Secure Your Data: GraphQL to Query Without Sharing Access


In the intricate tapestry of modern digital infrastructure, data stands as the unequivocal lifeblood of innovation, efficiency, and competitive advantage. Yet, this invaluable resource also represents one of the most formidable vulnerabilities for organizations worldwide. The incessant drumbeat of data breaches, regulatory mandates like GDPR and CCPA, and the ever-present threat of insider access make data security not merely a technical concern but a paramount strategic imperative. Enterprises today grapple with the paradox of needing to democratize data access for rapid development and insightful analytics, while simultaneously erecting impenetrable fortresses around sensitive information. This challenge intensifies with the proliferation of microservices architectures and distributed systems, where countless points of access could potentially become points of failure. The traditional paradigms of data access, often rooted in RESTful APIs, frequently fall short of providing the granular control necessary to navigate this complex landscape, leading to scenarios of over-fetching data, unnecessary exposure, and ultimately, elevated security risks.
The limitations of conventional API designs often compel developers to either expose too much data by default or create an unwieldy multitude of bespoke endpoints, each tailored to specific data requirements. Neither approach is sustainable or secure in the long run. Over-fetching, where a client receives more data than it actually needs, not only wastes bandwidth and processing power but also inherently increases the attack surface, as sensitive fields might be inadvertently transmitted to unauthorized clients. Conversely, the proliferation of endpoints to address under-fetching leads to API sprawl, maintenance headaches, and inconsistencies, making robust API Governance an arduous task. This inherent friction between data utility and data security has long presented a seemingly intractable dilemma for architects and developers.
However, a transformative solution has emerged from the evolving API landscape: GraphQL. By empowering clients to precisely declare their data requirements, GraphQL offers a fundamentally different approach to data retrieval. It shifts the power dynamic, allowing developers to query without sharing broad, indiscriminate access to underlying data structures. When synergistically combined with the robust capabilities of an API Gateway and a meticulously crafted API Governance framework, GraphQL transcends its role as a mere query language, becoming a cornerstone of a proactive, security-first data access strategy. This article will delve deeply into how GraphQL, fortified by an intelligent API Gateway and stringent API Governance principles, can revolutionize data access security, enabling highly precise querying while diligently safeguarding sensitive information against unauthorized exposure and misuse. We will explore the technical underpinnings, practical implementations, and strategic implications of this powerful trifecta, offering a comprehensive guide to building data access layers that are both flexible and inherently secure.
The Evolving Landscape of Data Access and Security: A Modern Imperative
The pervasive digital transformation sweeping across industries has irrevocably cemented data’s status as the most valuable asset in the modern enterprise. From powering AI algorithms to driving strategic business decisions, data fuels innovation and competitive differentiation. This omnipresence, however, comes with a formidable set of responsibilities and inherent risks. The sheer volume, velocity, and variety of data being generated, processed, and stored by organizations daily present an unprecedented challenge in terms of security and access control. Businesses are under constant pressure to extract maximum value from their data while simultaneously navigating a complex web of regulatory compliance, mounting cyber threats, and the ever-present risk of data breaches.
The implications of inadequate data security are staggering. A single data breach can result in catastrophic financial losses, irreparable reputational damage, severe legal penalties, and a profound erosion of customer trust. Regulations such as the General Data Protection Regulation (GDPR) in Europe, the California Consumer Privacy Act (CCPA) in the United States, and numerous other regional data protection laws impose stringent requirements on how personal data is collected, stored, processed, and accessed. Non-compliance can lead to exorbitant fines, underscoring the critical need for robust data governance and access control mechanisms that are not merely reactive but intrinsically proactive. Beyond external threats, the risk of insider threats—whether malicious or accidental—further compounds the complexity, demanding granular control over who can access what data, under what circumstances, and for what purpose.
Traditional API paradigms, predominantly REST (Representational State Transfer), have long served as the backbone of interconnectivity in distributed systems. RESTful APIs are widely adopted for their simplicity, statelessness, and adherence to standard HTTP methods, making them highly effective for resource-centric interactions. They typically expose a collection of resources, each identified by a unique URI, and manipulated using standard verbs like GET, POST, PUT, and DELETE. While REST has undeniably propelled the growth of web services and microservices architectures, it often presents significant limitations when it comes to sophisticated data querying and precise access control. One of the most frequently cited drawbacks is "over-fetching," where a client application receives more data fields than it actually requires for a particular operation. For instance, an API call to retrieve user information might return dozens of fields, including sensitive details like home address, phone number, or social security numbers, even if the client only needs the user's name and email for display. This excessive data transfer not only introduces network inefficiencies but also significantly broadens the attack surface, increasing the likelihood that sensitive information might be intercepted or misused by an unauthorized entity.
Conversely, "under-fetching" can also occur, necessitating multiple API calls to gather all the required data for a single view or operation. This leads to chatty networks, increased latency, and a more complex client-side development experience. To mitigate these issues, developers often resort to creating numerous custom REST endpoints, each finely tuned to a specific client’s data needs. While this approach can address over-fetching and under-fetching to some extent, it invariably leads to API sprawl, versioning headaches, and a labyrinthine maintenance burden. Each new endpoint represents an additional artifact to design, develop, test, document, and secure, making robust API Governance an increasingly challenging endeavor. The rigid, pre-defined data structures of RESTful responses often struggle to adapt to the dynamic and evolving data requirements of modern applications, forcing either frequent API versioning or less-than-ideal workarounds.
The inherent limitations of traditional REST APIs in providing granular control over data access, combined with the escalating demands for data security and regulatory compliance, highlight an urgent need for more sophisticated approaches. Organizations require mechanisms that can empower developers with flexible data access while simultaneously imposing strict, field-level security policies to prevent unauthorized data exposure. The goal is to move beyond the binary "all or nothing" access models towards a nuanced framework where data can be queried with surgical precision, ensuring that only the absolutely necessary information is ever exposed to the requesting client, thereby dramatically reducing security risks and bolstering the integrity of sensitive datasets. This fundamental shift in philosophy is precisely where GraphQL offers a compelling and transformative solution.
Understanding GraphQL: A Paradigm Shift in Data Fetching
At its core, GraphQL is not merely another API technology; it represents a fundamental paradigm shift in how client applications interact with data. Coined by Facebook in 2012 and open-sourced in 2015, GraphQL is a powerful query language for your API and a runtime for fulfilling those queries with your existing data. Unlike traditional REST APIs, where the server dictates the structure of the data it returns, GraphQL empowers the client to precisely specify what data it needs, and in what shape, across a single endpoint. This client-driven approach to data fetching is one of GraphQL's most compelling advantages, directly addressing many of the limitations inherent in REST.
The foundational principles of GraphQL underpin its efficiency and flexibility. Firstly, it champions declarative data fetching, meaning clients declare their data requirements rather than imperative instructions on how to fetch it. This allows the GraphQL server to intelligently resolve the request by aggregating data from various sources. Secondly, it is inherently client-driven, putting the consumer in control of the data contract. This dramatically reduces instances of over-fetching, as clients retrieve only the fields they explicitly request, and virtually eliminates under-fetching, as all necessary related data can be fetched in a single, well-formed query. Thirdly, GraphQL operates over a single endpoint, typically /graphql, simplifying the API architecture and reducing the complexity associated with managing numerous disparate endpoints in a RESTful design. Finally, GraphQL is strongly typed, meaning every piece of data that can be queried or mutated has a defined type within a schema. This schema acts as a contract between the client and the server, providing self-documenting capabilities, enabling powerful tooling for development, and facilitating robust data validation.
One of GraphQL's most celebrated contributions is its elegant solution to the problem of over-fetching. In a typical REST API, a request to /users/{id} might return a User object with fields like id, name, email, address, phone_number, date_of_birth, and social_security_number. If a client only needs the name and email for a simple display, it still receives all other fields, potentially including highly sensitive ones. With GraphQL, the client constructs a query that explicitly lists only the desired fields:
query GetUserNameAndEmail {
user(id: "123") {
name
email
}
}
The GraphQL server, upon receiving this query, will execute the necessary logic to fetch precisely name and email for the user with ID "123" and return only those two fields. This precision significantly reduces the amount of data transferred, improving network efficiency and, more critically, minimizing the exposure of sensitive information. By preventing the unnecessary transmission of data, GraphQL inherently reduces the attack surface, making it more difficult for malicious actors to intercept or exploit data that was not strictly required by the client.
Conversely, GraphQL also masterfully addresses the challenge of under-fetching. In REST, fetching a user and their associated posts would typically require two separate API calls: one to /users/{id} and another to /users/{id}/posts (or /posts?userId={id}). This introduces latency and complexity. GraphQL, through its ability to traverse relationships within the data graph, allows clients to fetch all related data in a single request. A client could query:
query GetUserWithPosts {
user(id: "123") {
name
email
posts {
title
content
}
}
}
This single query efficiently retrieves the user's name and email, along with the titles and content of all their posts, eliminating the need for multiple round-trips to the server. This ability to fetch complex, deeply nested data structures in a single request simplifies client-side development, improves application performance, and consolidates data access logic.
The cornerstone of any GraphQL API is its schema. The schema defines the entire graph of data that clients can query, modify (mutations), or subscribe to (subscriptions). It specifies the types of objects that can be fetched, their fields, and the relationships between them. This schema-first approach is incredibly powerful: * Strong Typing: Every field and argument has a defined type (e.g., String, Int, Boolean, custom types). This provides clarity, enables validation, and prevents common data-related errors. * Self-Documentation: The schema acts as a single source of truth for all available data and operations. Tools like GraphiQL or Apollo Studio can introspect the schema to provide auto-completion, validation, and interactive documentation, drastically improving developer experience. * Contract Enforcement: The schema enforces a strict contract between the client and the server. Clients can be confident in the data structure they will receive, and servers can validate incoming queries against the defined schema. * Evolvable APIs: GraphQL schemas are designed to be evolvable. New fields and types can be added without breaking existing clients, and deprecated fields can be marked as such, allowing for smooth API evolution without resorting to cumbersome versioning (e.g., /v1, /v2).
From a security perspective, the schema-first approach offers profound advantages. By providing a clear, explicit contract of what data can be accessed, it reduces ambiguity and helps in defining precise security policies. The client's ability to specify desired fields directly translates to reduced data exposure. If a sensitive field is not explicitly requested, it is simply not sent. Furthermore, the strong typing system ensures that data is consistently structured and validated, mitigating certain types of injection vulnerabilities and data corruption risks. The explicit nature of GraphQL queries also improves auditability; logs can clearly show exactly which fields were requested by a given client, providing a more detailed audit trail compared to broad REST endpoint calls. This combination of precision, strong typing, and client-driven data fetching makes GraphQL an incredibly powerful tool for building secure and efficient data access layers, moving away from broad access sharing towards targeted and controlled data delivery.
Enhancing Security with GraphQL's Granular Control
GraphQL's intrinsic design principles, particularly its client-driven data fetching and schema-first approach, lay a robust foundation for building highly secure data access layers. Beyond simply reducing over-fetching, GraphQL enables an unparalleled degree of granular control over data access, allowing developers to implement sophisticated security policies at various levels within the data graph. This section explores how GraphQL facilitates field-level security, argument-level validation, query depth and complexity limiting, and efficient rate limiting, all contributing to a significantly hardened API surface.
Field-Level Security: Precision in Data Exposure
One of the most powerful security capabilities of GraphQL is its ability to implement field-level security. In a GraphQL server, data fetching logic for each field of a type is handled by a dedicated function called a "resolver." This architecture allows developers to embed authorization and access control logic directly within individual resolvers. This means that access to specific data fields can be dynamically controlled based on the authenticated user's roles, permissions, context, or even the sensitivity level of the data itself.
Consider a User type that includes fields such as name, email, address, phone_number, and salary. While name and email might be publicly accessible or available to most authenticated users, address might require a "manager" role, phone_number a "support agent" role, and salary an "HR admin" role. With field-level security, the resolver for the salary field can check the requesting user's permissions before returning the data. If the user lacks the necessary "HR admin" role, the resolver can simply return null for that field or throw an authorization error, ensuring that sensitive compensation data is never exposed to unauthorized individuals, even if they explicitly request it in their query.
// Example of a resolver with field-level authorization
const resolvers = {
User: {
salary: (parent, args, context) => {
// 'context' typically contains authentication and user role information
if (context.user && context.user.roles.includes('HR_ADMIN')) {
return parent.salary; // Return the actual salary
}
// If unauthorized, return null or throw an error
return null;
// Or throw new AuthenticationError('You are not authorized to view salary information.');
},
// Other fields like name, email might not have such checks
name: (parent) => parent.name,
email: (parent) => parent.email,
},
};
The benefits of this approach are profound. It provides a surgical level of control, preventing unauthorized access to specific data points within a larger data object, rather than restricting access to the entire object. This fine-grained control allows for more flexible API designs that can serve diverse client needs while maintaining strict security boundaries. It also simplifies the security model, as authorization logic is collocated with the data fetching logic for each field, making it easier to reason about and maintain.
Argument-Level Security: Contextual Data Filtering
Beyond field-level control, GraphQL also offers opportunities for argument-level security. This allows developers to control access or filter data based on the arguments provided in a query. For instance, in an API that manages customer orders, a regular user might only be allowed to query their own orders. A query like orders(userId: "user_id") could be intercepted by a middleware or the resolver itself to ensure that userId matches the authenticated user's ID. If a user attempts to query orders for a different userId, the system can deny the request or return an empty set.
Similarly, an Article query might have an isPublished argument. While an administrator might be able to query articles(isPublished: false) to view drafts, a regular user might only be allowed to query articles(isPublished: true) or have the isPublished argument implicitly set to true by the server for their context. This contextual filtering ensures that clients only ever see data that is relevant and permissible to them, based on the specific parameters of their request.
Depth and Complexity Limiting: Mitigating DoS Attacks
One of the common concerns raised with GraphQL is the potential for denial-of-service (DoS) attacks through overly complex or deeply nested queries. A malicious or poorly constructed query could potentially traverse the entire data graph, consuming excessive server resources and bringing the API to a halt. For example, a query like user { friends { friends { friends { ... } } } } could recursively fetch an enormous amount of data.
To mitigate this risk, GraphQL servers can implement query depth limiting and query complexity limiting. * Depth Limiting: This mechanism sets a maximum allowable nesting level for a query. If a query exceeds this predefined depth, the server rejects it. For instance, setting a depth limit of 5 would prevent the user { friends { friends { friends { ... } } } } query from going indefinitely deep. * Complexity Limiting: This is a more sophisticated approach where each field in the schema is assigned a "complexity score." The server then calculates the total complexity score of an incoming query and rejects it if it exceeds a maximum threshold. For example, fetching a single User might have a score of 1, fetching User with 10 Posts might be 1 + (10 * Post_Score). Aggregate fields or fields that trigger expensive database operations can be assigned higher scores. This method provides a more accurate measure of resource consumption than mere depth and offers finer control over potential resource exhaustion attacks.
Implementing these limits, typically through server-side middleware or API Gateway policies, is crucial for maintaining the stability and availability of your GraphQL API.
Rate Limiting: Preventing Abuse and Ensuring Availability
While not exclusive to GraphQL, rate limiting remains an indispensable security measure for any public-facing API. It involves restricting the number of requests a user or client can make to an API within a given timeframe. This prevents various forms of abuse, including: * Brute-force attacks: Repeated attempts to guess credentials. * Denial-of-service (DoS) attacks: Overwhelming the server with a flood of requests. * Data scraping: Automated extraction of large amounts of data.
For GraphQL, rate limiting can be applied at different levels. A global rate limit can be enforced per IP address or authenticated user. More granular rate limiting can be applied per GraphQL operation type (query, mutation, subscription) or even per specific query/mutation name. For instance, a highly resource-intensive mutation might have a stricter rate limit than a simple query.
An API Gateway, as we will discuss in the next section, is an ideal place to implement and enforce these rate limiting policies efficiently, acting as the first line of defense before requests even reach the GraphQL server. This external enforcement offloads the burden from the GraphQL application itself, allowing it to focus purely on data resolution. The combination of GraphQL's inherent precision with these robust security mechanisms—field and argument-level control, depth and complexity limiting, and rate limiting—transforms it into an extraordinarily powerful tool for establishing truly granular and resilient data access security, dramatically reducing the risks associated with broad access sharing.
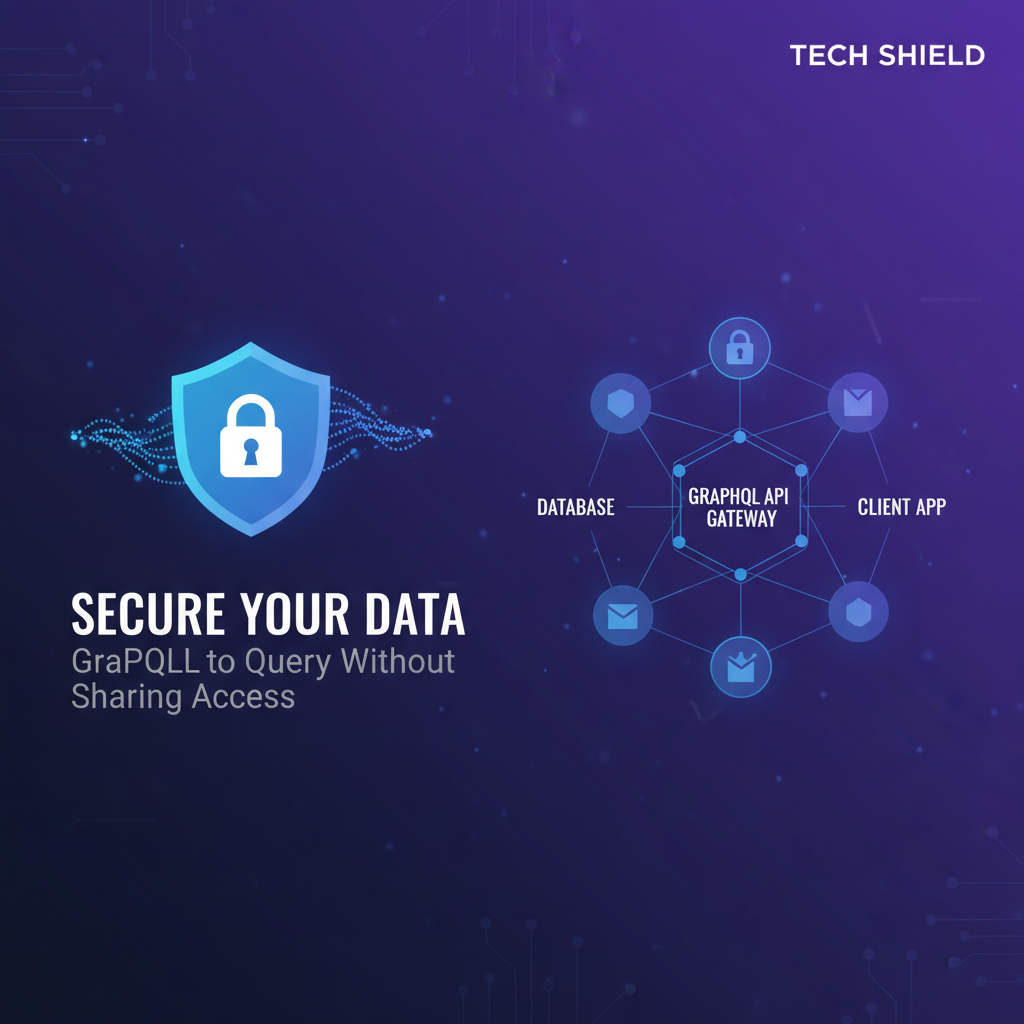
The Crucial Role of an API Gateway in GraphQL Security
While GraphQL fundamentally enhances data access security through its precise querying capabilities, deploying a standalone GraphQL server directly to the internet is akin to building a fortress without a drawbridge or watchtowers. This is where an API Gateway becomes not just beneficial, but an absolutely indispensable component of a secure and robust GraphQL architecture. An API Gateway acts as the single entry point for all API calls, sitting strategically between client applications and the backend services, including your GraphQL server. It functions as a powerful traffic cop, security guard, and intelligent router, centralizing critical cross-cutting concerns that would otherwise need to be redundantly implemented in each backend service.
Traditionally, API Gateways have provided a suite of essential functions that are crucial for managing and securing any API. These include: * Authentication and Authorization: Verifying the identity of the client and ensuring they have the necessary permissions to access the requested resources. * Traffic Management: Routing requests to appropriate backend services, load balancing across multiple instances, and managing traffic spikes. * Caching: Storing responses to frequently requested data to reduce load on backend services and improve response times. * Logging and Monitoring: Capturing detailed information about API calls, performance metrics, and potential errors for auditing, troubleshooting, and analytics. * Rate Limiting and Throttling: Controlling the number of requests a client can make within a specified period to prevent abuse and ensure service availability. * Security Policies: Enforcing IP whitelisting/blacklisting, applying Web Application Firewall (WAF) rules, and protecting against common web vulnerabilities. * Request/Response Transformation: Modifying requests before forwarding them to the backend or transforming responses before sending them back to the client.
For GraphQL APIs, the role of an API Gateway is even more pronounced and critical. While GraphQL itself provides field-level security, an API Gateway can act as the first line of defense, intercepting and validating GraphQL requests before they even reach the GraphQL server. This centralized approach offers several significant advantages for GraphQL security:
- Centralized Authentication and Authorization: The API Gateway can handle initial authentication (e.g., validating JWTs, API keys, OAuth tokens) for all incoming GraphQL requests. This offloads the authentication burden from the GraphQL server, allowing it to focus solely on data resolution. Based on the authenticated identity, the gateway can then perform initial authorization checks, for instance, rejecting requests from unauthenticated users or those lacking fundamental access rights to any GraphQL operation.
- GraphQL Request Validation and Transformation: Some advanced API Gateways are "GraphQL-aware," meaning they can parse and understand GraphQL queries. This allows them to perform pre-execution validation against the GraphQL schema, rejecting malformed or invalid queries at the edge. They can also transform requests, adding context (like user ID) or applying standard headers before forwarding to the GraphQL server, streamlining backend logic.
- Global Rate Limits and Quota Management: While GraphQL servers can implement their own rate limits, an API Gateway provides a centralized and externalized mechanism. It can enforce rate limits based on client IP, API key, authenticated user, or even specific GraphQL operation types. This prevents resource exhaustion attacks and ensures fair usage across all consumers of your API. For enterprise scenarios, the gateway can also manage quotas, allowing different clients or tiers to have varying request allowances.
- Security Policies at the Edge: The API Gateway is the ideal place to implement broader security policies. This includes IP whitelisting/blacklisting to restrict access to known sources, integrating with Web Application Firewalls (WAFs) to protect against common web exploits (like SQL injection or cross-site scripting, even if GraphQL inherently mitigates some), and applying circuit breakers to prevent cascading failures in case a backend service (including the GraphQL server) becomes unhealthy. By handling these concerns at the edge, the gateway shields the GraphQL server from direct exposure to internet-borne threats.
- Enhanced Logging and Monitoring: An API Gateway provides a single point for comprehensive logging of all API traffic. This includes details about incoming GraphQL queries, response times, errors, and client information. This centralized logging is invaluable for auditing, performance analysis, and security incident response. It allows security teams to detect anomalous behavior, identify potential attacks, and maintain a robust audit trail of data access requests. The ability to monitor traffic patterns and anomalies at the gateway level provides an early warning system against potential threats or performance degradations.
In this context, a platform like APIPark emerges as an exemplary solution, providing an all-in-one API Gateway and API Management Platform that is open-sourced under the Apache 2.0 license. APIPark is designed to help developers and enterprises manage, integrate, and deploy AI and REST services, but its robust feature set is equally powerful for securing and managing GraphQL APIs. APIPark’s capabilities directly support the stringent demands of securing data through a GraphQL interface:
- End-to-End API Lifecycle Management: APIPark assists with managing the entire lifecycle of APIs, including design, publication, invocation, and decommission. For GraphQL, this means ensuring schema evolution is managed securely and consistently.
- API Service Sharing within Teams: It allows for the centralized display of all API services, including GraphQL, making it easy for different departments and teams to find and use the required API services under controlled access.
- API Resource Access Requires Approval: Crucially, APIPark enables the activation of subscription approval features, ensuring that callers must subscribe to an API and await administrator approval before they can invoke it. This prevents unauthorized API calls and potential data breaches, acting as a crucial pre-authorization layer for GraphQL endpoints.
- Performance Rivaling Nginx: With impressive performance benchmarks (over 20,000 TPS on modest hardware), APIPark ensures that the API Gateway itself does not become a bottleneck, even under high traffic loads from complex GraphQL queries.
- Detailed API Call Logging and Powerful Data Analysis: APIPark provides comprehensive logging capabilities, recording every detail of each API call (including GraphQL queries). This feature is invaluable for businesses to quickly trace and troubleshoot issues, ensuring system stability and data security. The platform also analyzes historical call data to display long-term trends and performance changes, helping with preventive maintenance and identifying security anomalies before they escalate.
By integrating an advanced API Gateway like APIPark into your GraphQL architecture, you establish a powerful outer layer of defense that complements GraphQL's internal security mechanisms. The gateway handles the broader, infrastructural security and management concerns, freeing the GraphQL server to focus on efficient data resolution while ensuring that only authorized, validated, and non-abusive requests ever reach it. This layered security approach is fundamental to achieving robust data protection and maintaining high standards of API Governance in any enterprise environment.
APIPark is a high-performance AI gateway that allows you to securely access the most comprehensive LLM APIs globally on the APIPark platform, including OpenAI, Anthropic, Mistral, Llama2, Google Gemini, and more.Try APIPark now! 👇👇👇
Establishing Robust API Governance for GraphQL APIs
The technical prowess of GraphQL in enabling granular data access and the defensive capabilities of an API Gateway form a formidable security foundation. However, these tools alone are insufficient without a comprehensive and well-enforced API Governance framework. API Governance refers to the set of policies, processes, standards, and guidelines that dictate how APIs are designed, developed, deployed, consumed, and managed throughout their entire lifecycle. It's the strategic blueprint that ensures consistency, quality, security, and compliance across an organization's entire API ecosystem. For GraphQL APIs, where flexibility and client control are paramount, robust API Governance is not merely a best practice; it is an absolute necessity to prevent chaos, maintain security, and ensure long-term sustainability.
Why API Governance is Paramount for GraphQL
The unique characteristics of GraphQL, while offering immense benefits, also introduce specific governance challenges that must be addressed proactively: * Schema Consistency and Evolution: GraphQL's single endpoint and schema-driven nature mean that any change to the schema affects all clients. Without proper governance, schema evolution can become uncontrolled, leading to breaking changes, inconsistencies, and difficult maintenance. Governance ensures that schema changes are reviewed, backward compatibility is maintained (or clearly communicated), and deprecation strategies are followed. * Defining Security Policies: While field-level security is powerful, the underlying authorization logic needs to be consistent and universally applied according to organizational security policies. API Governance defines these policies, such as standard authentication mechanisms, authorization roles, data classification, and data masking requirements, ensuring they are uniformly implemented across all GraphQL resolvers. * Establishing Development Best Practices: To maximize the benefits of GraphQL and maintain a high-quality API, developers need clear guidelines on naming conventions, error handling, input validation, pagination, caching strategies, and performance optimization for resolvers. Governance provides these standards, preventing fragmentation and ensuring a consistent developer experience. * Compliance Requirements: Many industries are subject to stringent regulatory requirements regarding data handling (e.g., GDPR, HIPAA, PCI DSS). API Governance ensures that GraphQL APIs are designed and operated in a manner that fully complies with these regulations, including data residency requirements, audit trail mandates, and consent management. * Preventing "GraphQL Sprawl": Just as REST APIs can suffer from "API sprawl," GraphQL can experience "schema sprawl" if different teams build disparate, uncoordinated GraphQL services without a unified vision. Governance fosters a federated or unified graph approach, promoting reusability and preventing redundancy.
Governance Strategies for GraphQL: Implementing Control and Consistency
Implementing effective API Governance for GraphQL requires a multi-faceted approach:
- Schema Registry and Versioning: A centralized schema registry is a cornerstone of GraphQL governance. It acts as the single source of truth for all GraphQL schemas, tracking their evolution, providing diffs between versions, and enabling validation against breaking changes. Tools integrated with CI/CD pipelines can automatically prevent deployments that introduce breaking changes without explicit approval. While GraphQL aims to avoid traditional API versioning, a registry helps manage the schema's evolution gracefully, allowing clients to introspect current and deprecated fields.
- Automated Policy Enforcement: Wherever possible, security and quality policies should be enforced through automation rather than manual checks. This includes automated linters for schema design, security scanners that check for common vulnerabilities in GraphQL resolvers, and integration with API Gateway policies to enforce global rules like rate limiting, IP whitelisting, and access approval workflows. For instance, APIPark, as an API Gateway and management platform, supports the activation of subscription approval features, directly enforcing a key governance policy regarding API access.
- Standardized Authentication and Authorization Frameworks: Define and enforce a standard framework for authentication (e.g., OAuth 2.0, OpenID Connect, JWTs) and authorization (e.g., RBAC, ABAC) across all GraphQL services. This ensures consistency and simplifies the security model. The API Gateway plays a critical role here by centralizing the initial authentication handshake, passing authenticated user context to the GraphQL server, which then applies granular authorization rules in its resolvers.
- Documentation and Developer Portals: Comprehensive and up-to-date documentation is vital for the adoption and correct usage of GraphQL APIs. A developer portal, potentially integrated with an API Gateway like APIPark which offers an API developer portal, provides a central hub for discovering APIs, accessing documentation, understanding usage policies, and managing subscriptions. This transparency is key to driving consistent and secure API consumption.
- Monitoring, Auditing, and Logging Standards: Define strict standards for what information must be logged for every GraphQL query and mutation. This includes request details, response times, errors, and critical security events (e.g., unauthorized access attempts). These logs, especially those collected by an API Gateway like APIPark with its "Detailed API Call Logging" and "Powerful Data Analysis" features, are invaluable for security audits, compliance reporting, and detecting anomalies or malicious activities. Centralized logging and monitoring systems are essential for providing a holistic view of API health and security posture.
- Regular Security Audits and Penetration Testing: Beyond automated checks, regular manual security audits, code reviews of resolver logic, and penetration testing specifically targeting GraphQL APIs are crucial. This helps identify complex vulnerabilities that automated tools might miss, such as business logic flaws in authorization or subtle issues in data filtration.
Impact on Data Security
A well-governed GraphQL API inherently reduces security risks by embedding best practices and security considerations from the very initial design phase through to production deployment. It ensures that: * Sensitive Data is Protected by Design: Policies dictate that sensitive fields are always protected by field-level authorization or data masking. * Consistent Security Controls: All developers follow the same security protocols, minimizing the chance of security gaps due to inconsistent implementation. * Auditability and Compliance: Detailed logging and adherence to defined standards make it easier to demonstrate compliance with regulatory requirements and to conduct post-incident forensics. * Managed Evolution: Schema changes are controlled, preventing accidental data exposure due to schema mismatches or unintended data returns.
In essence, API Governance transforms the raw power of GraphQL and the protective layer of an API Gateway into a cohesive, secure, and manageable data access solution. It moves an organization from ad-hoc API development to a disciplined, strategic approach where data security is not an afterthought but an intrinsic attribute of every API interaction.
Practical Implementation Strategies for Secure GraphQL
Building a secure GraphQL API requires more than just understanding its principles; it demands meticulous implementation of security best practices throughout the development and deployment lifecycle. Combining GraphQL's inherent capabilities with robust security strategies ensures that data is precisely queried without compromising its integrity or exposing it to unauthorized access. This section outlines practical implementation strategies focusing on authentication, authorization, data masking, persistent queries, and comprehensive monitoring.
Authentication & Authorization: The Gatekeepers of Data
The first and most critical step in securing any API, including GraphQL, is robust authentication and authorization. * Authentication: This is the process of verifying a user's identity. For GraphQL, standard web authentication mechanisms like JWT (JSON Web Tokens) or OAuth 2.0 are commonly employed. * JWTs: After a user logs in, the authentication server issues a JWT, which the client includes in subsequent requests (typically in the Authorization header). The API Gateway (or the GraphQL server itself) validates the JWT's signature and expiration. JWTs can carry user identity and basic role information. * OAuth 2.0: This protocol is ideal for delegated authorization, allowing third-party applications to access a user's data without ever seeing their credentials. The API Gateway can handle the OAuth flow and pass the validated user context to the GraphQL service. * Integrating with Existing Identity Providers: Organizations typically have existing identity management systems (e.g., Okta, Auth0, Active Directory). The GraphQL API should integrate seamlessly with these providers, leveraging established user directories and single sign-on (SSO) capabilities. This centralization simplifies user management and strengthens security. * Role-Based Access Control (RBAC) and Attribute-Based Access Control (ABAC) in GraphQL Resolvers: Once a user is authenticated, authorization determines what resources they are permitted to access or what actions they can perform. * RBAC: Permissions are tied to roles (e.g., "admin," "editor," "viewer"). In GraphQL, resolvers can check the authenticated user's roles (obtained from the JWT or session) and grant or deny access to fields or perform specific operations. For example, a deleteUser mutation might only be allowed for users with the "admin" role. * ABAC: This offers even finer-grained control, where permissions are granted based on attributes of the user, the resource, and the environment (e.g., "user can only access documents they own, if the document is in draft state, and only from within the corporate network"). ABAC logic can be implemented within GraphQL resolvers by dynamically evaluating these attributes before resolving a field or executing a mutation. This allows for highly flexible and context-aware authorization.
Data Masking and Redaction: Hiding Sensitive Information
Even after granular authorization, there might be scenarios where certain sensitive data fields should never be fully exposed, even to authorized users, or only under specific conditions. Data masking and redaction techniques can be applied at the resolver level: * Partial Masking: For fields like credit card numbers or social security numbers, only a portion might be revealed (e.g., "XXXX-XXXX-XXXX-1234"). The resolver for such a field would transform the actual data before returning it. * Conditional Redaction: Based on the user's role or the context of the request, an entire sensitive field might be removed (null) or replaced with a generic placeholder (e.g., [REDACTED]). For instance, if a user is querying their own profile, they might see their full phone number, but if a support agent queries it, they might only see the last four digits. These techniques ensure that sensitive data is protected even within the application boundary, minimizing the risk of accidental exposure.
Persistent Queries/Whitelisting: Proactive Security
For highly sensitive GraphQL deployments, such as those in regulated industries or internal-only APIs, persistent queries (also known as query whitelisting) offer a powerful security measure. Instead of allowing clients to send arbitrary, ad-hoc GraphQL queries, this approach requires that all permissible queries are registered and approved on the server beforehand. * How it Works: Clients send a unique identifier (hash or name) for a pre-registered query, rather than the full GraphQL query string. The server then looks up the corresponding full query from its whitelist and executes it. If the client sends an unregistered query, or if the identifier doesn't match an approved query, the request is rejected. * Benefits: * Prevents Malicious Queries: Eliminates the risk of complex or resource-intensive malicious queries from ever reaching the execution engine. * Performance Optimization: Pre-parsing and validating queries can lead to minor performance gains. * Reduced Attack Surface: Significantly reduces the attack surface by limiting the types of operations clients can perform. * Simplified Logging: Logs become cleaner as only identifiers are recorded, with the full query available in the registry. This strategy essentially trades some of GraphQL's dynamic flexibility for maximum security, making it suitable for environments where strict control over data access patterns is paramount.
Monitoring and Logging: Vigilance and Forensics
Comprehensive monitoring and logging are non-negotiable for maintaining a secure GraphQL API. * Detailed Logging: Every GraphQL query and mutation execution should be logged, including: * Client IP address and user agent. * Authenticated user ID. * The exact query string (or persistent query ID). * Variables used in the query. * Execution time. * HTTP status code and any errors returned. * Number of fields resolved. * The API Gateway (like APIPark) is an excellent place to capture these logs centrally before requests reach the GraphQL server, providing a complete picture across all APIs. * Performance Monitoring: Track resolver execution times, overall query latency, and error rates. Sudden spikes in latency or error rates can indicate a performance bottleneck or a potential DoS attempt. * Security Event Monitoring: Monitor for failed authentication attempts, authorization failures, query depth/complexity limit violations, and rate limit breaches. Integrate these alerts with security information and event management (SIEM) systems for real-time threat detection and incident response. * Data Analysis: Leveraging platforms with "Powerful Data Analysis" features, such as APIPark, allows businesses to analyze historical call data, identify long-term trends, detect anomalies (e.g., unusual data access patterns from a user), and conduct preventive maintenance before issues escalate into security incidents.
Testing for Security Vulnerabilities: Proactive Defense
Rigorous security testing is essential to uncover vulnerabilities before they are exploited in production. * Automated Security Scanners: Utilize tools that can automatically scan your GraphQL schema and resolver code for common security vulnerabilities, such as insecure direct object references, improper input validation, or misconfigurations. * Fuzz Testing: Send malformed, unexpected, or excessively large inputs to your GraphQL API to uncover crashes, error handling issues, or potential injection vulnerabilities. * Penetration Testing: Engage security professionals to conduct simulated attacks against your GraphQL API. These ethical hackers can identify business logic flaws, authorization bypasses, and other sophisticated vulnerabilities that automated tools might miss. * Specific GraphQL Security Testing Tools: Dedicated tools exist that understand GraphQL's structure and can identify specific GraphQL-related vulnerabilities, such as introspection abuse, query flooding, or batching attacks.
By diligently implementing these practical strategies, organizations can establish a multi-layered defense around their GraphQL APIs. This approach leverages GraphQL's precision, reinforces it with strong authentication and authorization, protects data through masking, controls query patterns with whitelisting, and maintains constant vigilance through comprehensive monitoring and testing. The result is a highly secure data access layer that allows applications to query precisely what they need, without indiscriminately sharing access to the vast underlying data, thereby upholding the highest standards of data protection and API Governance.
Case Studies and Real-World Impact
The adoption of GraphQL, coupled with robust API Gateway solutions and comprehensive API Governance, is not merely a theoretical advantage; it's a proven strategy that is transforming how diverse industries manage and secure their data. Real-world applications demonstrate how this powerful combination enables organizations to achieve flexible, client-driven data access while simultaneously fortifying their security posture against increasingly sophisticated threats.
Financial Technology (Fintech): Precision in Sensitive Data
In the highly regulated and security-critical world of Fintech, access to financial data must be incredibly granular. Traditional REST APIs often struggled with the trade-off between providing rich data to applications (e.g., for detailed portfolio views, transaction histories) and strictly controlling access to individual fields (e.g., account numbers, balances, PII). * Impact: Fintech companies have embraced GraphQL to allow their various client applications (web portals, mobile apps, third-party integrations) to fetch exactly the financial data they need. For instance, a mobile app displaying a quick balance might only request account.balance, while an investment analytics tool might pull account.transactions { date, amount, description, type }. Field-level security, enforced in GraphQL resolvers, ensures that only authenticated and authorized users (e.g., the account owner or an authorized financial advisor) can access sensitive fields like full account numbers or social security details. An API Gateway centrally handles token validation and rate limiting for all incoming requests, providing a critical layer of defense against fraud and data breaches. API Governance ensures that all financial data types adhere to strict compliance standards (e.g., PCI DSS), and that schema changes are carefully reviewed to avoid accidental exposure of new sensitive fields. The ability to log precise GraphQL queries (often facilitated by an API Gateway's detailed logging) provides an undeniable audit trail for regulatory compliance.
Healthcare: Secure and Compliant Patient Information
Healthcare APIs deal with protected health information (PHI), making data security and HIPAA compliance paramount. Over-fetching PHI is not only a security risk but a legal liability. * Impact: Healthcare providers and developers are leveraging GraphQL to create flexible yet secure interfaces for electronic health records (EHR), patient portals, and telehealth applications. A doctor's portal might query patient { name, age, currentMedications { name, dosage } }, while a billing department application might query patient { name, insuranceInfo { provider, policyNumber } }. The GraphQL schema defines precise types for PHI, and resolvers implement strict RBAC or ABAC rules. For example, a diagnosis field might only be accessible to a physician, while a billingAddress might be visible to administrative staff. An API Gateway enforces access control at the edge, ensuring only authorized healthcare applications can even attempt to query patient data. Features like API Governance through a schema registry ensure that schema updates comply with evolving medical standards and privacy regulations, preventing any new data fields from being exposed without explicit security review. Data masking within resolvers can redact sensitive identifiers when data is shared with analytics platforms, further safeguarding patient privacy.
E-commerce: Personalized Experiences with Data Control
E-commerce platforms thrive on personalized user experiences, which requires access to vast amounts of user and product data. Balancing personalization with privacy is a constant challenge. * Impact: E-commerce giants use GraphQL to power their mobile apps, progressive web apps, and partner integrations, allowing clients to fetch highly customized data sets. A customer browsing products might query product { id, name, price, images { url, altText } }, while a logged-in user's shopping cart might fetch cart { items { product { name, price }, quantity }, total }. Importantly, sensitive user data like payment details or full shipping addresses are heavily protected. GraphQL resolvers ensure that payment tokens are handled securely, and personal addresses are only visible to the user or an authorized support agent during an active support session. The API Gateway provides robust rate limiting to prevent product scraping or brute-force attacks on user accounts, while API Governance ensures consistency across various services, from inventory to customer profiles. This allows for rich, personalized user experiences without broadly exposing sensitive purchasing patterns or personal information.
These examples underscore a common thread: GraphQL empowers clients to be selective about the data they receive, which is a fundamental security improvement. When this power is harnessed within a well-defined API Governance framework and protected by the robust capabilities of an API Gateway (such as APIPark, with its emphasis on detailed logging, access control, and performance), organizations can build data access layers that are not only highly efficient and flexible but also inherently secure and compliant. The result is a digital ecosystem where data utility and data security are no longer conflicting objectives but harmonious outcomes.
| Feature / Aspect | Traditional REST API | GraphQL API | Security Implications |
|---|---|---|---|
| Data Fetching Model | Resource-centric, multiple endpoints for related data. Server dictates response structure. | Graph-centric, single endpoint. Client dictates desired data shape and fields. | REST: Prone to over-fetching (unnecessary data exposure) and under-fetching (multiple requests, increased attack surface). GraphQL: Reduces over-fetching, minimizes data exposure, single request simplifies auditing. |
| Granular Access | Typically resource-level (e.g., access to entire /user resource). Fine-grained control often requires custom endpoints or complex server-side logic. |
Field-level and argument-level control via resolvers. Precise authorization logic for each data point. | REST: Higher risk of exposing sensitive fields if not explicitly filtered. GraphQL: Enables surgical precision; sensitive fields can be null or redacted if user lacks permission, even if requested. |
| Schema/Contract | Implicit or externally documented (OpenAPI/Swagger). Changes often require versioning (/v1, /v2). |
Explicit, strongly typed schema (SDL). Self-documenting, introspectable. Evolvable without major versioning. | REST: Inconsistent contracts can lead to security gaps. Versioning increases maintenance complexity. GraphQL: Strong typing ensures data integrity, reduces ambiguity. Schema registry with API Governance ensures controlled evolution and security review. |
| DoS Vulnerabilities | Rate limiting generally sufficient. | Potential for complex, deeply nested, or resource-intensive queries. | REST: Less prone to specific query-depth attacks. GraphQL: Requires specific mitigations like query depth/complexity limiting and persistent queries. API Gateway crucial for enforcing these at the edge. |
| Caching | Leverages standard HTTP caching mechanisms (CDN, client-side). | More complex due to dynamic queries. Often requires client-side caching or custom solutions. | REST: Easier to implement caching at multiple layers, but cache invalidation can be tricky for sensitive data. GraphQL: Dynamic nature requires careful consideration to avoid caching sensitive data improperly. |
| Monitoring/Logging | Logs endpoint calls, HTTP status, general request details. | Logs exact query strings, variables, resolved fields, execution times. | REST: Can be less granular for what data was actually accessed. GraphQL: Provides highly granular audit trails of specific data points requested, crucial for forensics and compliance (especially with API Gateway integration like APIPark). |
| API Gateway Role | Essential for authentication, authorization, rate limiting, traffic management. | Even more critical for initial query validation, depth/complexity limiting, authentication, and overall API Governance. | REST: Gateway acts as a first line of defense. GraphQL: Gateway is paramount for pre-processing, validating, and securing dynamic queries before they hit the server, centralizing security policies and providing detailed insights. |
| API Governance | Focus on endpoint consistency, documentation, lifecycle. | Focus on schema evolution, resolver security policies, data masking, consistent authorization logic. | REST: Governance prevents endpoint sprawl and ensures consistency. GraphQL: Governance prevents schema chaos, ensures consistent field-level security, and aligns with data privacy regulations by design. |
Conclusion: Empowering Data Access with Unwavering Security
In an era defined by the exponential growth of data and an increasingly sophisticated threat landscape, the imperative to secure sensitive information while simultaneously fostering agile development and insightful analytics has never been more critical. The traditional approaches to API design, particularly RESTful services, while foundational, often present inherent limitations when it comes to achieving the precise, granular data access control that modern enterprises demand. The specter of over-fetching, accidental data exposure, and the arduous task of managing proliferating custom endpoints have long represented significant security vulnerabilities and operational burdens.
GraphQL emerges as a powerful and transformative solution, fundamentally altering the paradigm of data interaction. By empowering clients to declaratively specify their exact data requirements, it eliminates the inefficiencies and security risks associated with over-fetching, ensuring that only the absolutely necessary information traverses the network. This client-driven precision, combined with GraphQL's strong typing system and schema-first approach, establishes a robust foundation for building inherently more secure and flexible data access layers. Its ability to implement field-level and argument-level authorization within resolvers offers an unparalleled degree of granular control, allowing organizations to safeguard individual data points based on user roles, permissions, and contextual factors. Furthermore, GraphQL's architecture lends itself to proactive security measures such as query depth and complexity limiting, mitigating potential denial-of-service attacks.
However, the full potential of GraphQL for data security is realized when it operates in concert with a sophisticated API Gateway and a meticulously implemented API Governance framework. An API Gateway acts as the essential first line of defense, centralizing critical cross-cutting concerns like authentication, global rate limiting, and advanced threat protection before requests ever reach the GraphQL server. It enforces overarching security policies, routes traffic intelligently, and provides invaluable centralized logging and monitoring capabilities, creating a comprehensive audit trail that is indispensable for security forensics and regulatory compliance. Tools like APIPark exemplify how a modern API Gateway and API management platform can seamlessly integrate with and fortify GraphQL deployments, offering features like access approval, detailed logging, and high performance to ensure both security and scalability.
Complementing these technical safeguards, a robust API Governance strategy provides the overarching strategic framework. It defines the policies, processes, and standards that guide the entire API lifecycle, from design to deprecation. For GraphQL, this means ensuring schema consistency, enforcing uniform security policies across all resolvers, establishing development best practices, and guaranteeing compliance with stringent data protection regulations. A well-governed GraphQL API inherently reduces security risks by embedding security by design, promoting consistency, and enabling proactive management of schema evolution.
The synergy of GraphQL's precise data querying, an API Gateway's centralized security enforcement, and a comprehensive API Governance framework represents the zenith of modern data access security. It moves beyond the limitations of broad access sharing, enabling organizations to build dynamic, client-friendly applications that harness the full power of their data, while rigorously protecting sensitive information against unauthorized exposure and misuse. This powerful trifecta ensures that empowering developers with flexible data access and safeguarding sensitive information are no longer conflicting objectives but rather harmonious and achievable realities, laying the groundwork for a secure, compliant, and innovatively driven digital future.
Frequently Asked Questions (FAQ)
1. What is the primary advantage of GraphQL over REST for data security? The primary advantage of GraphQL for data security lies in its client-driven query model, which significantly reduces "over-fetching." Clients can precisely specify only the fields they need, minimizing the amount of sensitive data transmitted and thereby reducing the attack surface. In contrast, REST APIs often return fixed data structures, frequently exposing more data than necessary. GraphQL also enables granular, field-level authorization directly within its resolvers, offering finer control over access to individual data points.
2. How does an API Gateway enhance GraphQL security, given GraphQL's built-in security features? An API Gateway provides a crucial outer layer of defense for GraphQL APIs, complementing its internal security features. It centralizes essential security functions like primary authentication, global rate limiting, IP whitelisting/blacklisting, and WAF integration before requests reach the GraphQL server. This offloads resource-intensive tasks, protects the GraphQL server from direct exposure to internet-borne threats, and provides centralized logging and monitoring for all API traffic, enhancing overall API Governance. Platforms like APIPark specifically offer these capabilities, including subscription approval and detailed call logging.
3. What is API Governance, and why is it particularly important for GraphQL APIs? API Governance is a framework of policies, processes, and standards guiding the entire lifecycle of APIs. For GraphQL, it's particularly important because GraphQL's flexibility can lead to inconsistencies if not properly managed. Governance ensures schema consistency and controlled evolution, enforces uniform security policies (e.g., field-level authorization standards, data masking), dictates best practices for resolvers, ensures compliance with data regulations, and prevents "schema sprawl." It ensures that all teams adhere to a unified, secure approach to GraphQL API development and consumption.
4. Can GraphQL prevent all types of cyberattacks on its own? No, GraphQL itself cannot prevent all types of cyberattacks. While it significantly mitigates over-fetching and allows for granular authorization, it still requires robust implementation of other security measures. Vulnerabilities like SQL injection (if resolvers are not securely implemented), authentication bypasses, DoS attacks (if query depth/complexity limiting is absent), or insecure configurations can still exist. A multi-layered security approach, combining GraphQL with an API Gateway, strong authentication/authorization, and comprehensive API Governance, is essential for holistic protection.
5. How do "Persistent Queries" (Whitelisting) work with GraphQL for enhanced security? Persistent queries, or query whitelisting, enhance GraphQL security by requiring all permissible client queries to be pre-registered and approved on the server. Instead of sending ad-hoc GraphQL queries, clients send a unique identifier (e.g., a hash or a name) corresponding to an approved query. The server then executes the pre-approved query. This approach eliminates the risk of malicious or overly complex ad-hoc queries from ever reaching the execution engine, significantly reducing the attack surface and providing maximum control over data access patterns, particularly in highly regulated environments.
🚀You can securely and efficiently call the OpenAI API on APIPark in just two steps:
Step 1: Deploy the APIPark AI gateway in 5 minutes.
APIPark is developed based on Golang, offering strong product performance and low development and maintenance costs. You can deploy APIPark with a single command line.
curl -sSO https://download.apipark.com/install/quick-start.sh; bash quick-start.sh

In my experience, you can see the successful deployment interface within 5 to 10 minutes. Then, you can log in to APIPark using your account.

Step 2: Call the OpenAI API.

