Mastering Sliding Window Rate Limiting for Robust Systems



The digital landscape is a vibrant, ever-expanding ecosystem where applications and services strive for seamless interaction and high availability. From burgeoning startups to colossal enterprises, the reliance on Application Programming Interfaces (APIs) as the connective tissue of modern software architectures is absolute. These APIs facilitate everything from mobile app functionalities and third-party integrations to complex microservices communications, underpinning the very fabric of our connected world. However, this omnipresence also exposes them to a myriad of challenges, chief among them the relentless, often unpredictable, onslaught of requests. Uncontrolled access can quickly transform a robust service into a fragile one, susceptible to overload, abuse, and even catastrophic failure. This is where the strategic implementation of rate limiting emerges not merely as a feature, but as a fundamental necessity for system resilience and stability.
Rate limiting, at its core, is a defense mechanism, a sophisticated gatekeeper designed to regulate the flow of traffic to your backend services, databases, and APIs. It ensures fair usage, protects against malicious attacks such as Distributed Denial of Service (DDoS) or brute-force attempts, and safeguards valuable computing resources from being monopolized by a few overly zealous or abusive clients. While several algorithms exist to tackle this challenge, the Sliding Window Rate Limiting technique stands out as a particularly effective and nuanced approach. It offers a superior balance between accuracy and efficiency, addressing many of the shortcomings inherent in simpler, more traditional methods. In the intricate world of distributed systems and microservices, where an API gateway acts as the crucial first line of defense, understanding and mastering sliding window rate limiting is not just beneficial—it's imperative for building systems that are not only high-performing but also inherently robust and secure against the unpredictable tides of internet traffic. This comprehensive exploration will delve deep into the mechanics, advantages, and implementation strategies of sliding window rate limiting, equipping you with the knowledge to fortify your digital infrastructure.
The Fundamental Need for Rate Limiting in Modern Architectures
In an era defined by interconnectedness and instantaneous access, the very success of a digital service can become its Achilles' heel if not properly managed. Every API call, every data request, every user interaction consumes precious server resources—CPU cycles, memory, database connections, and network bandwidth. Without a mechanism to control the pace of these demands, even a well-architected system can buckle under pressure. The reasons for implementing rate limiting are multifaceted and extend far beyond mere performance optimization.
Firstly, preventing abuse and malicious attacks is paramount. The internet, while a powerful tool, also harbors malicious actors intent on exploiting vulnerabilities. Brute-force attacks, where an attacker repeatedly tries different credentials to gain unauthorized access, can flood an authentication endpoint with thousands of requests per second. Similarly, content scrapers can bombard data-rich APIs to illicitly harvest information, impacting data integrity and potentially violating terms of service. DDoS attacks aim to overwhelm a service with an flood of illegitimate traffic, rendering it unavailable to legitimate users. Rate limiting acts as a crucial barrier against these threats, identifying and mitigating suspicious request patterns before they can cripple the system.
Secondly, rate limiting is essential for ensuring fairness and maintaining Quality of Service (QoS). Imagine a scenario where a single user or application makes an extraordinary number of requests, inadvertently or intentionally, consuming a disproportionate share of resources. This "noisy neighbor" problem can degrade performance for all other legitimate users, leading to slower response times, timeouts, and a generally poor user experience. By setting limits, services can ensure that resources are distributed equitably, providing a consistent and reliable experience for everyone, regardless of individual usage patterns. This fairness is particularly critical for public APIs or SaaS platforms where various customers share a common infrastructure.
Thirdly, from an operational and financial perspective, rate limiting plays a significant role in cost management. Cloud infrastructure providers often bill based on resource consumption—compute time, data transfer, and API calls. Uncontrolled traffic can lead to unexpectedly high operational costs. By capping the number of requests, organizations can better predict and manage their infrastructure expenses, preventing sudden spikes due to anomalous activity. This predictive capability is vital for budgeting and ensuring sustainable service delivery.
Finally, rate limiting helps in enforcing business logic and service tiers. Many businesses offer different levels of service, often tied to subscription plans. Premium users might have higher rate limits or access to more frequent data updates compared to free-tier users. Rate limiting provides the technical enforcement mechanism for these business rules, ensuring that users receive the service level they've paid for, while also incentivizing upgrades. It allows developers to define clear usage policies and build scalable business models around their API offerings. In complex microservices environments, where hundreds of services might communicate internally and externally, a centralized gateway or API gateway becomes the ideal point to enforce these cross-cutting concerns, abstracting the complexity from individual service implementations and providing a unified control plane. The importance of this cannot be overstated; without such a fundamental safeguard, any API-driven system is inherently vulnerable to both intentional malice and accidental self-inflicted wounds, ultimately compromising its robustness and reliability.
Understanding Core Rate Limiting Concepts
Before diving into the intricacies of sliding window rate limiting, it's crucial to establish a foundational understanding of the core concepts that underpin all rate limiting strategies. These concepts define what we measure, how we measure it, and what actions we take when limits are exceeded. A clear grasp of these fundamentals will provide context for appreciating the advantages and nuances of more advanced algorithms.
At its most basic, rate limiting is the process of controlling the rate at which a user, application, or system can access a specific resource or execute an operation. This control is typically defined by a set of rules that specify the maximum number of requests allowed within a defined time interval. The "rate" itself is usually expressed in terms of requests per second (RPS), requests per minute (RPM), or sometimes even requests per hour. The choice of interval depends heavily on the nature of the API and the desired granularity of control. For high-throughput transaction-based APIs, RPS might be appropriate, while for less frequent operations like report generation, RPM or longer intervals could be used.
Key metrics in rate limiting extend beyond just the average rate. Burst limits are another critical component. While a service might allow an average of 100 requests per minute, it might also tolerate a burst of 20 requests within a single second, provided the overall average remains within the limit over a longer period. Burst limits acknowledge that traffic is rarely perfectly smooth and can often come in unpredictable spikes. Allowing for these short, controlled bursts can significantly improve the user experience by preventing legitimate, but slightly uneven, traffic from being throttled unnecessarily. Without burst tolerance, a client making 10 requests every 6 seconds might be blocked even if their total over a minute is 100, purely because of the timing within a smaller, fixed window.
When a client exceeds its defined rate limit, the system must take a predetermined action. The most common actions include:
- Deny/Block: This is the most straightforward and often the default action. The request is immediately rejected, typically with an HTTP 429 Too Many Requests status code. This signals to the client that they have exceeded their quota and should back off.
- Delay/Queue: Instead of outright denying the request, the system can temporarily hold it in a queue and process it once the rate drops below the threshold. This can provide a smoother experience for legitimate clients but adds latency and requires careful management of queue sizes to prevent memory exhaustion.
- Throttle: Similar to delaying, throttling involves slowing down the processing of requests rather than completely blocking them. This might involve intentionally increasing latency for requests from an over-limit client or reducing the priority of their requests.
- Redirect: In some specialized cases, an exceeding request might be redirected to a different endpoint, perhaps one that serves cached data or a less resource-intensive version of the service. This can be useful for maintaining some level of service availability even under extreme load.
- Soft Block/Degrade: For internal services or less critical operations, the system might allow the request to pass but with reduced functionality or quality. For example, a search API might return fewer results or less precise matches if the client is exceeding its rate limit, rather than blocking the request entirely.
Effective rate limiting also requires robust identification mechanisms. To apply limits correctly, the system needs to determine "who" is making the request. Common identifiers include:
- IP Address: Simple to implement but problematic for clients behind NATs or proxies, where many users share a single IP. Also vulnerable to IP spoofing.
- User ID/API Key: More accurate and granular, allowing limits to be applied per individual user or application. Requires authentication, which adds overhead but is generally preferred for securing external APIs.
- Session ID/Cookie: Useful for browser-based applications to track user activity, even without explicit login.
- Request Headers: Custom headers can be used, though less common for primary identification.
- Endpoint/Path: Limits can be applied per specific API endpoint, recognizing that some operations are more resource-intensive than others. For instance, a
/loginendpoint might have a stricter limit than a/productslisting.
These core concepts form the scaffolding upon which all rate limiting algorithms are built. Each algorithm approaches the measurement of "rate" and the application of "limits" differently, with varying trade-offs in terms of accuracy, resource consumption, and complexity. The choice of algorithm profoundly impacts the effectiveness of the rate limiting strategy and, ultimately, the robustness of the entire system.
Traditional Rate Limiting Algorithms: A Foundation for Understanding
Before delving into the elegance of sliding window rate limiting, it's beneficial to understand the more traditional algorithms. These methods, while simpler, lay the groundwork for understanding the challenges that sliding window aims to solve. Each has its own set of advantages and limitations, making them suitable for specific scenarios but often falling short in others.
1. Fixed Window Counter
The Fixed Window Counter algorithm is perhaps the simplest and most intuitive rate limiting approach. Its mechanics are straightforward: a counter is maintained for a specific time window (e.g., 60 seconds). Each time a request arrives, the counter is incremented. If the counter exceeds a predefined limit within that window, subsequent requests are blocked until the window resets. When the window expires, the counter is reset to zero, and a new window begins.
How it Works: Imagine a limit of 100 requests per minute. * From 00:00 to 00:59, all requests increment a counter. If the counter reaches 101, further requests are denied. * At 01:00, the counter resets to 0, and a new window begins.
Pros: * Simplicity: Extremely easy to understand and implement. It requires minimal storage (just a counter and a timestamp for the window start) and low computational overhead. * Predictability: Clients can easily understand their limits and when they will reset, aiding in client-side retry logic.
Cons: The "Burstiness Problem" The most significant drawback of the fixed window counter is its susceptibility to the "burstiness problem" at the edges of the window. Consider a scenario where the limit is 100 requests per minute: * A client sends 90 requests at 00:59 (just before the window ends). These requests are allowed. * Immediately after, at 01:00, the window resets, and the client sends another 90 requests. These are also allowed. * In total, the client has sent 180 requests within a span of merely two seconds (00:59 and 01:00), effectively doubling the allowed rate for a very short period. This burst can still overwhelm the backend services, defeating the purpose of rate limiting. * Conversely, a client sending requests evenly throughout the minute might be unfairly blocked if another client's late-window burst exhausts the counter.
Despite its simplicity, the fixed window counter often proves inadequate for systems requiring robust protection against sudden traffic spikes, especially when deployed in an API gateway where traffic can be highly unpredictable.
2. Leaky Bucket Algorithm
The Leaky Bucket algorithm approaches rate limiting from a different perspective, focusing on smoothing out the rate of requests rather than strictly counting them within fixed intervals. It draws an analogy from a bucket with a hole at the bottom: liquid (requests) can be poured into the bucket at varying rates, but it leaks out at a constant, fixed rate. If the bucket overflows, any additional liquid (requests) is spilled (rejected).
How it Works: * Bucket Capacity: Defines the maximum number of requests that can be held in the queue. * Leak Rate: Defines the constant rate at which requests are processed or "leak out" of the bucket. * When a request arrives, if the bucket is not full, it's added. * If the bucket is full, the request is dropped (or delayed). * Requests are processed (leaked out) at a constant rate, irrespective of the incoming rate.
Pros: * Smooth Output Rate: The primary advantage is that it enforces a steady and predictable output rate of requests to the backend services. This helps in protecting downstream systems from sudden surges. * Handles Bursts (to a degree): It can absorb temporary bursts of requests as long as the bucket doesn't overflow. Requests arriving faster than the leak rate will fill the bucket, but they won't overwhelm the backend immediately.
Cons: * No Burst Allowance (for new requests): While it smooths the output, it doesn't allow for bursts to the client. If the bucket is full, even a single request is dropped, regardless of how many tokens a client might have accumulated in other systems. * Latency for Queued Requests: Requests added to the bucket might experience significant delays if the incoming rate is consistently higher than the leak rate. This can lead to a poor user experience. * Complexity: More complex to implement than the fixed window, especially in a distributed environment. It requires managing a queue and a processing thread or mechanism. * Fixed Capacity: The bucket's fixed capacity means it's limited in how much burst traffic it can absorb, and if the bucket fills quickly, legitimate requests can be dropped prematurely.
The leaky bucket is useful for scenarios where a constant processing rate is critical, such as protecting a database connection pool or a specific service that cannot handle variable load. However, for general API rate limiting, its strict output rate and potential for high latency might be undesirable.
3. Token Bucket Algorithm
The Token Bucket algorithm is another popular rate limiting strategy that offers a significant improvement over the leaky bucket in terms of allowing for bursts while maintaining an average rate limit. It's often likened to a bucket that contains "tokens." Each request consumes one token. If a request arrives and there are no tokens in the bucket, it is denied. Tokens are added to the bucket at a fixed rate, up to a maximum capacity.
How it Works: * Bucket Capacity (Burst Size): Defines the maximum number of tokens the bucket can hold. This represents the maximum burst size allowed. * Token Generation Rate: Defines how frequently new tokens are added to the bucket (e.g., 10 tokens per second). This corresponds to the average rate limit. * When a request arrives: * If there are tokens in the bucket, one token is removed, and the request is processed. * If there are no tokens, the request is denied (or delayed). * Tokens are continuously added to the bucket at the generation rate, up to the bucket's capacity. If the bucket is full, newly generated tokens are discarded.
Pros: * Allows for Bursts: This is its primary advantage. If a client has been idle for a while, tokens accumulate in the bucket, allowing them to send a burst of requests up to the bucket's capacity. This provides a better user experience for applications that might have intermittent high-frequency needs. * Smooth Average Rate: Over a longer period, the average rate of requests processed will not exceed the token generation rate, as that's the rate at which tokens are supplied. * Flexibility: Allows for easy configuration of both average rate and maximum burst size independently.
Cons: * Complexity: More complex to implement than the fixed window counter, requiring precise management of token generation and consumption, especially in a distributed environment where multiple instances might share the same bucket. * State Management: Requires maintaining state (current token count, last refill time) which needs to be synchronized across instances for a distributed gateway.
The token bucket algorithm is widely used in various network components, including routers and traffic shaper devices, and is a strong candidate for API rate limiting where burst tolerance is a key requirement. Its ability to balance sustained rate control with the flexibility to handle temporary spikes makes it quite versatile. However, like the fixed window, it doesn't perfectly address the "smoothness" across windows that a sliding window approach can offer, particularly when considering the fairness of the current rate over a moving timeframe.
Each of these traditional methods provides a piece of the puzzle, highlighting the trade-offs between simplicity, accuracy, resource usage, and burst tolerance. They serve as essential context for understanding why more sophisticated algorithms like the sliding window were developed to overcome their inherent limitations, particularly the unpredictable behavior at window boundaries or the rigidity of output rates.
Deep Dive into Sliding Window Rate Limiting
Having explored the traditional rate limiting algorithms, it becomes clear that while effective in their own right, they each present specific challenges. The fixed window counter suffers from the "edge problem," allowing for double the rate at window boundaries. The leaky bucket smooths output but offers limited client-side burst flexibility and can introduce latency. The token bucket allows bursts but still operates within a discrete token generation and consumption model. Enter Sliding Window Rate Limiting, an approach designed to offer a more accurate, fairer, and robust assessment of traffic over a continuous timeframe, thereby mitigating the weaknesses of its predecessors.
Why Sliding Window?
The fundamental motivation behind sliding window rate limiting is to provide a more realistic and consistent view of a client's request rate. Instead of resetting a counter abruptly at fixed intervals, a sliding window continuously "slides" over time, ensuring that the rate calculation always considers the requests made within the most recent N seconds/minutes. This eliminates the "edge effect" of fixed windows, where a burst of requests at the end of one window combined with a burst at the beginning of the next could circumvent the intended limit. It also offers a smoother, more accurate reflection of recent activity compared to algorithms that might over-penalize or under-penalize based on discrete timestamps.
There are primarily two main variants of the sliding window algorithm: the Sliding Log and the more practical Sliding Window Counter (Hybrid Approach).
1. Sliding Log Algorithm
The Sliding Log algorithm is the most accurate form of sliding window rate limiting, as it keeps a precise record of every single request within the current window.
How it Works: * For each client (identified by IP, user ID, etc.), the system stores a log of timestamps for every request made. * When a new request arrives, its timestamp is added to the log. * To determine if the request should be allowed, the system then filters this log, keeping only the timestamps that fall within the current "sliding window" (e.g., the last 60 seconds relative to the current time). * If the count of these valid timestamps (including the new request's timestamp) exceeds the predefined limit, the request is denied. Otherwise, it's allowed. * Periodically, or as part of the check, old timestamps that fall outside the current window are pruned from the log to prevent unbounded memory growth.
Example: * Limit: 5 requests per minute. * Current time: T. Window: [T - 60s, T]. * Log of timestamps for client X: [T-55s, T-40s, T-30s, T-10s] * New request arrives at T. Add T to log. * Filtered log (within [T-60s, T]): [T-55s, T-40s, T-30s, T-10s, T] * Count is 5. If limit is 5, allow. If limit is 4, deny.
Pros: * Highest Accuracy: It provides the most precise measure of requests within the sliding window because it literally counts every relevant request. There are no approximations or edge cases. * No Edge Effects: Completely eliminates the "burstiness problem" seen in fixed window counters, as the window is continuously moving and recalculating the rate based on the actual history.
Cons: * High Memory Usage: This is the most significant drawback. For a high-traffic API, storing timestamps for millions of requests across many clients can consume enormous amounts of memory, especially if the window size is large (e.g., 5 minutes or an hour). * High Computational Cost: For every request, the algorithm needs to iterate through potentially thousands of timestamps, filter them, and count them. This O(N) operation (where N is the number of requests in the window) can become a performance bottleneck under high throughput, making it impractical for large-scale systems. * Distributed Complexity: Storing and synchronizing these large, dynamic logs across multiple instances of an API gateway or backend service adds considerable complexity.
Due to these resource intensiveness, the Sliding Log algorithm is rarely used in its pure form for high-volume API rate limiting. It's often reserved for situations where extreme precision is paramount and traffic volumes are manageable, or for specialized audit trails rather than real-time enforcement.
2. Sliding Window Counter Algorithm (Hybrid Approach)
This is the most common and practical implementation of sliding window rate limiting. It strikes an excellent balance between accuracy and resource efficiency by combining elements of fixed window counting with a clever weighting mechanism. Instead of storing every timestamp, it leverages counts from two adjacent fixed windows.
How it Works: * Divide time into fixed-size windows (e.g., 60 seconds). * Maintain two counters for each client: * current_window_counter: For the current, active fixed window. * previous_window_counter: For the immediately preceding fixed window. * When a new request arrives at time T within the current_window: * Calculate the elapsed fraction of the current_window. Let elapsed_fraction = (T - current_window_start_time) / window_size. * The effective count for the sliding window is approximated using a weighted average: effective_count = (previous_window_counter * (1 - elapsed_fraction)) + current_window_counter * If effective_count exceeds the limit, the request is denied. * Otherwise, current_window_counter is incremented, and the request is allowed. * When a current_window expires, its current_window_counter becomes the new previous_window_counter, and a new current_window_counter starts at zero.
Example: * Limit: 100 requests per minute (window size = 60s). * Current time: 00:30 (30 seconds into the current minute window, elapsed_fraction = 0.5). * previous_window_counter (from 00:00-00:59 of the last minute): 80 requests. * current_window_counter (from 00:00-00:30 of the current minute): 30 requests. * effective_count = (80 * (1 - 0.5)) + 30 = (80 * 0.5) + 30 = 40 + 30 = 70. * Since 70 is less than 100, the request is allowed, and current_window_counter increments to 31.
Diagrammatic Representation:
Time Axis: |------Previous Window------|------Current Window------|
^-T_prev_start ^-T_current_start ^-T_current_end
Current Time: ^-T_now
Sliding Window: |------Sliding Window------|
<-------------------- Window Size ---------------------->
<--- Overlap_prev ----><---- Overlap_curr -------->
Overlap_prev = T_current_end - T_now
Overlap_curr = T_now - T_current_start
Effective Count = (previous_window_counter * (T_current_end - T_now) / Window_Size) + current_window_counter
A simpler way to visualize this for the current check is to consider the fraction of the previous window that still overlaps with the current sliding window. If the current time T_now is X seconds into the current fixed window (which is W seconds long), then the current sliding window effectively covers X seconds of the current fixed window and W-X seconds of the previous fixed window.
So, the formula is more commonly expressed as: effective_count = (previous_window_counter * (window_size - elapsed_time_in_current_window) / window_size) + current_window_counter
This formula effectively "ages out" the previous window's count proportionally to how much of the current window has passed, and then adds the count from the current window.
Pros: * Good Balance of Accuracy and Efficiency: It significantly reduces the "edge effect" of the fixed window counter without the high memory and computational overhead of the sliding log. It's a much smoother approximation. * Resource Efficient: Requires only two counters per client (plus window start times), making its memory footprint very low compared to the sliding log. * Moderate Computational Cost: The calculation is a simple arithmetic operation, making it fast and suitable for high-throughput environments. * Predictable Behavior: Offers more consistent rate enforcement across window boundaries, providing a fairer experience for clients.
Cons: * Still an Approximation: It's not as perfectly precise as the sliding log because it assumes a uniform distribution of requests within the previous window for its weighting. While significantly better than fixed window, it's not absolutely perfect. However, for most practical applications, this approximation is more than sufficient. * Slightly More Complex than Fixed Window: Requires managing two counters and the window logic.
The Sliding Window Counter algorithm is widely regarded as the most practical and effective solution for API rate limiting in production systems, including those implemented within sophisticated API gateways. It offers a robust defense against various traffic patterns while remaining operationally feasible at scale.
Implementation Details
Implementing sliding window rate limiting, especially the hybrid counter approach, requires careful consideration of data structures, concurrency, and distributed system challenges:
- Data Storage: A common choice for storing the counters and window information is Redis. Its
INCRcommand for atomic increments andEXPIREfor managing window lifetimes (orEXPIREATto align with window boundaries) are ideal. Redis sorted sets can also be used to store timestamps for the sliding log, but as mentioned, this is generally less scalable. For the sliding window counter, keys could be structured likerate_limit:{client_id}:{api_path}:{timestamp_of_window_start}to store the counters. - Concurrency and Atomicity: In a multi-threaded or distributed environment, multiple requests for the same client might arrive concurrently. The operations to read, calculate, and increment the counters must be atomic. Redis transactions (using
MULTI/EXEC) or Lua scripts can ensure this. A Lua script executed on Redis can fetch both previous and current window counters, perform the calculation, and increment the current counter within a single atomic operation, preventing race conditions. - Key Generation: The unique key used to identify the client and the specific limit (e.g.,
user:123:api/v1/data) is crucial. This key determines the granularity of the rate limit. - Window Management: Timers or scheduled tasks are needed to roll over the windows (i.e., move
current_window_countertoprevious_window_counterand resetcurrent_window_counter). This can be done lazily on demand or proactively. - Distributed Systems: For an API gateway cluster, all instances must refer to a shared, consistent state (like a central Redis instance) for rate limit counters. This prevents individual gateway instances from having an inconsistent view of the client's rate and potentially allowing more requests than permitted.
By carefully designing these implementation aspects, the sliding window counter can be deployed effectively, providing robust and fair rate limiting across complex, high-traffic systems.
APIPark is a high-performance AI gateway that allows you to securely access the most comprehensive LLM APIs globally on the APIPark platform, including OpenAI, Anthropic, Mistral, Llama2, Google Gemini, and more.Try APIPark now! 👇👇👇
Implementing Sliding Window Rate Limiting in Practice
The theoretical understanding of sliding window rate limiting transforms into a powerful practical defense when deployed strategically within a system architecture. The choice of where to implement this logic significantly impacts its effectiveness, scalability, and ease of management.
Where to Implement Rate Limiting
Rate limiting can be implemented at various layers of a system, each with its own trade-offs:
- Application Layer: Implementing rate limiting directly within the application code (e.g., in a specific microservice) offers the most granular control. You can tailor limits based on complex internal business logic, user roles, or specific resource consumption patterns. However, this approach can lead to duplicated logic across multiple services, makes centralized policy management difficult, and shifts the burden of protection onto individual services, which might already be under stress. It's generally less preferred for external-facing APIs due to these complexities.
- Service Mesh: In a microservices architecture, a service mesh (e.g., Istio, Linkerd) can intercept all inter-service communication. This provides a centralized point for applying policies like rate limiting without modifying application code. It's excellent for internal API communication, ensuring fair usage and protecting individual services within the mesh. However, it typically doesn't handle external client traffic directly; an API gateway usually sits in front of the service mesh.
- Load Balancers/Reverse Proxies: Tools like Nginx, Envoy, or cloud load balancers (AWS ALB, GCP Load Balancer) can perform basic rate limiting. They operate at a lower level (HTTP, TCP/UDP) and are efficient at blocking requests based on IP addresses or simple headers before they reach the backend. While effective for simple fixed-window or connection-based limits, they often lack the sophistication for dynamic, user-specific, or complex sliding window logic that requires stateful tracking across a distributed environment.
- API Gateways: This is arguably the most common and effective place to implement rate limiting for external API traffic. An API gateway acts as a single entry point for all client requests, sitting between the clients and the backend services.
The Indispensable Role of an API Gateway
An API gateway is far more than just a reverse proxy; it's a critical component in modern microservices and API architectures, serving as an API management platform that handles a multitude of cross-cutting concerns. When it comes to rate limiting, its role is indispensable for several reasons:
- Centralized Enforcement Point: All requests, whether from internal or external clients, pass through the API gateway. This provides a single, consistent point to enforce rate limiting policies across all APIs. This eliminates redundant implementation efforts in individual microservices and ensures uniform application of rules.
- Unified Policy Management: An API gateway allows administrators to define, configure, and manage rate limiting policies from a centralized interface. This means policies can be easily updated, applied to different API endpoints, client groups, or subscription tiers without deploying changes to backend services.
- Abstraction from Backend Services: The API gateway shields backend services from the complexities of rate limiting. Backend services can focus purely on business logic, knowing that they are protected by the gateway upstream. This simplifies service development and makes services more resilient.
- Enhanced Security: By blocking excessive or malicious requests at the edge, the API gateway prevents these requests from even reaching the backend infrastructure. This conserves backend resources and reduces the attack surface for DDoS, brute-force, and other abuse vectors.
- Monitoring and Analytics: Gateways often integrate with monitoring and logging systems, providing invaluable insights into traffic patterns, rate limit breaches, and potential abuse. This data is crucial for refining rate limiting policies and identifying emerging threats.
- Traffic Management: Beyond rate limiting, an API gateway can handle other traffic management functions such as routing, load balancing, caching, authentication, authorization, and circuit breaking. Integrating rate limiting into this suite of capabilities creates a powerful, cohesive traffic management solution.
Consider a sophisticated API gateway and API management platform like APIPark. APIPark is an open-source AI gateway and API developer portal designed for managing, integrating, and deploying AI and REST services with ease. Its capabilities make it an ideal platform for implementing advanced rate limiting strategies, including sliding window. With APIPark, you can define specific rate limits for different APIs, users, or applications, leveraging its end-to-end API lifecycle management features. For instance, APIPark's ability to provide independent API and access permissions for each tenant means you can tailor sliding window limits to specific organizational units or customer tiers.
APIPark offers performance rivaling Nginx, capable of achieving over 20,000 TPS with modest hardware and supporting cluster deployment for large-scale traffic. This robust performance is critical for a component that sits in the hot path of all API requests, ensuring that the rate limiting mechanism itself doesn't become a bottleneck. Furthermore, APIPark's detailed API call logging and powerful data analysis features are invaluable for monitoring the effectiveness of your sliding window rate limits. You can track exactly which clients are hitting their limits, identify patterns of abuse, and adjust your policies based on real-world usage data. This integration of a high-performance gateway with comprehensive management and analytics tools provides a holistic solution for not just implementing, but also optimizing and maintaining robust rate limiting policies. The ability to integrate with over 100+ AI models and encapsulate prompts into REST API further highlights its role in managing diverse API traffic, where varying API types might require different rate limiting considerations.
Technical Considerations for Implementation
When implementing sliding window rate limiting, especially the hybrid counter approach within an API gateway, several technical considerations are paramount:
- Concurrency and Atomicity: As discussed, ensuring that counter updates and reads are atomic is vital in a concurrent environment. Using Redis with Lua scripts is a common and effective pattern. A Lua script can fetch both
previous_window_counterandcurrent_window_counter, calculate theeffective_count, check against the limit, and if allowed, atomically incrementcurrent_window_counter, all within a single server-side operation. This prevents race conditions where multiple requests might simultaneously read outdated counter values. - Data Persistence: While rate limits are often ephemeral (in-memory or short-lived Redis keys), persistence strategies might be needed for audit trails or long-term analytics. However, for real-time enforcement, fast in-memory stores are preferred.
- Graceful Degradation vs. Hard Limits: Decide whether to strictly deny requests (hard limit) or to introduce throttling/delays (graceful degradation) when limits are exceeded. For critical APIs, a hard 429 response is often appropriate. For less critical internal APIs, queueing or delayed processing might improve perceived availability.
- Client-Side Communication: When a request is denied due to rate limiting, the API gateway should return appropriate HTTP headers. The
429 Too Many Requestsstatus code is standard. Additionally,Retry-Afterheader informs the client when they can safely retry their request (e.g.,Retry-After: 60for 60 seconds).X-RateLimit-Limit,X-RateLimit-Remaining, andX-RateLimit-Resetheaders provide transparency to the client about their current rate limit status, enabling them to implement intelligent retry backoff strategies. - Distributed Consistency: In a distributed API gateway cluster, all instances must share a consistent view of the rate limit state. This necessitates a centralized, high-performance data store (like Redis) that all gateway nodes can access. Replication and high availability for this data store are crucial to prevent single points of failure.
- Error Handling and Monitoring: Robust error handling for communication with the rate limiting data store is essential. Comprehensive monitoring of rate limit counters, denial rates, and system performance is needed to identify misconfigurations, attacks, or legitimate usage patterns that warrant policy adjustments.
By carefully planning and implementing these technical considerations, you can build a highly effective and resilient sliding window rate limiting system that leverages the power of an API gateway to safeguard your digital assets.
Advanced Strategies and Best Practices
While the implementation of sliding window rate limiting provides a robust foundation, building truly resilient and user-friendly systems requires moving beyond basic enforcement to embrace more advanced strategies and best practices. These approaches allow for finer-grained control, dynamic adaptation, and better communication with clients, ultimately enhancing both security and user experience.
Granularity of Rate Limiting
Effective rate limiting starts with defining the right level of granularity: * Per User/API Key: This is often the most desired granularity, as it ties the limit directly to the authenticated user or application. It prevents a single malicious actor from consuming all resources, even if they use multiple IP addresses. This requires prior authentication to identify the user. * Per IP Address: Simple to implement, especially at the gateway or load balancer level, as it doesn't require authentication. However, it can be problematic for users behind shared NATs or proxies, where many legitimate users might share one IP and unfairly hit a collective limit. Conversely, sophisticated attackers can rotate IPs to bypass these limits. * Per Endpoint/Path: Different API endpoints have different resource consumption profiles. A /search endpoint might be more resource-intensive than a /status endpoint. Applying different limits per endpoint ensures that critical, heavy-duty operations are protected more aggressively, while lighter operations remain accessible. * Per Tenant/Organization: For SaaS platforms or multi-tenant architectures, limits might need to be applied per organizational unit, allowing each tenant to manage their own quota, often with sub-limits for their individual users. * Combined Granularity: The most robust strategies often combine these. For example, a global limit per IP address for unauthenticated requests, and then a more generous, specific limit per authenticated user/API key for specific endpoints. An API gateway like APIPark is perfectly suited to manage this kind of multi-layered granularity, as its core design supports independent API and access permissions for different tenants and users.
Tiered and Dynamic Rate Limiting
Static, one-size-fits-all limits are rarely optimal. More advanced systems implement:
- Tiered Rate Limiting: This involves setting different limits based on user subscription plans (e.g., Free, Basic, Premium). Premium users might have significantly higher rate limits, or even a guaranteed minimum throughput, while free users operate under stricter constraints. This aligns technical enforcement with business models.
- Dynamic Rate Limiting: Limits can be adjusted in real-time based on various factors:
- System Load: If backend services are experiencing high CPU or memory utilization, the API gateway can temporarily reduce overall rate limits to prevent cascading failures.
- User Behavior: Clients exhibiting suspicious patterns (e.g., unusually high error rates, rapid-fire requests to sensitive endpoints) might have their limits temporarily tightened or their requests routed to challenge pages (CAPTCHA).
- Payment Tiers: As mentioned, adjusting limits based on a user's paid tier, possibly even allowing for "burst credits" that can be purchased.
- Time of Day: Certain APIs might experience peak usage during specific hours. Dynamic limits could adjust to these predictable patterns, offering higher throughput during off-peak hours.
Hard vs. Soft Limits
- Hard Limits: Requests exceeding the limit are immediately rejected (e.g., 429 Too Many Requests). This is crucial for protecting against malicious attacks and ensuring system stability under extreme load.
- Soft Limits (Throttling/Queuing): Instead of immediate rejection, requests might be delayed or queued. This can improve user experience by providing eventual processing rather than outright denial. However, it adds complexity (queue management, timeout handling) and might still lead to unacceptable latency if the incoming rate is consistently high. The choice depends on the API's criticality and the acceptable latency.
Exemptions and Whitelisting
Not all traffic should be subject to the same rate limits. * Internal Services: Internal microservice communication often operates under higher trust and might be exempt from strict external rate limits to avoid inter-service communication bottlenecks. * Known Partners/Premium Users: Specific partners or high-value customers might be whitelisted for higher, customized limits, or even completely exempt from certain global limits. This requires robust authentication and authorization mechanisms, typically managed by the API gateway. * Monitoring/Health Checks: Automated health checks and monitoring agents should generally be exempt from rate limiting to ensure continuous visibility into system health.
Monitoring and Alerting
Rate limiting is not a "set it and forget it" solution. Continuous monitoring is essential: * Track Denials: Monitor the number of 429 responses. Spikes in denials might indicate an attack, a misconfigured client, or a legitimate surge in demand that warrants a policy review. * Resource Utilization: Correlate rate limit denials with backend service resource utilization. This helps validate if limits are effective in protecting services or if they need adjustment. * Latency: Monitor the latency introduced by the rate limiting mechanism itself, ensuring it doesn't become a bottleneck. * Alerting: Set up alerts for sustained high denial rates, sudden drops in legitimate traffic (if related to rate limiting), or failures in the rate limiting system itself. * APIPark's powerful data analysis features and detailed API call logging directly support this, providing insights into historical call data, long-term trends, and performance changes, which are invaluable for proactive maintenance and policy adjustments.
Client Communication: HTTP Headers
Clear communication with clients about their rate limit status is a best practice. Use standard HTTP headers: * Retry-After: Indicates how long the client should wait before retrying. * X-RateLimit-Limit: The total number of requests allowed in the current window. * X-RateLimit-Remaining: The number of requests remaining in the current window. * X-RateLimit-Reset: The timestamp when the current rate limit window will reset (e.g., in UTC seconds since epoch). These headers empower clients to implement intelligent backoff and retry mechanisms, reducing unnecessary requests and improving their integration with your API.
Testing Rate Limit Implementations
Thorough testing is crucial to ensure rate limits behave as expected: * Unit Tests: Test the core rate limiting logic (e.g., the sliding window counter calculation) in isolation. * Integration Tests: Test how the rate limiter interacts with the API gateway and backend services. * Load Testing: Simulate high traffic loads to verify that limits are enforced correctly, that backend services are protected, and that the rate limiter itself doesn't introduce performance bottlenecks. Test scenarios that specifically target the "edge effects" of fixed windows or burst behaviors that sliding windows are designed to handle. * Edge Case Testing: What happens if a client sends a massive burst? What if they are just under the limit? What happens during window rollovers?
By incorporating these advanced strategies and best practices, systems can move beyond basic protection to offer a highly intelligent, adaptive, and client-friendly rate limiting solution. This not only enhances system resilience but also fosters better relationships with developers and partners who consume your API.
Choosing the Right Rate Limiting Strategy: A Comparative Analysis
The decision of which rate limiting algorithm to implement is not a one-size-fits-all choice. It depends heavily on the specific requirements of the API, the expected traffic patterns, the tolerance for burstiness, the available resources, and the complexity of implementation. While sliding window, particularly the hybrid counter, is often the preferred choice for its balance, understanding the trade-offs with other algorithms is crucial for making an informed decision.
Here's a comparative table summarizing the key characteristics of the discussed rate limiting algorithms:
| Algorithm | Accuracy | Memory Usage | CPU Usage | Burst Tolerance | Implementation Complexity | Ideal Use Case |
|---|---|---|---|---|---|---|
| Fixed Window Counter | Low (edge effect) | Low (single counter) | Low | Low (concentrated) | Low | Simple APIs, low-volume services, internal rate limits where bursts are less critical or handled elsewhere. |
| Leaky Bucket | Moderate (smoothes rate) | Moderate (queue size) | Moderate | Good (absorbs bursts by queuing, but doesn't allow client-side burst control) | Moderate | Steady traffic, preventing surges to a sensitive backend, protecting a fixed-capacity resource (e.g., database connections). |
| Token Bucket | Moderate (allows bursts) | Moderate (token count) | Moderate | High (token accumulation allows client bursts) | Moderate | Burstable traffic, allowing occasional spikes, where clients expect to "save up" capacity. Common in networking devices. |
| Sliding Log | High (most precise) | Very High (all timestamps) | Very High (iterating log) | High (no edge effects) | High | Highly critical, low-volume APIs needing precise control, where auditing every request is important, or for specific forensic analysis. |
| Sliding Window Counter | High (good approximation) | Low-Moderate (2 counters) | Low-Moderate (weighted average) | High (spreads bursts over the window, no edge effect) | Moderate | Most general-purpose, high-throughput APIs, where a balance of accuracy, efficiency, and fairness is crucial. Recommended for most API gateway deployments. |
Key Decision Factors:
- Traffic Patterns:
- If traffic is generally smooth and predictable, a Fixed Window Counter might suffice for very simple APIs.
- If clients often send requests in bursts, but the system needs to process them at a smooth, constant rate, Leaky Bucket might be considered.
- If clients need to be able to send occasional bursts (e.g., after a period of inactivity), Token Bucket or Sliding Window Counter are better choices.
- If the goal is to prevent any form of short-term overage and ensure fair access over a continuous period, Sliding Window Counter excels.
- Resource Constraints (Memory & CPU):
- For very high-volume APIs where memory and CPU are critical, the Fixed Window Counter and Sliding Window Counter are generally superior to Sliding Log. The Sliding Window Counter offers much better accuracy for a modest increase in resource usage over Fixed Window.
- Leaky and Token Bucket require more complex state management than fixed window but are still manageable.
- Accuracy and Fairness:
- If strict adherence to a rate limit without any "edge effect" is paramount, Sliding Log is the most accurate but often impractical.
- The Sliding Window Counter provides an excellent approximation, significantly reducing the edge effect and offering a much fairer assessment of recent traffic compared to the Fixed Window Counter.
- Implementation Complexity:
- Fixed Window is the easiest.
- Leaky Bucket, Token Bucket, and Sliding Window Counter are moderately complex, especially when considering distributed environments and atomic operations (e.g., using Redis with Lua scripts).
- Sliding Log is the most complex to implement efficiently at scale due to its data structure and computational demands.
Why Sliding Window Counter Often Wins for API Gateways:
For most modern API gateway deployments, the Sliding Window Counter algorithm (the hybrid approach) offers the best blend of attributes: * Mitigates Edge Effects: It largely resolves the burstiness problem of fixed windows, providing a smoother and fairer enforcement. * Resource Efficient: Compared to the Sliding Log, it's highly efficient in terms of memory and CPU, making it suitable for high-throughput APIs. * Good Accuracy: While an approximation, its accuracy is more than sufficient for the vast majority of API rate limiting scenarios. * Robustness: It provides reliable protection against various traffic patterns, ensuring that an API remains stable and responsive.
This makes it the go-to choice for platforms like APIPark, which are designed to manage high volumes of diverse API traffic with optimal performance and robust security. A well-chosen rate limiting strategy, deeply integrated within an API management platform, is a cornerstone of building scalable and resilient distributed systems.
Potential Pitfalls and How to Avoid Them
Implementing rate limiting, especially sophisticated techniques like sliding windows, is not without its challenges. Overlooking certain aspects can lead to issues ranging from false positives that block legitimate users to security bypasses that render the entire mechanism ineffective. Awareness of these potential pitfalls and proactive measures to avoid them are crucial for a successful deployment.
1. False Positives: Blocking Legitimate Traffic
One of the most frustrating outcomes of poorly configured rate limits is inadvertently blocking legitimate users or applications. * Problem: An overly strict global IP-based limit might block an entire office building sharing a single public IP address, or users behind a large-scale NAT. Similarly, a poorly tuned sliding window might over-penalize a client for a legitimate, short burst of activity that doesn't actually harm the system. * Avoidance: * Granularity: Use finer-grained limits (per user/API key) rather than relying solely on IP addresses, especially for authenticated APIs. * Tiered Limits & Whitelisting: Implement tiered rate limits for different user segments and whitelist trusted partners or internal services. * Start Lenient, Iterate: Begin with more generous limits and gradually tighten them based on observed traffic, performance, and abuse patterns. * Monitor 429 Responses: Keep a close eye on 429 Too Many Requests responses. A sudden spike might indicate an attack, but a consistent, high volume across disparate IPs could also signal overly strict limits.
2. Too Lenient or Too Strict Limits
Finding the "Goldilocks zone" for rate limits—neither too lenient nor too strict—is a continuous balancing act. * Problem (Too Lenient): Ineffective protection against abuse, system overload, resource exhaustion. * Problem (Too Strict): Poor user experience, blocking legitimate use cases, frustration for developers integrating with your API. * Avoidance: * Understand Your System: Profile your backend services to understand their actual capacity (TPS, concurrent connections, CPU/memory limits) under various loads. * Analyze Traffic: Use API gateway logging and analytics (like those provided by APIPark) to understand typical and peak legitimate traffic patterns. Identify average and burst rates for different APIs. * Business Needs: Align limits with business objectives (e.g., premium tiers, monetization strategies). * Iterative Refinement: Treat rate limits as a dynamic configuration. Continuously monitor their impact on performance, security, and user experience, and be prepared to adjust them.
3. Distributed System Challenges
Implementing rate limiting in a distributed environment (multiple API gateway instances, microservices) introduces complexities. * Problem: Inconsistent state across instances can lead to clients being allowed to exceed their limit. If each gateway instance maintains its own local counters, a client could hit the limit on one instance and then simply send requests to another, effectively bypassing the limit. * Avoidance: * Centralized State: Use a shared, high-performance, and highly available data store (like Redis) for all rate limit counters. All API gateway instances must read from and write to this central store. * Atomic Operations: Ensure all read-modify-write operations on counters are atomic, especially for sliding window algorithms where multiple counters are involved. Redis Lua scripts are excellent for this. * Eventual Consistency (if applicable): For less critical, high-volume scenarios, some eventual consistency might be acceptable, but for strict rate limiting, strong consistency is generally preferred. * Robust Data Store: The chosen centralized store (e.g., Redis cluster) must be as robust and scalable as the API gateway itself, as it becomes a single point of failure if not properly managed.
4. Security Bypass and Incorrect Configuration
Rate limiting is a security control; improper configuration can expose vulnerabilities. * Problem: * IP Spoofing: If relying solely on IP addresses, attackers can spoof source IPs (though this is harder at the gateway level where TCP connections are established). * Header Manipulation: Attackers might try to manipulate headers (e.g., X-Forwarded-For) to bypass IP-based limits if the gateway isn't correctly configured to trust only specific upstream proxies. * Identifier Rotation: If limits are per-user, but the authentication mechanism is weak or easily bypassed, attackers can simply generate new user IDs or API keys. * Endpoint Specificity: Not applying limits to all relevant endpoints (e.g., forgetting a less obvious internal API that exposes sensitive data). * Avoidance: * Trust Nothing: Validate all incoming request headers. Trust only the outermost API gateway or trusted load balancer to set X-Forwarded-For. * Strong Authentication: Ensure that user-based rate limits rely on robust authentication mechanisms. * Comprehensive Coverage: Apply rate limits across all exposed API endpoints, considering their resource intensity and sensitivity. * Security Audits: Regularly audit your rate limiting configurations as part of a broader security review.
5. Lack of Visibility and Monitoring
Implementing rate limiting without adequate monitoring is akin to flying blind. * Problem: Without visibility into rate limit hits, denials, and their impact, it's impossible to know if the system is effective, if it's causing false positives, or if it's under attack. * Avoidance: * Logging: Log all rate limit events (allowances, denials, client identifiers, API paths). APIPark's detailed API call logging is specifically designed for this. * Metrics: Instrument the rate limiter to emit metrics (total requests, allowed requests, denied requests, per-client metrics). * Dashboards: Create dashboards to visualize these metrics, showing trends and real-time status. * Alerting: Set up alerts for critical events (e.g., a sudden surge in 429s, unusual patterns from a specific client). * Data Analysis: Utilize historical data to analyze trends, predict future needs, and refine policies, as supported by APIPark's powerful data analysis capabilities.
By proactively addressing these potential pitfalls, organizations can deploy robust and intelligent sliding window rate limiting solutions that truly enhance the resilience and security of their APIs and underlying systems, rather than introducing new points of failure or friction.
Conclusion
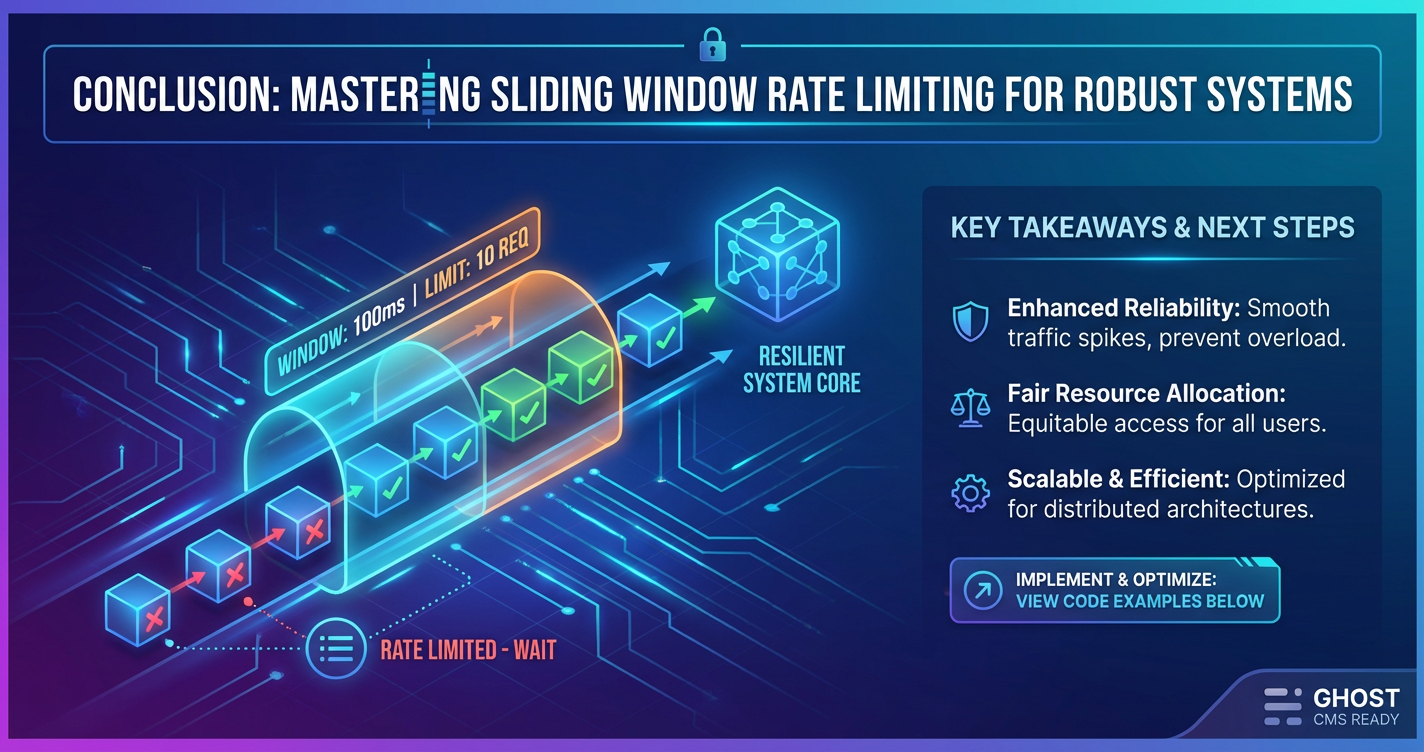
In the relentless ebb and flow of digital traffic, the stability and resilience of modern systems hinge upon sophisticated defense mechanisms. Among these, rate limiting stands as a fundamental guardian, ensuring fair access, thwarting malicious attacks, and preserving precious computing resources. While simpler algorithms like fixed window counters offer basic protection, they often fall short in handling the nuanced, bursty nature of real-world traffic. This is where Sliding Window Rate Limiting emerges as a superior strategy, offering a more accurate, fairer, and robust approach to managing API requests.
By continuously evaluating traffic over a moving timeframe, sliding window algorithms effectively eliminate the critical "edge effect" that plagues fixed window methods, preventing periods of double-rate allowance that can overwhelm backend services. The hybrid Sliding Window Counter algorithm, in particular, strikes an optimal balance between precision and efficiency, making it the preferred choice for high-throughput, mission-critical APIs. It provides a consistent and predictable mechanism to control access without demanding the excessive computational and memory resources of its more precise, but less scalable, "sliding log" counterpart.
The strategic implementation of such advanced rate limiting techniques is best executed at the API gateway layer. An API gateway serves as the central nervous system for all inbound API traffic, providing a unified enforcement point for security policies, traffic management, and API management lifecycle controls. Platforms like APIPark exemplify this, offering a high-performance, open-source AI gateway and API management platform that not only facilitates the integration and deployment of diverse APIs but also inherently provides the necessary infrastructure for robust rate limiting. With its capabilities for end-to-end API lifecycle management, performance rivaling industry giants, detailed logging, and powerful data analytics, APIPark provides an ideal environment to configure, monitor, and optimize sliding window rate limits, ensuring system stability and security.
Mastering sliding window rate limiting is not just about choosing an algorithm; it's about adopting a holistic approach that encompasses careful planning, granular policy definition, continuous monitoring, and client-friendly communication. By understanding the nuances of different algorithms, the indispensable role of an API gateway, and the potential pitfalls to avoid, developers and architects can build systems that are not only capable of handling immense scale but are also inherently resilient against the unpredictable challenges of the digital frontier. In an increasingly API-driven world, the ability to control and manage access effectively is paramount, and sliding window rate limiting stands as a testament to intelligent design in the pursuit of robust and secure digital infrastructure.
Frequently Asked Questions (FAQs)
1. What is the primary difference between fixed window and sliding window rate limiting? The primary difference lies in how they handle time intervals. A fixed window (e.g., 60 seconds) resets its counter abruptly at the end of each fixed interval. This can lead to the "burstiness problem" where a client can send a high number of requests at the very end of one window and then immediately at the beginning of the next, effectively doubling the rate in a short period. A sliding window, on the other hand, continuously re-evaluates the request rate over a rolling time window (e.g., the last 60 seconds from the current moment). This eliminates the edge effect, providing a much smoother and fairer assessment of the client's request rate and preventing bursts across window boundaries.
2. Why is rate limiting crucial for an API gateway? Rate limiting is crucial for an API gateway because the gateway serves as the single entry point for all client requests to your backend services. Implementing rate limiting at this central point provides a consolidated defense mechanism, protecting all downstream services from excessive traffic, malicious attacks (like DDoS or brute-force), and resource exhaustion. It enables centralized policy management, ensures fair usage across different clients or APIs, and offloads this critical security and traffic management concern from individual microservices, simplifying their development and increasing overall system robustness. Platforms like APIPark leverage this gateway position to apply robust rate limiting.
3. What are the performance implications of sliding log vs. sliding window counter? The sliding log algorithm offers the highest accuracy as it stores every request's timestamp. However, this leads to very high memory usage (storing potentially millions of timestamps) and high computational cost (O(N) operation to filter and count timestamps for each request), making it generally impractical for high-throughput APIs. The sliding window counter (hybrid approach) is a much more performant alternative. It uses only two counters per client (for the current and previous fixed windows) and a simple weighted average calculation, resulting in significantly lower memory usage and computational cost (O(1) operation). While an approximation, its accuracy is more than sufficient for most production environments, offering a better balance for high-performance API gateway deployments.
4. How do you communicate rate limit status to clients? When a client exceeds its rate limit, the API gateway should return an HTTP 429 Too Many Requests status code. Additionally, it's best practice to include specific HTTP headers to inform the client about their current rate limit status and how to proceed: * Retry-After: Indicates the number of seconds (or a date/time) the client should wait before making another request. * X-RateLimit-Limit: The total number of requests allowed in the current time window. * X-RateLimit-Remaining: The number of requests the client has left in the current window. * X-RateLimit-Reset: The timestamp (often in UTC seconds since epoch) when the current rate limit window will reset. These headers empower clients to implement intelligent backoff and retry mechanisms, improving their integration experience.
5. Can rate limiting prevent all types of DDoS attacks? While rate limiting is a crucial component of a DDoS mitigation strategy, it cannot prevent all types of DDoS attacks on its own. It is highly effective against application-layer DDoS attacks (e.g., HTTP floods, API misuse) where specific API endpoints are targeted with a high volume of legitimate-looking requests. However, it's less effective against lower-layer network attacks (e.g., SYN floods, UDP floods) that aim to exhaust network bandwidth or server connection tables before requests even reach the API gateway or the rate limiting logic. A comprehensive DDoS defense requires a multi-layered approach involving network-level protection (e.g., scrubbing centers, firewalls), advanced bot detection, and traffic anomaly detection systems in addition to intelligent application-layer rate limiting.
🚀You can securely and efficiently call the OpenAI API on APIPark in just two steps:
Step 1: Deploy the APIPark AI gateway in 5 minutes.
APIPark is developed based on Golang, offering strong product performance and low development and maintenance costs. You can deploy APIPark with a single command line.
curl -sSO https://download.apipark.com/install/quick-start.sh; bash quick-start.sh

In my experience, you can see the successful deployment interface within 5 to 10 minutes. Then, you can log in to APIPark using your account.

Step 2: Call the OpenAI API.