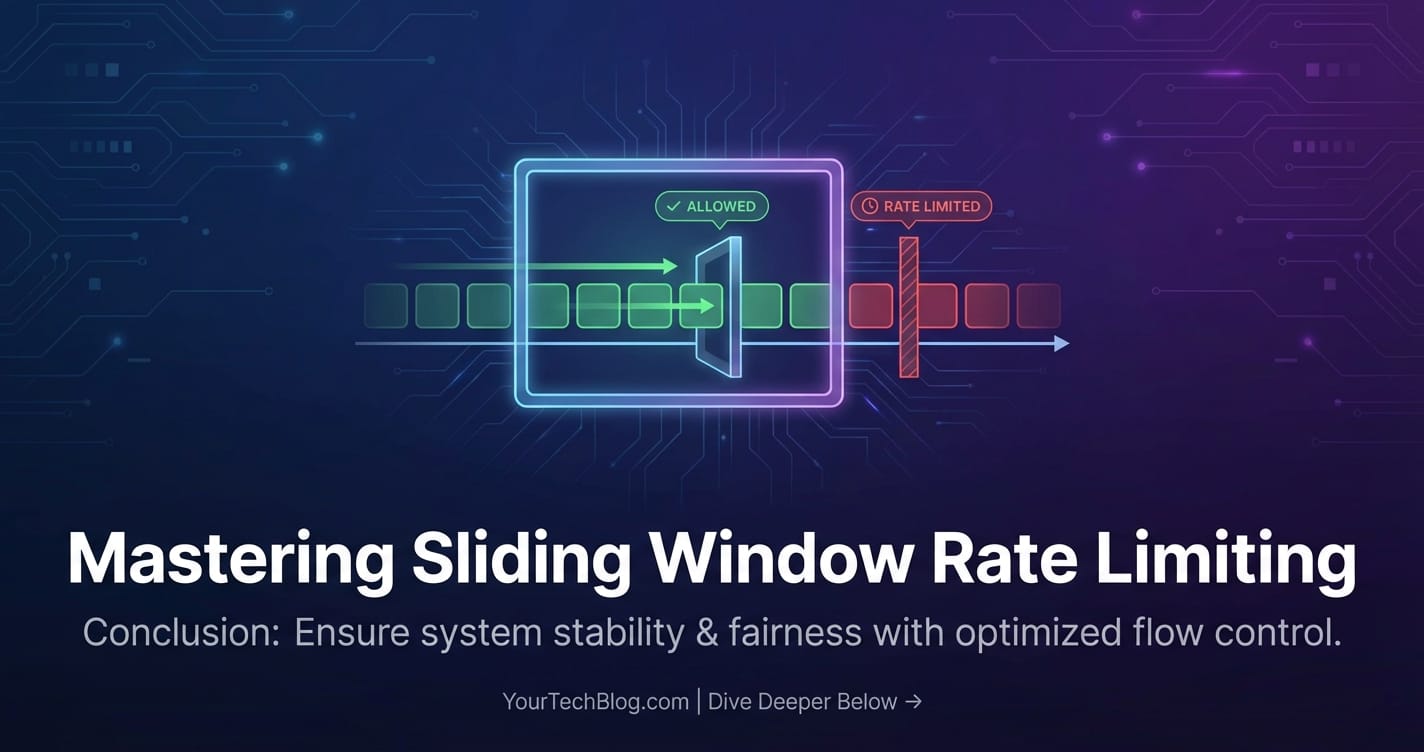
At its heart, the Sliding Window Counter operates by maintaining a counter for the current fixed time window, much like the Fixed Window algorithm. However, unlike the Fixed Window, when evaluating a new request, it doesn't just look at the current window's count. Instead, it also considers the requests from the previous fixed window, applying a weight to them based on how much of the previous window overlaps with the current "sliding" period. This weighted average gives an estimate of the request count within the actual sliding window, providing a much smoother and more accurate rate limiting experience.
Imagine a rate limit of 100 requests per minute. * The system divides time into one-minute fixed windows (e.g., 00:00-00:59, 01:00-01:59, etc.). * It keeps track of the request count for the current window (e.g., currentWindowCount). * It also keeps track of the request count for the previous window (e.g., previousWindowCount).
When a new request arrives at timestamp T: 1. Determine the current fixed window W_current and the previous fixed window W_previous. 2. Calculate the proportion of W_previous that overlaps with the current sliding window. For example, if T is 30 seconds into W_current, then 30 seconds of the W_previous window is still "relevant" to the sliding window, and 30 seconds of W_current is also relevant. 3. The estimated count for the sliding window is then: estimated_count = (previousWindowCount * overlap_percentage_with_previous_window) + currentWindowCount 4. If estimated_count exceeds the limit, the request is rejected. Otherwise, currentWindowCount is incremented, and the request is allowed.
Detailed Mechanics: A Step-by-Step Walkthrough
Let's break down the mechanics with a concrete example. Assume a rate limit of 100 requests per minute. The system uses 1-minute fixed windows.
- Window 1: Starts at
T=0:00, ends atT=0:59. Counter:C1. - Window 2: Starts at
T=1:00, ends atT=1:59. Counter:C2. - And so on.
Now, consider a request arriving at T = 1:30 (one minute and thirty seconds past the epoch, or 30 seconds into Window 2).
- Identify Current Window: The request falls into Window 2.
- Identify Previous Window: The previous window is Window 1.
- Calculate Overlap:
- The "sliding window" for this request spans from
T=0:30toT=1:30. - This sliding window overlaps with the last 30 seconds of Window 1.
- It also overlaps with the first 30 seconds of Window 2.
- The proportion of overlap with the previous window is
(time_elapsed_in_current_window / window_size). In our example,30 seconds / 60 seconds = 0.5. - The proportion of the previous window that is still relevant to the current sliding window is
1 - (time_elapsed_in_current_window / window_size). So,1 - 0.5 = 0.5. This0.5represents the weight we apply toC1.
- The "sliding window" for this request spans from
- Estimate Sliding Window Count: The estimated number of requests within the sliding 1-minute window (0:30 to 1:30) is calculated as:
EstimatedCount = (C1 * (1 - (current_time_in_window / window_size))) + C2In our example, atT=1:30(30 seconds into Window 2):EstimatedCount = (C1 * (1 - (30 / 60))) + C2EstimatedCount = (C1 * 0.5) + C2Let's sayC1(requests in Window 1) was 80, andC2(requests so far in Window 2) is 20.EstimatedCount = (80 * 0.5) + 20 = 40 + 20 = 60. - Decision: If
EstimatedCount(60) is less than or equal to the limit (100), the request is allowed, andC2is incremented to 21. IfEstimatedCounthad been, say, 105, the request would be rejected.
This formula effectively "slides" the window by incorporating a fractional part of the previous window's count. As time progresses within the current window, the weight applied to the previous window's count decreases, and the reliance on the current window's count increases.
Advantages over Other Algorithms
The Sliding Window Counter algorithm presents several compelling advantages that position it as a robust and frequently preferred choice:
- Mitigates the "Burst at the Edge" Problem: This is its primary strength. By accounting for the partial overlap of the previous window, it significantly smooths out the potential for double-dipping at window boundaries that plagues the Fixed Window Counter. A client cannot make 2N requests in 2 seconds if N is the limit for a 60-second window, because the algorithm will always consider requests from the immediately preceding time period, preventing such an instantaneous surge. This makes the rate limiting much more effective and reliable.
- More Memory-Efficient than Sliding Log: Unlike the Sliding Window Log, which needs to store individual timestamps for every single request, the Sliding Window Counter only needs to maintain two counters per client (one for the current window, one for the previous) and their respective timestamps. This drastically reduces memory overhead, making it practical for high-throughput
APIs and systems with many individual clients. - Provides a Smoother Rate Limiting Experience: The weighting mechanism means that the perceived rate limit adjusts more gradually than the abrupt resets of the Fixed Window algorithm. This results in a more predictable and fair experience for
APIconsumers, as their requests are less likely to be unexpectedly throttled simply because of where they fall within an arbitrary fixed window boundary. - Better Handles Bursty Traffic While Respecting Limits: While not as perfectly precise as the Sliding Window Log, it offers a good balance. It allows for reasonable bursts within the sliding window, similar to the Token Bucket, but without the complexity of managing tokens explicitly. If a client has been quiet for a while, their "estimated count" will be low, allowing them to burst. If they sustain a high rate, the estimated count will quickly hit the limit.
Disadvantages and Complexities
Despite its advantages, the Sliding Window Counter is not without its own set of challenges:
- Slightly More Complex to Implement than Fixed Window: While not as complex as the Sliding Log, it requires careful calculation of timestamps and weighted averages, which introduces more logic than a simple increment-and-reset counter. This complexity can be a source of bugs if not implemented meticulously, especially in distributed environments.
- Requires Careful Synchronization in Distributed Environments: When multiple
api gatewayinstances or application servers are processing requests and contributing to the same rate limit, ensuring thatC1andC2(and their respective start times) are accurately and consistently updated across all instances becomes critical. This typically necessitates a centralized, highly available data store (like Redis) and careful use of atomic operations or distributed locks to prevent race conditions. Without proper synchronization, the counters can become inconsistent, leading to inaccurate rate limiting. - Still an Approximation, Not Perfectly Precise as Sliding Log: It's important to remember that the Sliding Window Counter provides an estimate of the true rate within the sliding window, especially when traffic patterns are highly erratic. The precision depends on the fixed window size relative to the sliding window duration. While significantly better than Fixed Window, it's not the exact real-time count that the Sliding Window Log provides. For most practical
APIuse cases, this approximation is more than sufficient, but in extremely sensitive scenarios requiring absolute real-time precision, the Sliding Log (with its associated costs) might still be preferred.
In summary, the Sliding Window Counter algorithm strikes an impressive balance, delivering significantly improved accuracy over the Fixed Window Counter while remaining far more resource-efficient than the Sliding Window Log. Its ability to intelligently handle requests across window boundaries makes it an excellent choice for a wide array of API rate limiting requirements, particularly when integrated into a high-performance api gateway or api management platform.
APIPark is a high-performance AI gateway that allows you to securely access the most comprehensive LLM APIs globally on the APIPark platform, including OpenAI, Anthropic, Mistral, Llama2, Google Gemini, and more.Try APIPark now! 👇👇👇
Implementing Sliding Window Rate Limiting: From Concept to Code
Translating the theoretical mechanics of the Sliding Window Counter into a functional, robust, and scalable implementation requires careful consideration of several key components and architectural choices. The goal is to build a system that can accurately track request rates, enforce limits consistently, and perform efficiently under varying load conditions.
Key Components for Implementation
- Counter Storage: The effectiveness of any rate limiting algorithm hinges on its ability to store and retrieve counters quickly and reliably. For the Sliding Window Counter, we need to track at least two counters per client (or per unique identifier being rate-limited): the count for the current fixed window and the count for the previous fixed window.
- In-Memory Data Structures (e.g., HashMaps, AtomicIntegers):
- Pros: Extremely fast, minimal latency. Suitable for single-instance applications or when rate limits are local to a specific service instance.
- Cons: Not suitable for distributed systems. If you have multiple application instances, each instance will have its own independent counter, leading to inconsistent and ineffective rate limiting. If an instance restarts, all counters are lost.
- Use Case: Local, per-process rate limiting (e.g., preventing a single worker thread from overwhelming an internal queue), or very small-scale deployments.
- Redis:
- Pros: The de facto standard for distributed rate limiting. Redis is an in-memory data store known for its exceptional speed, atomicity, and versatile data structures (strings, hashes, sorted sets). Its
INCRcommand is atomic, making it ideal for distributed counters. It can persist data to disk, offering durability. - Cons: Introduces network latency (though usually minimal). Requires managing a Redis cluster for high availability and scalability.
- Use Case: The most common and recommended choice for production-grade distributed rate limiting. It can store the
currentWindowCount,previousWindowCount, and their respectivewindowStartTimeefficiently.
- Pros: The de facto standard for distributed rate limiting. Redis is an in-memory data store known for its exceptional speed, atomicity, and versatile data structures (strings, hashes, sorted sets). Its
- Memcached:
- Pros: Very fast key-value store, good for caching.
- Cons: Lacks atomic operations for incrementing counters reliably in a distributed fashion. Primarily a cache, not designed for persistence, so data loss on restart is expected. Less suitable for complex rate limiting logic than Redis.
- Use Case: Less ideal for the Sliding Window Counter, but could be used if atomicity is handled at the application layer, or for very simple rate limits where occasional inaccuracy is acceptable.
- In-Memory Data Structures (e.g., HashMaps, AtomicIntegers):
- Timestamp Management: Accurate timestamping is crucial for determining the current fixed window, the previous fixed window, and the proportion of overlap.
- Server-Side Clock: Relying on the system clock of the server processing the request is standard. However, in a distributed environment, clock synchronization (e.g., via NTP) across all servers is paramount. Skewed clocks can lead to inconsistent rate limiting decisions.
- Storing Window Start Times: When storing counters in Redis, it's good practice to store the
startTimeof the current and previous windows alongside their counts. This ensures that even if agatewayinstance temporarily goes offline and restarts, it can pick up the correct window context.
- Synchronization for Distributed Counters: In a distributed system, multiple
api gatewayinstances might attempt to update the same rate limit counter concurrently. Without proper synchronization, race conditions can lead to incorrect counts.- Atomic Operations: Redis's
INCRandEXPIREcommands are atomic, which makes simple counter increments safe. However, the full logic for the Sliding Window Counter involves reading multiple values (current count, previous count, timestamps), performing a calculation, and then writing back an updated count. This sequence of operations needs to be atomic. - Lua Scripts in Redis: The most robust way to implement the full Sliding Window Counter logic atomically in Redis is using Lua scripts. A single Lua script can encapsulate the entire rate limiting logic (read current/previous counts and timestamps, calculate estimated rate, decide to allow/reject, increment current count if allowed, set/update window start times/expirations) and execute it as a single, atomic operation on the Redis server. This eliminates race conditions that would arise from multiple client-server round trips.
- Distributed Locks: While possible, using explicit distributed locks (e.g., Redlock) for every rate limit check adds significant overhead and complexity. Atomic Lua scripts are generally preferred for performance-critical rate limiting.
- Atomic Operations: Redis's
- Decision Logic: This is the heart of the algorithm, where the calculation
EstimatedCount = (previousWindowCount * overlap_percentage) + currentWindowCountoccurs. This logic should be encapsulated in a highly performant function.- Edge Case Handling: What happens when a window just starts, and
previousWindowCountis zero or expired? The logic needs to handle these transitions gracefully. Typically, if the previous window's key in Redis has expired, its count is treated as zero. If the current window's key hasn't been created yet, it's initialized to zero. - Time Unit Conversion: Ensure consistent time units (e.g., all in milliseconds or seconds) throughout the calculations to avoid errors.
- Edge Case Handling: What happens when a window just starts, and
Language/Framework Specific Implementations (Examples)
Many programming languages and frameworks offer libraries or patterns to implement rate limiting, some specifically supporting the sliding window mechanism.
- Java:
- Guava RateLimiter: Primarily a Token Bucket implementation, excellent for single-process rate limiting. For distributed sliding window, you'd integrate it with Redis.
- Resilience4j: A fault tolerance library that includes a
RateLimitermodule. It supports different algorithms, and its configuration can be adapted to simulate aspects of sliding window when combined with external state management. - Custom Implementation with Redis Clients (Jedis, Lettuce): The most common approach for a distributed sliding window in Java is to write a custom implementation that interacts with Redis using atomic Lua scripts.
- Go:
golang.org/x/time/rate: Go's standard library provides a token bucket rate limiter.- Third-party libraries and Custom Implementations: For sliding window, developers often implement it directly, leveraging Redis clients like
go-redisand embedding Lua scripts. - Gin framework middleware: Middleware can be written to integrate rate limiting logic before requests reach the handlers.
- Python:
ratelimitlibrary: A decorator-based library that can be configured for various rate limiting strategies.limitslibrary: Provides a generic rate limiting framework with support for different storage backends (Redis, Memcached, etc.).asyncio-throttle: For asynchronous Python applications.- Custom with
redis-py: Similar to Java and Go, integrating with Redis and Lua scripting for distributed sliding window.
- Node.js:
express-rate-limit: A popular middleware for Express.js that supports various rate limiting strategies, including memory store and Redis store. It can be configured to achieve sliding window behavior.rate-limiter-flexible: A comprehensive library for Node.js that supports many algorithms, including sliding window, and various storage options (Redis, Memcached, MongoDB, etc.). It's highly configurable and production-ready.- Custom with
ioredis: Implementing the logic with Redis Lua scripts directly.
Centralized vs. Distributed Implementation
The choice between a centralized and distributed implementation profoundly impacts scalability, resilience, and complexity.
- Centralized Implementation:
- Concept: A single service or a single instance of an
api gatewayis responsible for all rate limiting decisions. All requests flow through this single point. - Pros: Simplicity of implementation. No need for distributed synchronization.
- Cons:
- Single Point of Failure: If the centralized component goes down, rate limiting stops, potentially exposing backend services.
- Scalability Bottleneck: The centralized component itself can become a performance bottleneck as request volume grows, limiting the overall throughput of your
APIs. - High Latency: Every request must make a round trip to this central service, potentially adding latency.
- Use Case: Small-scale
APIs, internal services where traffic is low and predictable, or as a component within a larger, sharded distributed system.
- Concept: A single service or a single instance of an
- Distributed Implementation:Strategies for Distributed Counting (e.g., Redis increment, sorted sets): * Redis Hashes + Atomic Increments/Expres: For each client being rate limited, store its current and previous window counts, along with their start timestamps, in a Redis Hash. Use Lua scripts to atomically read, calculate, and update these values. The
EXPIREcommand can be used to automatically clean up old window keys. * Redis Sorted Sets (for Sliding Window Log variant): While not strictly the Sliding Window Counter, it's worth noting that a perfect Sliding Window Log could be implemented with Redis Sorted Sets, where the score is the timestamp, andZRANGEBYSCOREcan query requests within a time range. However, this still faces the memory challenges of the Sliding Log for high volumes. The Sliding Window Counter aims to avoid this complexity by abstracting individual request timestamps into two summary counts.- Concept: Rate limiting logic is distributed across multiple instances of your
api gatewayor application servers. These instances share a common, highly available, and scalable state store (typically Redis) for their counters. - Pros:
- Scalability: Can handle extremely high volumes of requests by horizontally scaling the
gatewayinstances. - Resilience: No single point of failure (assuming the state store is also highly available). If one
gatewayinstance fails, others continue operating. - Lower Latency:
Gatewayinstances can be geographically distributed or co-located with services, reducing network hops to the rate limiting decision point.
- Scalability: Can handle extremely high volumes of requests by horizontally scaling the
- Cons:
- Complexity: Requires careful design for consistency, atomicity, and synchronization, often involving Redis Lua scripts.
- Operational Overhead: Managing and monitoring a distributed state store (like a Redis cluster).
- Use Case: Essential for public-facing
APIs, microservices architectures, cloud deployments, and any system requiring high availability and scalability. This is the predominant approach for modernAPIs.
- Concept: Rate limiting logic is distributed across multiple instances of your
Integration with an API Gateway
An api gateway is the quintessential location for implementing rate limiting. It acts as the single entry point for all API traffic, making it the ideal choke point for applying policies consistently and efficiently before requests ever reach your precious backend services.
Why an api gateway is ideal for rate limiting:
- Centralized Policy Enforcement: All rate limiting rules (per IP, per
APIkey, per endpoint, etc.) can be configured and enforced in one place, simplifying management and ensuring consistency across allAPIs. - Decoupling from Business Logic: Rate limiting is an infrastructure concern, not core business logic. Implementing it at the
gatewaykeeps your application code clean and focused on its primary responsibilities. - Performance: Dedicated
gatewaysolutions are often optimized for high-performance traffic handling, allowing them to apply rate limits with minimal overhead. - Visibility and Monitoring:
Gateways typically offer robust logging and monitoring capabilities, providing insights into traffic patterns, rejected requests, and overallAPIhealth. - Protocol Agnosticism: A
gatewaycan apply rate limits regardless of the underlying protocol of your backend services (REST, GraphQL, gRPC), providing a unified control plane.
For organizations seeking robust API management solutions, an open-source AI gateway like APIPark can provide not just sophisticated rate limiting mechanisms but also a comprehensive suite of tools for API lifecycle management, traffic forwarding, load balancing, and more, integrating seamlessly into your infrastructure. Platforms like APIPark streamline the complexities of API governance, allowing developers and enterprises to focus on building value rather than managing infrastructure minutiae. Leveraging such a gateway allows for easy configuration of sliding window limits, often through declarative policies, without needing to write custom rate limiting code within each microservice.
Implementing Sliding Window Rate Limiting effectively requires a thoughtful approach to storage, synchronization, and placement within your architecture. By choosing the right tools (like Redis with Lua scripts) and integrating it into a strategic location like an api gateway, you can build a highly resilient and performant API infrastructure capable of withstanding diverse traffic patterns and protecting your valuable backend resources.
Advanced Considerations and Best Practices for Sliding Window Rate Limiting
Beyond the core mechanics of the Sliding Window Counter, effectively deploying and managing rate limiting in a production environment involves a host of advanced considerations and adherence to best practices. These elements ensure that your rate limiting strategy is not only technically sound but also aligns with business objectives, enhances user experience, and remains adaptable to evolving needs.
Granularity of Limits: Tailoring Control to Specific Needs
A one-size-fits-all approach to rate limiting is rarely optimal. Different APIs, resources, and users often warrant distinct access policies. Granularity refers to the level at which rate limits are applied, allowing for finely tuned control:
- Per IP Address: The simplest form, useful for broad DoS protection. However, multiple users behind a NAT or proxy will share a single IP, potentially causing legitimate users to be throttled unfairly. Also, malicious actors can spoof IPs or use botnets with many IPs.
- Per User/API Key/Client ID: The most common and generally recommended approach for public
APIs. This ties limits directly to an authenticated entity, providing fair usage. EachAPIconsumer gets their allocated quota. This requires authentication to occur before rate limiting decisions are made, often at theapi gateway. - Per Endpoint/Resource: Some
APIendpoints are more resource-intensive than others. APOST /usersendpoint might have a lower limit than aGET /productsendpoint. Applying limits per endpoint prevents specific heavy operations from overwhelming the system. - Per Tenant/Organization: In multi-tenant systems, limits can be applied to an entire organization's usage, rather than individual users, providing flexibility for teams.
- Combined Limits: Often, a combination is best. For example, a global IP limit to catch initial DoS attempts, followed by a stricter per-user/API key limit for authenticated access, and even finer-grained limits per critical endpoint. The
api gatewayis perfectly positioned to manage these layered policies.
Handling Over-Limit Requests: Graceful Rejection and User Guidance
When a client exceeds their rate limit, how the system responds is crucial for both security and user experience.
- Returning 429 Too Many Requests: This is the standard HTTP status code (RFC 6585) for indicating that the user has sent too many requests in a given amount of time. It clearly signals the reason for rejection to the client.
- Providing
Retry-AfterHeaders: To guide clients on when they can retry, the429response should include aRetry-Afterheader. This header specifies either the number of seconds to wait before making a new request or a specific timestamp (in HTTP-date format) when the client can retry. This is vital forAPIconsumers to implement exponential backoff and retry logic gracefully, reducing unnecessary retries and further load. - Queueing Requests (Conditional): In some very specific scenarios (e.g., non-real-time batch processing where eventual consistency is acceptable), rather than outright rejecting, requests that exceed limits might be temporarily queued. This adds complexity and potential latency but ensures no data loss. This is rarely suitable for interactive
APIs. - Throttling vs. Outright Rejection: Throttling implies slowing down the client's requests (e.g., by introducing artificial delays or prioritizing lower-priority requests), while rejection simply denies them. Sliding Window typically rejects once the limit is hit, but a
gatewaymight be configured to queue or delay internally if desirable. MostAPIs opt for rejection due to its simplicity and clear contract.
Monitoring and Alerting: Vigilance is Key
A rate limiter is only as effective as your ability to monitor its performance and react to issues. Robust observability is non-negotiable.
- Key Metrics to Track:
- Rejected Requests (429s): The number and rate of requests being rejected due to rate limits. High numbers might indicate misconfigured clients, legitimate high demand, or an attack.
- Current Request Rates: Track the rate for each significant rate limit (e.g.,
requests_per_minute_by_user). - Near-Limit Thresholds: Monitor when clients are approaching their limits (e.g., 80% or 90% utilization).
- Rate Limiter Internal Errors: Any failures within the rate limiting mechanism itself (e.g., Redis connection issues).
- Tools and Dashboards: Integrate rate limiting metrics into your existing monitoring tools (e.g., Prometheus, Grafana, Datadog). Create dashboards that visualize
APItraffic, rate limit hits, and system health. - Setting up Alerts for Critical Thresholds:
- Alert when 429 errors spike unexpectedly for a particular client or globally.
- Alert when system-wide
APIrequest rates approach capacity limits, even if not yet hitting rate limits. - Alert for any errors in the rate limiting infrastructure itself (e.g., Redis latency or unavailability).
- Proactive alerts can notify teams before a full outage occurs or a malicious attack succeeds.
Testing Rate Limiters: Ensuring Robustness
Thorough testing is essential to validate that your rate limits function as intended under various conditions.
- Unit Tests: Test the core rate limiting logic in isolation (e.g., the Lua script in Redis, or the calculation function).
- Integration Tests: Verify that the rate limiter integrates correctly with your
api gatewayor application code. - Load Tests: Crucially, simulate high traffic and burst scenarios to ensure the rate limiter accurately throttles requests and that the underlying infrastructure (e.g., Redis) can handle the load. Test the "burst at the edge" scenario specifically to confirm the Sliding Window Counter effectively mitigates it.
- Edge Cases: Test what happens at the exact boundary of a window, at the exact limit, and immediately after the limit is hit. Test with invalid
APIkeys or missing headers to ensure proper fallback.
Bypassing Rate Limits (Legitimate Cases): Exemptions and Whitelisting
Not all requests should be subjected to the same rate limits. There are legitimate reasons for some clients or services to bypass them.
- Internal Services/Microservices: Internal service-to-service communication within your trusted network often doesn't need to be rate-limited, as these services are typically designed to handle high internal loads and are already part of a controlled ecosystem.
- Trusted Partners/Premium Tiers: Specific partners or premium
APIsubscribers might be granted higher or unlimited rate limits as part of their service level agreement (SLA). - Administrative Actions: Tools or users performing administrative tasks (e.g., data migrations, maintenance scripts) might require elevated access without arbitrary limits.
- Implementation: An
api gatewaytypically supports whitelisting IP addresses,APIkeys, or specific internal routes to bypass rate limits.
Impact on User Experience: Communication and Graceful Degradation
Rate limiting, by its nature, can disrupt users. How this disruption is managed is key to preserving a positive user experience.
- Clear Documentation for API Consumers: Explicitly document your rate limiting policies (limits, window sizes, error responses,
Retry-Afterheader usage) in yourAPIdocumentation. Educate developers on best practices for handling 429 responses and implementing backoff strategies. - Graceful Degradation: Design your client applications to handle 429 responses gracefully. Instead of crashing or displaying a generic error, clients should ideally pause, wait, and retry, or inform the user that the service is temporarily busy. This prevents a bad
APIexperience from translating into a terrible user experience. - Informative Error Messages: Beyond just a 429 status code, provide a clear, concise error message in the response body explaining why the request was throttled and what actions the client can take.
Comparative Algorithm Overview Table
To summarize the trade-offs, here's a comparative overview of the discussed rate limiting algorithms:
| Feature / Algorithm | Fixed Window Counter | Token Bucket | Sliding Window Counter | Sliding Window Log |
|---|---|---|---|---|
| Simplicity | High | Medium | Medium | Low |
| Accuracy | Low (prone to edge bursts) | Medium (depends on burst capacity) | High (good approximation) | Very High |
| Memory Usage | Low | Low | Medium (two counters + timestamps) | High (many timestamps) |
| Burst Handling | Poor | Good (allows controlled bursts) | Excellent (mitigates edge effect) | Excellent |
| Distributed Readiness | High (simple counters) | Medium (state sync needed) | Medium (requires atomic ops/Lua) | Low (high memory sync) |
| Main Problem | "Burst at the edge" effect | Complex tuning for optimal burst vs. average | Implementation complexity (atomic operations) | High memory and computational cost |
| Common Use Case | Simple internal services, initial broad protection | Flexible APIs needing controlled bursts |
Most public and internal APIs requiring good accuracy/efficiency |
Very high-precision, low-volume scenarios (niche) |
By meticulously considering these advanced aspects and adopting best practices, you can deploy a Sliding Window Rate Limiter that is not only effective in protecting your systems but also fair to your users, robust against attacks, and operationally sustainable.
Use Cases and Real-World Scenarios for Sliding Window Rate Limiting
The versatility and balanced performance of the Sliding Window Counter algorithm make it an excellent choice for a wide array of real-world applications across various industries and technical architectures. Its ability to accurately control traffic while efficiently managing resources addresses critical needs in modern distributed systems. Let's explore some prominent use cases where sliding window rate limiting proves invaluable.
1. Public APIs (e.g., Social Media, Payment Processors, Cloud Services)
Public APIs are perhaps the most common and critical area where robust rate limiting is indispensable. Platforms like Twitter, Stripe, GitHub, and various cloud service providers expose APIs that are consumed by millions of developers and applications.
- Scenario: A large social media platform offers an
APIfor third-party applications to retrieve user data or post updates. Without rate limits, a single misconfigured application or a malicious scraper could rapidly exhaust the platform's resources, impacting all otherAPIconsumers and the core user experience. - Sliding Window Advantage: A sliding window ensures that
APIconsumers can make, say, 180 requests per 3-minute window without encountering the "burst at the edge" problem. This allows developers to consume theAPIefficiently and fairly, without being unjustly throttled for making a legitimate burst of requests around an arbitrary minute boundary. It also protects the platform from rapid, sustained data scraping attempts which might look legitimate over a single fixed window but clearly exceed the rate when viewed over a sliding period. - Implementation: Typically enforced at the
api gatewaylevel (e.g., using Nginx, Envoy, or a commercialapi gatewaysolution) based onAPIkeys, OAuth tokens, or client IDs.
2. Microservice Architectures
In architectures composed of numerous independent microservices communicating over networks, rate limiting is essential for inter-service communication to prevent cascading failures.
- Scenario: An e-commerce platform has dozens of microservices: inventory, pricing, user authentication, order processing, recommendation engine, etc. A sudden spike in requests to the product catalog service, perhaps due to a flash sale, could overwhelm the downstream inventory database, which in turn could lead to timeouts in the order processing service, eventually bringing down the entire system.
- Sliding Window Advantage: Implementing sliding window rate limits on the inbound calls to critical services (e.g., database access layers, inventory update services, payment gateways) protects them from being overloaded by upstream services. If the recommendation engine attempts to fetch too many product details too quickly, the product catalog service can gracefully throttle it without impacting other services. This helps in fault isolation and maintains the stability of the overall system.
- Implementation: Rate limits can be applied at the service mesh layer (e.g., Istio, Linkerd) or within each service itself (using a shared Redis cluster for distributed counters), controlling the
APIcalls between internal services.
3. Authentication and Authorization Services
Authentication APIs are frequently targeted by brute-force attacks. Rate limiting is a crucial defense mechanism here.
- Scenario: A user authentication service provides an
APIendpoint for login attempts. A malicious actor could attempt to guess passwords by rapidly sending login requests with different credentials. - Sliding Window Advantage: A sliding window rate limit (e.g., 5 failed login attempts per IP address or username within a 5-minute sliding window) is highly effective. It prevents an attacker from making bursts of attempts at window boundaries. If an attacker tries 5 passwords at
T=0:59and then immediately another 5 atT=1:00with a fixed window, they get 10 attempts in 2 seconds. With sliding window, the prior 5 attempts are still considered relevant, throttling the attacker more effectively. This makes brute-forcing significantly harder and slower. - Implementation: Implemented directly within the authentication service or, more commonly, by an
api gatewayprotecting the authenticationAPIs.
4. E-commerce Platforms (Checkout, Search, Product Feeds)
High-traffic e-commerce operations often face peak demand during sales events or holidays.
- Scenario: During a Black Friday sale, thousands of users simultaneously try to add items to their cart and proceed to checkout. The checkout
APImight involve complex logic, database transactions, and integrations with payment gateways and inventory systems, making it highly sensitive to overload. Similarly, heavy usage of the searchAPIor product feedAPIcan strain backend databases. - Sliding Window Advantage: Sliding window limits on checkout
APIs (e.g., 2 successful checkouts per user per 5 minutes) prevent accidental double-submits or bot-driven checkout attempts. For searchAPIs, limits (e.g., 60 searches per user per minute) ensure that the search index and database aren't overwhelmed by excessively rapid queries, maintaining responsiveness for all users. - Implementation: At the
api gatewayfor public-facingAPIs, or within the specific microservices (e.g., checkout service, search service) for internal traffic control, ensuring that the critical business processes remain stable.
5. Data Scraping Prevention
Web scraping bots can hammer APIs to extract large volumes of data, leading to excessive resource consumption and potentially intellectual property theft.
- Scenario: A news website or a real estate portal has
APIs to retrieve articles or property listings. Bots are designed to make requests as quickly as possible to download all available data. - Sliding Window Advantage: By detecting and throttling clients (identified by IP, user agent, or other headers) that exceed typical human browsing patterns within a sliding window, these bots can be effectively slowed down or blocked. The sliding window is superior here because bots often try to mimic human behavior or spread requests just enough to evade simple fixed window detection. The sliding window's continuous evaluation catches these patterns more reliably.
- Implementation: Primarily at the
api gatewayor CDN edge, often integrated with WAF (Web Application Firewall) capabilities for bot detection and mitigation.
6. User Experience Protection and Fair Usage
Beyond protecting the system, rate limiting can directly contribute to a better experience for legitimate users by enforcing fairness.
- Scenario: A comment section
APIallows users to post comments. Without rate limiting, a single user could spam hundreds of comments in seconds, degrading the quality of the discussion for everyone. - Sliding Window Advantage: A sliding window limit (e.g., 5 comments per user per minute) allows legitimate users to post normally while quickly identifying and throttling spammers. The sliding nature ensures that a user can't circumvent the limit by timing their posts precisely at window boundaries. This fosters a healthier and more engaging user community.
- Implementation: At the
api gatewayor within the application service responsible for handling user-generated content.
In conclusion, the Sliding Window Counter algorithm provides a robust, adaptable, and efficient solution for managing API traffic across a broad spectrum of use cases. Its ability to mitigate common pitfalls of simpler algorithms, while remaining performant and scalable, makes it an indispensable tool for any organization operating modern, distributed APIs. By carefully integrating it into their architecture, whether at the api gateway, service mesh, or individual service level, businesses can ensure the stability, security, and fairness of their digital services.
Conclusion: Orchestrating Resilience with Sliding Window Rate Limiting
The relentless currents of digital traffic pose a perpetual challenge to the stability and security of modern API-driven systems. From safeguarding against malicious Denial-of-Service attacks to ensuring equitable resource distribution among legitimate consumers, the necessity of robust traffic management is undeniable. Throughout this comprehensive exploration, we have underscored why rate limiting is not merely a technical add-on but a foundational pillar of resilient API architectures, and how the Sliding Window Counter algorithm distinguishes itself as a sophisticated and highly effective solution within this critical domain.
Our journey began by examining the fundamental imperative of rate limiting, highlighting its crucial role in preventing system overloads, controlling costs, and maintaining an acceptable quality of service. We then surveyed the landscape of common rate limiting algorithms, from the predictable Leaky Bucket and the simple Fixed Window Counter to the flexible Token Bucket and the precise yet memory-intensive Sliding Window Log. This comparative analysis laid the groundwork for appreciating the ingenious hybrid approach of the Sliding Window Counter.
We meticulously deconstructed the Sliding Window Counter algorithm, revealing its clever mechanism of blending current window counts with a weighted portion of the previous window's activity. This ingenious design effectively neutralizes the notorious "burst at the edge" problem that plagues simpler fixed-window methods, while simultaneously offering significantly better memory efficiency than the brute-force Sliding Window Log. The result is a system that provides a smooth, accurate approximation of actual request rates, capable of gracefully handling bursty traffic without succumbing to either resource exhaustion or unfair throttling.
Implementing this powerful algorithm, particularly in distributed environments, necessitates careful attention to detail. We discussed the pivotal role of high-performance, atomic storage solutions like Redis, often leveraged with Lua scripting to ensure consistency and prevent race conditions across multiple api gateway instances. The strategic placement of rate limiters within an api gateway emerged as a best practice, centralizing policy enforcement, enhancing performance, and decoupling infrastructure concerns from core business logic. As noted, sophisticated platforms such as APIPark exemplify how an open-source AI gateway can integrate such advanced rate limiting capabilities alongside comprehensive API lifecycle management, offering a holistic solution for modern API governance.
Furthermore, we delved into advanced considerations that transform a basic rate limiter into a truly robust system. This included the importance of granular limit definitions, graceful handling of over-limit requests (with 429 Too Many Requests and Retry-After headers), and the indispensable role of vigilant monitoring and alerting. We emphasized thorough testing, the judicious application of bypass mechanisms for trusted entities, and the profound impact of clear communication and graceful degradation on the overall user experience.
Finally, a review of diverse real-world use cases — from protecting public APIs and safeguarding microservice architectures to defending authentication services and preventing data scraping — illustrated the pervasive applicability and tangible benefits of the Sliding Window Counter. Across these varied scenarios, its ability to ensure fairness, security, and stability consistently proves invaluable.
In mastering Sliding Window Rate Limiting, developers and architects gain a powerful tool for orchestrating resilience within their digital ecosystems. It is a testament to thoughtful engineering, providing a balanced solution that respects both system integrity and user interaction. As the landscape of APIs continues to expand and evolve, the principles and practices outlined herein will remain crucial for building scalable, secure, and sustainable digital services that can confidently navigate the ever-increasing demands of the internet.
Frequently Asked Questions (FAQs)
1. What is the main advantage of the Sliding Window Counter algorithm over the Fixed Window Counter? The main advantage is its ability to mitigate the "burst at the edge" problem. The Fixed Window Counter allows a client to effectively double their allowed rate if they make requests at the very end of one window and the very beginning of the next. The Sliding Window Counter addresses this by considering a weighted average of the previous window's count along with the current window's count, providing a more accurate and consistent rate limit over the actual sliding time period and preventing such artificial bursts.
2. Why is Redis often recommended for implementing distributed Sliding Window Rate Limiting? Redis is recommended due to its exceptional speed, in-memory nature, and support for atomic operations. Its INCR command and, more importantly, its ability to execute Lua scripts atomically are crucial. A single Lua script can encapsulate the entire logic for reading counters and timestamps, performing the sliding window calculation, making a decision, and updating the counters, all as one indivisible operation. This prevents race conditions in distributed environments where multiple api gateway instances might concurrently try to update the same rate limit.
3. What happens when a client exceeds their rate limit using the Sliding Window Counter? When a client exceeds their rate limit, the api gateway or service enforcing the limit should typically respond with an HTTP 429 Too Many Requests status code. It is also best practice to include a Retry-After HTTP header in the response, which tells the client either how many seconds they should wait before retrying or a specific timestamp when they can make another request. This allows API consumers to implement graceful retry logic and avoid further taxing the system.
4. Can Sliding Window Rate Limiting protect against all types of attacks? While highly effective against many forms of abuse, particularly DoS/DDoS and brute-force attacks that rely on overwhelming a single endpoint or client, Sliding Window Rate Limiting is not a silver bullet. It's a critical layer in a multi-layered security strategy. Advanced, sophisticated attacks (e.g., highly distributed, low-and-slow attacks, or attacks exploiting logical vulnerabilities) may require additional defenses such as Web Application Firewalls (WAFs), bot detection services, IP reputation systems, and advanced anomaly detection.
5. How does an api gateway contribute to effective Sliding Window Rate Limiting? An api gateway is the ideal location for enforcing Sliding Window Rate Limiting because it acts as the single entry point for all API traffic. This allows for centralized policy enforcement, meaning all rate limits can be configured and managed in one place, ensuring consistency across your entire API landscape. Gateways are also optimized for high-performance traffic handling, can decouple rate limiting logic from your core business services, and often provide robust monitoring and logging capabilities for API traffic and rate limit hits. Platforms like APIPark, an open-source AI gateway, exemplify how a gateway can streamline the implementation and management of sophisticated rate limiting strategies.
🚀You can securely and efficiently call the OpenAI API on APIPark in just two steps:
Step 1: Deploy the APIPark AI gateway in 5 minutes.
APIPark is developed based on Golang, offering strong product performance and low development and maintenance costs. You can deploy APIPark with a single command line.
curl -sSO https://download.apipark.com/install/quick-start.sh; bash quick-start.sh

In my experience, you can see the successful deployment interface within 5 to 10 minutes. Then, you can log in to APIPark using your account.

Step 2: Call the OpenAI API.