What is a Circuit Breaker & How Does It Work?



In the intricate tapestry of modern software architecture, where microservices dance across networks and applications rely on a myriad of external dependencies, the threat of failure looms perpetually. A single hiccup in one component, an unexpected spike in latency from a third-party service, or an overloaded database can swiftly ripple through an entire system, transforming a minor glitch into a catastrophic cascade. This inherent fragility of distributed systems necessitates robust, proactive resilience strategies. Among the most vital of these strategies is the Circuit Breaker Pattern – a deceptively simple yet profoundly powerful mechanism designed to safeguard system stability and user experience in the face of inevitable imperfections.
This article delves deep into the "what" and "how" of the Circuit Breaker Pattern, unraveling its core principles, operational mechanics, and indispensable role in modern distributed architectures. We will explore its critical application within api gateways, which serve as the frontline defenders of microservices, and its increasingly vital function in LLM Gateways, where the unique challenges of integrating large language models demand sophisticated resilience. By understanding this pattern, developers and architects can equip their systems with the resilience needed to not just survive, but thrive, in the complex, interconnected digital landscape.
The Analogy: Understanding the Electrical Circuit Breaker
To truly grasp the essence of the software circuit breaker pattern, it's helpful to first consider its namesake: the humble electrical circuit breaker. Imagine the wiring within your home, powering countless appliances from the refrigerator to your computer. Each of these devices draws a certain amount of electrical current. If, for some reason, an appliance malfunctions or too many high-power devices are plugged into a single circuit, an excessive amount of current might flow through the wires. This "overload" can cause wires to overheat, melt their insulation, and potentially lead to electrical fires or damage to expensive equipment.
This is precisely where the electrical circuit breaker steps in. Installed in your home's electrical panel, it acts as a vigilant guardian. When it detects an abnormally high current – indicating an overload or a short circuit – it "trips" or "opens" instantaneously. This action physically breaks the electrical connection, cutting off power to that particular circuit. By doing so, it protects the wiring, the appliances, and ultimately your home from potential damage. Once the fault is cleared (e.g., the faulty appliance is unplugged, or the overloaded devices are redistributed), the circuit breaker can be manually reset, closing the circuit and restoring power.
The genius of the electrical circuit breaker lies in its proactive protection: it doesn't wait for disaster to strike. It senses an impending problem and takes decisive action to prevent further harm, allowing the faulty component to be addressed without jeopardizing the entire system. This very principle forms the bedrock of the software circuit breaker pattern, albeit adapted for the abstract world of network requests, service dependencies, and logical failures.
The Software Circuit Breaker Pattern: Definition and Core Principles
Transitioning from the tangible world of electrons and wires to the ethereal domain of bytes and network packets, the Software Circuit Breaker Pattern emerges as a critical design pattern within distributed systems. Its primary objective is to prevent an application from repeatedly attempting to invoke a service or operation that is likely to fail, thereby protecting both the client application and the potentially overloaded or failing service. This pattern is not merely about error handling; it's about intelligent failure management, ensuring that localized failures do not propagate and cripple the entire system.
At its core, the software circuit breaker encapsulates calls to a service (e.g., a database, an external API, a microservice endpoint) within an object that monitors for failures. If the failures reach a certain threshold within a defined period, the circuit breaker "trips" or "opens," preventing further calls to that service for a specific duration. During this period, instead of attempting to invoke the failing service, the circuit breaker immediately returns an error, a fallback response, or a cached result to the client. This "fast-fail" mechanism is crucial for several reasons:
- Isolation: It isolates the failing service, preventing the client application from continually bombarding it with requests, which would only exacerbate its problems and delay its recovery. This is particularly vital in microservice architectures where services depend on each other. If Service A depends on Service B, and Service B becomes unavailable, a circuit breaker on Service A's calls to Service B prevents Service A from wasting resources (threads, network connections) on failed attempts and potentially becoming unavailable itself due to resource exhaustion.
- Rapid Failure Detection: Unlike simple timeouts or retries, which involve waiting for an operation to fail repeatedly, a circuit breaker proactively recognizes a sustained pattern of failures. Once the threshold is met, it immediately stops sending requests, providing quicker feedback to the client application and reducing the impact of prolonged service degradation.
- Graceful Degradation: By immediately failing or returning a fallback, the circuit breaker allows the client application to implement alternative strategies. This could mean presenting a slightly degraded user experience (e.g., showing cached data instead of real-time, displaying a "feature unavailable" message) rather than a complete system outage or an endless spinning loader. It shifts the experience from an abrupt crash to a more controlled, less jarring user interaction.
The circuit breaker pattern differs fundamentally from basic retry mechanisms. While retries attempt to overcome transient network glitches or momentary service unavailability, they can be detrimental if the underlying service is genuinely unhealthy or overwhelmed. Continuously retrying a failing service can push it further into distress, creating a "death spiral." The circuit breaker, on the other hand, acts as a self-healing or self-protective mechanism, giving the service breathing room to recover by temporarily halting the onslaught of requests. It introduces a systemic resilience layer, ensuring that failure in one domain doesn't become a widespread contagion. It's a testament to the adage that sometimes, the best way to move forward is to strategically pause and allow for recovery.
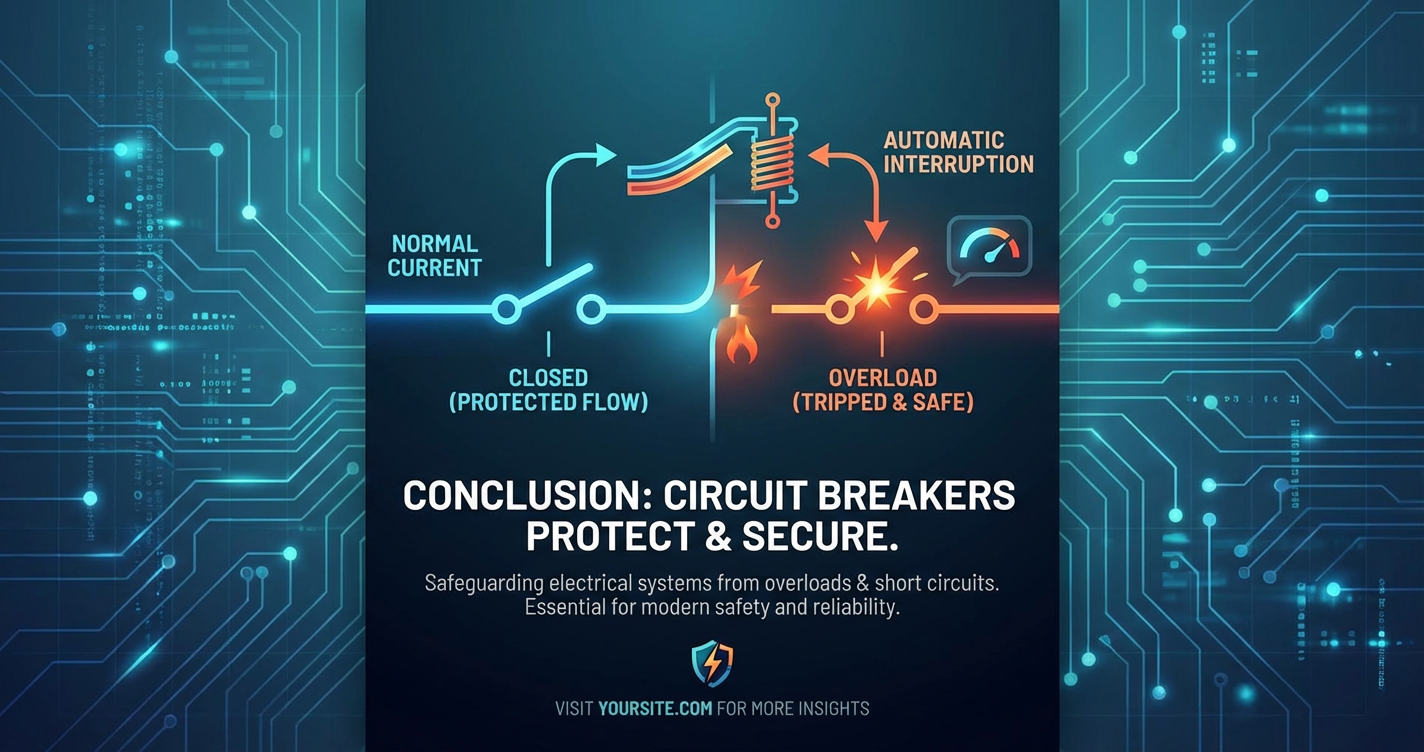
The States of a Circuit Breaker
A circuit breaker, in its software incarnation, operates through a well-defined state machine. This state machine dictates how it behaves in response to successful and failed operations, allowing it to dynamically adapt to the health of the underlying service. There are typically three primary states: Closed, Open, and Half-Open. Understanding the transitions between these states is paramount to grasping the pattern's efficacy.
1. Closed State
The Closed state is the default operating mode of the circuit breaker. In this state, everything is assumed to be functioning normally. Calls to the protected service pass through the circuit breaker without any immediate intervention. It acts as a transparent proxy, simply forwarding requests to the target service. However, while in the Closed state, the circuit breaker is far from passive; it is diligently monitoring the operations.
Its primary activity in this state is to track the number of failures. This tracking can be implemented in various ways:
- Failure Counter: A simple counter that increments with each detected failure (e.g., an exception, a timeout, a specific HTTP error code like 5xx).
- Success Counter: Sometimes, a counter for successful operations is also maintained to calculate a failure rate.
- Sliding Window: More sophisticated implementations use a "sliding window" approach. Instead of just a raw count, they might monitor the failure rate over a specific time interval (e.g., "5 failures within the last 10 seconds" or "30% error rate over the last 60 seconds"). This prevents a few transient failures from tripping the breaker prematurely if the overall success rate remains high.
A critical parameter in the Closed state is the failure threshold. This threshold defines the conditions under which the circuit breaker should transition to the Open state. Examples include:
- Consecutive Failures: "If 5 consecutive calls fail."
- Error Rate Percentage: "If the error rate exceeds 50% within a 1-minute window."
- Total Failures: "If 10 failures occur within a 30-second window, regardless of successes."
Once the monitored failures meet or exceed this predefined threshold, the circuit breaker immediately "trips" and transitions to the Open state. This is the moment it decides that the underlying service is unhealthy enough to warrant intervention.
2. Open State
When the circuit breaker transitions to the Open state, it signifies a critical decision: the protected service is deemed unhealthy or overwhelmed, and direct calls to it must cease immediately. While in the Open state, the circuit breaker will short-circuit any incoming requests destined for the protected service. This means instead of attempting to invoke the service, it will immediately:
- Return an error: Typically a
CircuitBreakerOpenExceptionor a similar custom error. - Return a fallback response: A pre-configured default value, a cached result, or an empty dataset.
- Execute a fallback method: Invoke an alternative, simpler operation that doesn't rely on the failing service.
This "fast-fail" mechanism is crucial. It achieves several vital goals:
- Protects the failing service: By stopping the flood of requests, it gives the backend service a much-needed respite, allowing it time to recover from overload, resource exhaustion, or other issues. Continuing to send requests would only worsen its state.
- Protects the client application: It prevents the client from hanging indefinitely, consuming valuable resources (threads, memory, network connections) while waiting for a response that will likely never come or will be an error. It provides immediate feedback, allowing the client to take alternative actions swiftly.
- Prevents cascading failures: Without the circuit breaker, an overloaded service could cause its callers to become overloaded, which in turn could overload their callers, leading to a domino effect that takes down a significant portion of the system.
A fundamental aspect of the Open state is the timeout duration (also known as the wait time or sleep window). When the circuit breaker opens, it sets an internal timer. During this timeout period, all requests are short-circuited. The purpose of this duration is to provide sufficient time for the unhealthy service to potentially recover. Only after this timeout period expires does the circuit breaker transition to the Half-Open state. The duration is a critical configuration parameter; too short, and the service might not have enough time to recover; too long, and the system might remain in a degraded state unnecessarily.
3. Half-Open State
After the configured timeout duration in the Open state has elapsed, the circuit breaker automatically transitions to the Half-Open state. This state represents a cautious probe, a tentative attempt to determine if the underlying service has recovered sufficiently to handle traffic again.
While in the Half-Open state, the circuit breaker allows a limited number of "test" requests to pass through to the protected service. This is a critical distinction: it doesn't immediately open the floodgates to all traffic. The number of test requests is typically a small, configurable value (e.g., 1, 5, or 10 requests).
The outcome of these test requests dictates the next state transition:
- If the test requests succeed: If the designated number of test requests successfully invoke the service and return valid responses (i.e., no failures or errors are detected), the circuit breaker concludes that the service has likely recovered. It then immediately transitions back to the
Closedstate, allowing all subsequent requests to pass through again. The failure counter is usually reset at this point. - If any of the test requests fail: If even one of the test requests (or a significant portion, depending on configuration) fails while in the
Half-Openstate, it suggests that the service is still unhealthy or has regressed. In this scenario, the circuit breaker immediately transitions back to theOpenstate, restarting the timeout duration. This prevents another premature full opening of traffic to a still-failing service.
The Half-Open state is essential for graceful recovery. It allows the system to cautiously re-engage with a previously failing service without overwhelming it again if it's still struggling. It balances the need for recovery with the need for continued protection.
Visualizing the States and Transitions
The interplay between these states can be visualized as a finite state machine:
+-----------+ (Failures reach threshold) +----------+
| | ----------------------------------------------> | |
| Closed | | Open |
| (Normal) | <-------------------------------------------- (Success after test) |
+-----------+ +----------+
^ |
| | (Timeout elapsed)
| V
| +----------+
| (Failures during test) | Half-Open|
--------------------------------------------------------- < (Probe) |
+----------+
| State | Description | Behavior | Transition To |
|---|---|---|---|
| Closed | The default state. Operations are allowed, but failures are being monitored. | Requests are sent to the protected service. A failure counter or rate monitor is active. | Open: When failures reach a predefined threshold (e.g., X consecutive errors, Y% error rate over T time). |
| Open | The service is deemed unhealthy. Operations are blocked. | Requests are immediately short-circuited (fail-fast, return fallback/error) without calling the service. A timeout duration is active. | Half-Open: After the configured timeout duration (sleep window) has elapsed. |
| Half-Open | A cautious probe state. A limited number of requests are allowed to test the service's recovery. | A small number of "test" requests are sent to the protected service. Other requests may still be short-circuited or queued depending on implementation. | Closed: If the test requests succeed. Open: If any of the test requests fail (restarting the timeout duration). |
This state-driven approach makes the circuit breaker a powerful tool for dynamic resilience, adapting its behavior based on the real-time health of its dependencies.
Mechanics of Operation: How a Circuit Breaker Works in Practice
Understanding the states is one thing; comprehending the practical mechanics of how a circuit breaker operates within a software system is another. Its effectiveness stems from a meticulous approach to metrics collection, intelligent failure detection, and precise configuration.
Metrics Collection: The Eyes and Ears of the Breaker
For a circuit breaker to make informed decisions about the health of a downstream service, it must continuously collect data about the outcomes of calls to that service. This involves tracking various metrics:
- Successes: The number of calls that complete successfully within an acceptable time frame and return a valid response (e.g., HTTP 2xx codes).
- Failures: The number of calls that result in errors (e.g., exceptions, HTTP 5xx codes, network errors).
- Timeouts: Calls that exceed a predefined execution time limit. While a circuit breaker is distinct from a timeout, timeouts often trigger a failure count within the circuit breaker.
- Total Requests: The total number of attempts made, irrespective of outcome.
These metrics are typically stored and analyzed within a sliding window. A sliding window is a time-based or count-based mechanism that only considers the most recent data points. For instance, a circuit breaker might monitor the error rate over the last 10 seconds or the last 100 requests. This ensures that decisions are based on the current health of the service, rather than stale historical data. If a service recovers, old failure counts are gradually "forgotten" as the window slides forward, allowing the breaker to close again more quickly.
Failure Detection Strategies: What Constitutes a "Failure"?
Defining what constitutes a "failure" is crucial for accurate circuit breaker operation. Different types of errors require different handling:
- Exceptions: Any unhandled exception thrown by the protected service or during its invocation (e.g.,
IOException,TimeoutException, custom business exceptions indicating a service-level failure) should increment the failure counter. - Timeouts: If a call to the service takes longer than a predefined timeout duration (configured separately or as part of the circuit breaker's context), it's typically considered a failure. This protects the calling application from waiting indefinitely for a slow service.
- Network Errors: Connection refused, host unreachable, DNS resolution failures – these indicate fundamental communication problems and are clear signals of failure.
- HTTP Status Codes: For HTTP-based services, certain status codes are indicative of failure:
- 5xx codes (Server Error): These are strong signals that the backend service is struggling (e.g., 500 Internal Server Error, 502 Bad Gateway, 503 Service Unavailable, 504 Gateway Timeout). These should almost always trigger a failure count.
- 4xx codes (Client Error): These are generally not treated as failures by the circuit breaker (e.g., 400 Bad Request, 401 Unauthorized, 404 Not Found). A 404 doesn't mean the service is down; it means the requested resource doesn't exist, which is a legitimate response. However, an architect might choose to configure the circuit breaker to consider specific 4xx codes as failures if they indicate a systemic issue (e.g., too many malformed requests overwhelming a service).
- Business Logic Errors: In some cases, a service might return a valid HTTP 200 OK, but the response body indicates a business-level failure (e.g., a specific error code in a JSON payload). The circuit breaker can be configured to inspect the response payload for these conditions.
The choice of which errors to count as failures directly impacts the sensitivity and effectiveness of the circuit breaker.
Configuration Parameters: Tuning for Optimal Performance
The power of a circuit breaker lies in its configurability, allowing it to be finely tuned for specific service dependencies and operational contexts. Key parameters include:
- Failure Rate Threshold: The percentage of failed calls within the sliding window that will trip the circuit breaker (e.g., 50%, meaning half the calls are failing). This is often more robust than a simple consecutive failure count for bursty traffic.
- Minimum Number of Calls: Before the circuit breaker starts evaluating the failure rate, it needs a certain minimum number of calls within the sliding window. This prevents premature tripping due to a single failure when the overall traffic volume is very low. For example, if the threshold is 50% and only one call has been made (which failed), a minimum of 10 calls might be required before the breaker can open.
- Sliding Window Type and Size:
- Count-based: The breaker evaluates the last
Ncalls. - Time-based: The breaker evaluates calls within the last
Tduration (e.g., 10 seconds). - The
sizerefers toNorT.
- Count-based: The breaker evaluates the last
- Wait Duration in Open State (Sleep Window): The time the circuit breaker remains in the
Openstate before transitioning toHalf-Open(e.g., 30 seconds, 1 minute). - Permitted Number of Calls in Half-Open State: How many test requests are allowed to pass when in
Half-Open(e.g., 1, 5). - Event Publishers: Mechanisms to notify other parts of the system or monitoring tools when the circuit breaker changes state (e.g., from Closed to Open, or Open to Half-Open). This is crucial for observability.
Integrating with Existing Codebase: Seamless Adoption
Implementing a circuit breaker often involves wrapping the calls to the protected service. This can be achieved through:
- Direct Instantiation: Manually creating a circuit breaker instance and using its
executeorrunmethod to wrap the service call. - Aspect-Oriented Programming (AOP): Using frameworks that allow cross-cutting concerns like circuit breaking to be applied declaratively (e.g., via annotations) to methods or classes. This is common in Spring Boot applications with libraries like Resilience4j.
- Gateway Configuration: In
api gateways, circuit breakers are often configured externally, applying them to specific routes or services without modifying the backend service code itself.
What Happens to Failed Requests: Fallbacks and Graceful Degradation
A crucial aspect of circuit breaker implementation is defining what happens when a request is short-circuited (either because the breaker is Open or a test request in Half-Open fails). This is where fallback mechanisms come into play:
- Immediate Error: Simply throwing an exception back to the calling code. This is the simplest fallback but may not provide a good user experience.
- Cached Response: Returning a previously known good response from a cache. This is useful for idempotent read operations where stale data is acceptable.
- Default Value: Returning a predefined default value (e.g., an empty list, a default configuration).
- Alternative Service: Rerouting the request to a different, potentially less feature-rich but more reliable, service (a common pattern in
LLM Gateways). - Graceful User Message: Displaying a user-friendly message indicating that a particular feature is temporarily unavailable.
The choice of fallback strategy significantly impacts the perceived resilience and user experience of the application when a dependency fails. The ultimate goal is to provide a degraded but still functional experience, rather than a complete outage.
Benefits of Employing the Circuit Breaker Pattern
The strategic implementation of the circuit breaker pattern yields a multitude of advantages, fundamentally transforming the resilience and reliability of distributed systems. Its benefits extend beyond mere error handling, touching upon system stability, resource management, and even user perception.
1. Enhanced System Resilience: Preventing Cascading Failures
This is arguably the most significant benefit. In a microservices architecture, where services rely on each other, a single failing service can trigger a domino effect. If Service A continually tries to call a failing Service B, Service A's thread pools might become exhausted, its memory might fill up, or its network connections might max out. This makes Service A unresponsive, causing its callers (Service C) to fail, and so on.
A circuit breaker breaks this chain. By "opening" when Service B fails, it prevents Service A from consuming resources on doomed calls. Service A can then continue to operate, perhaps in a degraded mode using fallbacks, while Service B recovers. This isolation of failures is paramount in maintaining overall system stability and preventing minor issues from escalating into widespread outages. It's a fundamental principle of defensive programming in distributed environments.
2. Improved User Experience: Faster Feedback and Graceful Degradation
Without a circuit breaker, users might experience prolonged loading times, application freezes, or complete unresponsiveness when a backend service struggles. They would be left waiting for timeouts to expire or retries to fail, leading to frustration.
With a circuit breaker, if a dependency is unhealthy, the client application receives immediate feedback (e.g., an error or a fallback response). This allows the application to react swiftly: * Immediate Error Message: "Feature temporarily unavailable, please try again later." * Cached Data: Displaying slightly stale information instead of an empty screen. * Alternative UI Flow: Guiding the user to a different part of the application that doesn't rely on the failing service.
This proactive failure handling translates to a more fluid and less jarring user experience. Users perceive a system that gracefully degrades as more reliable and robust than one that simply crashes or hangs.
3. Faster Recovery: Giving Overloaded Services Room to Breathe
When a service is overwhelmed (e.g., by a traffic surge, a resource leak, or a temporary outage), the worst thing that can happen is for its callers to continue bombarding it with requests. This exacerbates the problem, making recovery more difficult and prolonged.
An Open circuit breaker acts as a temporary firewall, shielding the struggling service from further requests. This period of respite allows the service to: * Clear its backlog of requests. * Release exhausted resources (e.g., database connections, thread pools). * Restart or auto-scale if configured to do so. * Undergo manual intervention by operations teams.
By giving the service a chance to recover without constant pressure, the circuit breaker significantly shortens the mean time to recovery (MTTR), bringing the system back to full health much faster.
4. Reduced Resource Consumption: Avoiding Wasted Efforts
Continuously making calls to a failing service is a wasteful endeavor. Each failed request consumes valuable resources on the client side: * Threads: Waiting for a response that will never come or will be an error. * Network Connections: Holding open connections that are unproductive. * Memory/CPU: Processing the failed attempts and associated error handling.
When a circuit breaker is Open, it prevents these wasted efforts. The client application's resources are freed up to handle other operations or to respond to users with fallbacks, ensuring that the system operates efficiently even under duress. This resource optimization is particularly crucial in environments with tight resource constraints or high-volume traffic.
5. Better Observability: Providing Insights into Service Health
Well-implemented circuit breakers emit events and metrics that are invaluable for monitoring and observability: * State Changes: Alerts when a circuit breaker Opens, Closes, or goes Half-Open. These are strong indicators of potential issues with a downstream service. * Failure Counts/Rates: Real-time data on how many calls are failing, which can be visualized in dashboards. * Latency Metrics: Tracking response times before failure thresholds are met.
This data provides engineers and operations teams with early warnings about service degradation, allowing them to investigate and intervene proactively before failures become widespread. It transforms reactive firefighting into proactive problem management, facilitating quicker root cause analysis and resolution.
6. Predictable Behavior: Increased Stability Under Stress
In a complex distributed system, unpredictability is the enemy. Circuit breakers introduce a layer of predictable behavior under stress. When a dependency starts failing, the system doesn't spiral out of control; instead, the circuit breaker ensures a controlled response. This makes the overall system more stable, even when individual components are struggling. Developers can reason about how their application will behave during partial outages, rather than guessing.
In essence, the circuit breaker pattern is an embodiment of graceful failure. It doesn't prevent failures from happening – that's an impossible dream in distributed computing. Instead, it provides a robust, automated mechanism to manage failures, contain their impact, and accelerate recovery, ultimately leading to more resilient, performant, and user-friendly applications.
Circuit Breakers in API Gateways
The api gateway sits at the very frontier of a microservices architecture, serving as the single entry point for all client requests. It's the bouncer, the concierge, and the traffic controller for an entire ecosystem of backend services. Given its pivotal role, an api gateway is not just a natural candidate for circuit breaker implementation, but an absolutely critical one. Without robust resilience mechanisms like circuit breakers, an api gateway can become the single point of failure, turning a localized backend issue into a widespread system outage.
The Role of an API Gateway
Before diving into circuit breakers, let's briefly recap the multifaceted responsibilities of an api gateway:
- Request Routing: Directing incoming client requests to the appropriate backend microservice.
- Authentication and Authorization: Verifying client identity and permissions before forwarding requests.
- Rate Limiting: Protecting backend services from being overwhelmed by too many requests from a single client or overall.
- Load Balancing: Distributing requests across multiple instances of a backend service.
- Monitoring and Logging: Centralizing telemetry data for all API calls.
- Protocol Translation: Converting client-friendly protocols (e.g., HTTP/REST) to internal service protocols (e.g., gRPC).
- API Composition: Aggregating responses from multiple microservices into a single response for the client.
- Security: Implementing features like CORS, WAF, and SSL termination.
Given these responsibilities, it's evident that the api gateway is a choke point, and its stability directly impacts the availability of all downstream services.
Why Circuit Breakers Are Critical Here
The inherent nature of an api gateway makes circuit breakers indispensable:
- Protecting Backend Services from Client-Side Overloads or Misconfigurations: Clients can sometimes be buggy, sending a deluge of requests or malformed queries. While rate limiting helps, a circuit breaker adds another layer. If a specific backend service consistently fails due to client misbehavior or overwhelming traffic from a specific client, the
api gatewaycan trip the circuit for that service, shielding it from further harm. - Isolating Failures: If one microservice in a large ecosystem becomes unhealthy (e.g., a database connection issue, an out-of-memory error), a circuit breaker on the
api gateway's calls to that specific service will immediatelyOpen. This ensures that traffic is blocked only for that failing service, allowing all other healthy services to continue functioning normally. Without it, thegatewaymight exhaust its resources trying to reach the unhealthy service, bringing down the entiregatewayand thus all other services. - Preventing a Single Failing Service from Bringing Down the Entire Gateway: If the
gatewayitself doesn't have a circuit breaker, a dependency that is unresponsive can cause thegateway's internal threads to block, its connection pools to deplete, or its memory to balloon. This can lead to thegatewaycrashing or becoming unresponsive to all requests, even those destined for perfectly healthy backend services. The circuit breaker ensures thegatewayremains operational and responsive, even when some of its dependencies are not. - Graceful Degradation at the Edge: The
api gatewayis the ideal place to implement global fallback strategies. If a particular service is unavailable, thegatewaycan be configured to return a generic "service unavailable" message, serve a cached response, or redirect to a static page, providing immediate feedback to the client rather than a prolonged timeout.
Implementation within a Gateway
Circuit breakers in an api gateway are typically configured on a per-service or per-route basis.
- Per-service Circuit Breakers: Each backend microservice that the
gatewayroutes to can have its own dedicated circuit breaker. This allows for granular control and failure isolation. For instance, theUser Servicemight have different resilience requirements and failure thresholds than theOrder Service. If theUser Servicegoes down, only calls to that service are affected, whileOrder Servicecalls continue unimpeded. - Global Circuit Breakers (less common, more nuanced): In rare cases, a
gatewaymight have a circuit breaker that monitors the overall health of its own interactions with all backend services. If a significant percentage of all backend calls are failing, it might signal a deeper issue within thegatewayitself or a widespread network problem. However, this is less common and often less effective than per-service breakers, as it can lead to unnecessary blocking of healthy services. - Configuration at the Gateway Level: Modern
api gatewaysolutions (whether open-source like Kong, Apache APISIX, or commercial offerings) provide declarative configuration for circuit breakers. This means engineers can define the failure thresholds, timeout durations, and fallback actions directly in thegateway's configuration files (e.g., YAML, JSON), without modifying the backend service code. This centralizes resilience policy and simplifies management.
For example, a gateway might be configured such that: * If UserService returns 5xx errors for 30% of requests within a 10-second window, open the circuit for 60 seconds. * During the open state, return a default JSON payload { "error": "User service temporarily unavailable" }.
It's important to note that the api gateway can also leverage other resilience patterns in conjunction with circuit breakers, such as rate limiting (to prevent overload from the client side), timeouts (for individual request limits), and bulkheads (to isolate resources within the gateway, e.g., separate thread pools for different backend services).
In the realm of robust API management, platforms like ApiPark, an open-source AI gateway and API management platform, inherently understand the profound need for robust resilience mechanisms. While APIPark excels in unifying AI model integration, prompt encapsulation, and comprehensive API lifecycle management, the underlying principles of preventing cascading failures through patterns like circuit breakers are paramount for maintaining the high performance and reliability that APIPark aims to deliver across its gateway functionalities. By offering end-to-end API lifecycle management, traffic forwarding, and load balancing, APIPark implicitly supports a resilient infrastructure where features like performance rivaling Nginx and detailed API call logging become even more valuable when integrated with intelligent failure handling. ApiPark ensures that developers can manage, integrate, and deploy AI and REST services with ease, partly by implicitly or explicitly supporting patterns that protect backend services from overload and failure, thereby enhancing efficiency, security, and the stability needed for its claimed 20,000 TPS performance. The ability of APIPark to integrate 100+ AI models and encapsulate prompts into REST APIs necessitates this kind of resilience to manage the varying reliability of external AI services, ensuring that a single failing AI model does not compromise the entire gateway or the applications built upon it.
Circuit Breakers in LLM Gateways
The emergence of Large Language Models (LLMs) has revolutionized AI applications, but integrating them into production systems comes with a unique set of challenges. An LLM Gateway is a specialized form of api gateway designed to manage, route, and optimize interactions with various LLM providers (e.g., OpenAI, Anthropic, Google Gemini, custom-hosted models). For these LLM Gateways, circuit breakers are not just beneficial; they are rapidly becoming an essential component for stable and cost-effective operation.
The Rise of LLM Gateways
LLM Gateways serve several critical functions:
- Unified API Access: Providing a single, standardized API endpoint for interacting with multiple LLM providers, abstracting away their diverse APIs.
- Routing and Fallback: Intelligently routing requests to the best available LLM based on cost, latency, capability, or current load, and facilitating fallbacks if a primary model is unavailable.
- Rate Limit Management: Managing and enforcing rate limits imposed by LLM providers, and potentially applying custom rate limits for internal users.
- Caching: Caching common LLM responses to reduce latency and cost.
- Cost Management: Tracking token usage and costs across different models and users.
- Prompt Engineering & Versioning: Managing and versioning prompts, and potentially injecting system prompts or guardrails.
- Observability: Centralizing logs, metrics, and tracing for LLM interactions.
Unique Challenges with LLMs
Interacting with LLMs introduces specific complexities that make circuit breakers particularly valuable:
- High Latency Variations: LLM inference can be inherently slow and highly variable, depending on model size, load on the provider's infrastructure, network conditions, and prompt complexity. Calls can sometimes hang or exceed acceptable response times.
- Strict Rate Limits: All major LLM providers enforce strict rate limits (requests per minute, tokens per minute) to prevent abuse and manage their infrastructure load. Exceeding these limits results in errors.
- Token Costs and Budget Control: LLM usage is often billed by tokens. Repeatedly attempting to use a failing or extremely slow model can lead to unnecessary cost accumulation.
- Model-Specific Errors: LLMs can return errors for various reasons beyond standard HTTP issues, such as
input too long,invalid prompt,model overloaded,content moderation policy violation. - Provider Outages/Degradation: LLM providers, despite their sophistication, can experience outages, performance degradation, or maintenance windows, leading to service unavailability.
- Dependency on External Networks: The interaction relies heavily on external internet connectivity, which can be unreliable.
How Circuit Breakers Address LLM Challenges
Circuit breakers are uniquely positioned to mitigate many of these LLM-specific challenges:
- Protecting from Latency Spikes:
- If a particular LLM provider or model becomes excessively slow, the circuit breaker monitoring its calls will detect a high number of timeouts.
- It will
Openthe circuit, preventing further requests from accumulating and hanging. - During the
Openstate, theLLM Gatewaycan immediately return an error, direct the request to a faster, potentially less capable, fallback model, or serve a cached response. This prevents applications from waiting indefinitely and ensures a more responsive user experience.
- Handling Rate Limits Gracefully:
- When an
LLM Gatewayhits an API provider's rate limit, subsequent calls will likely fail with 429 Too Many Requests errors. - A circuit breaker configured to trip on these 429 errors (or a high error rate including 429s) will
Openfor that specific LLM endpoint. - This provides a crucial "cool-down" period, allowing the provider's rate limit window to reset. Instead of continuously receiving 429s, the
gatewaycan queue requests, route to another model, or inform the client to retry later, preventing unnecessary strain on the provider and avoiding persistent errors.
- When an
- Cost Control and Budget Management:
- If a specific LLM model is consistently failing (e.g., returning garbage responses that lead to application-level errors, or timing out repeatedly), a circuit breaker can prevent further costly invocations.
- By
Openingthe circuit, it stops sending requests to that model, thereby preventing the accumulation of token costs for failed or unproductive queries. This directly contributes to efficient budget management for LLM usage.
- Provider Outages/Degradation:
- If an LLM provider experiences a widespread outage or significant degradation, its APIs will likely return a high volume of errors (e.g., 5xx, timeouts).
- A circuit breaker for that provider will quickly
Open, isolating the failing provider. - This allows the
LLM Gatewayto gracefully switch to a secondary provider (if configured), return a predefined error, or utilize cached responses without blocking client applications due to a completely unresponsive dependency.
- Model Versioning and Updates:
- During model updates or deployments by providers, there can be temporary periods of instability, increased latency, or higher error rates.
- A circuit breaker can absorb these transient issues, temporarily routing traffic away or holding it back, allowing the new model version to stabilize without impacting upstream applications.
Specific Implementation Considerations for LLM Gateways
- Granular Circuit Breakers:
LLM Gateways often need very granular circuit breakers. This might mean:- Per-Model: A circuit breaker for
gpt-4, another forclaude-3-opus, another forgemini-pro. - Per-API Key: If using multiple API keys for the same provider, each key might need its own breaker if rate limits are tied to keys.
- Per-Region: If using models across different geographical regions, failures in one region shouldn't affect another.
- Per-Prompt/Endpoint: For highly specific fine-tuned models or complex prompt chains, a circuit breaker might even be applied to a particular endpoint that encapsulates that specific prompt.
- Per-Model: A circuit breaker for
- Integration with Sophisticated Retry and Fallback Strategies: Circuit breakers in
LLM Gateways work hand-in-hand with:- Intelligent Retries: Retrying requests with exponential backoff after a temporary failure, but only if the circuit is
ClosedorHalf-Open. - Model Fallbacks: If a circuit for a premium model
AisOpen, thegatewaymight automatically route the request to a cheaper, slightly less capable modelB(e.g., switching fromgpt-4togpt-3.5-turbo) to maintain service availability. - Response Caching: Serving a cached response for idempotent requests when all LLM providers are unavailable.
- Intelligent Retries: Retrying requests with exponential backoff after a temporary failure, but only if the circuit is
- Contextual Error Handling: Distinguishing between different types of LLM errors. For instance, a
content moderation errormight not trip a circuit breaker if it's a client-side issue, whereas amodel overloadederror definitely should. - Real-time Observability: High-quality dashboards displaying the state of circuit breakers for each LLM provider, current failure rates, and active fallbacks are indispensable for debugging and operational awareness.
In essence, an LLM Gateway without circuit breakers is like driving a car without brakes – highly risky and prone to disastrous outcomes when things inevitably go wrong. By intelligently managing the flow of requests and proactively reacting to performance degradation or outright failures from LLM providers, circuit breakers ensure the LLM Gateway remains a reliable, cost-effective, and resilient intermediary for integrating the power of large language models into applications.
Advanced Considerations and Related Patterns
While the core principles of the circuit breaker pattern are straightforward, its real-world application often involves advanced considerations and synergistic interactions with other resilience patterns. Understanding these nuances is key to building truly robust and adaptive distributed systems.
Monitoring and Alerting: The Watchful Eye
Implementing a circuit breaker without robust monitoring and alerting is like installing a smoke detector without a battery. The circuit breaker's state changes (from Closed to Open, Open to Half-Open, and Half-Open to Closed) are critical signals of system health.
- Metrics Collection: The circuit breaker itself should emit metrics, such as:
- Current state of the breaker (Open, Closed, Half-Open).
- Number of successful calls.
- Number of failed calls.
- Number of short-circuited calls (when
Open). - Latency of calls. These metrics should be integrated into a centralized monitoring system (e.g., Prometheus, Grafana, Datadog) to provide real-time dashboards and historical trends.
- Alerting: Critical alerts should be configured for:
- A circuit breaker transitioning to
Open. This indicates a significant issue with a downstream dependency. - A circuit breaker remaining
Openfor an extended period. This might signal a persistent problem that requires manual intervention. - Frequent
Half-OpentoOpentransitions. This could indicate an unstable service that's struggling to recover. Proactive alerts allow operations teams to quickly identify and address underlying issues before they significantly impact users.
- A circuit breaker transitioning to
Manual Override: Human Intervention when Needed
While circuit breakers are designed for automated resilience, there are scenarios where manual intervention is desirable:
- Forced Open: An operations team might want to manually
Opena circuit breaker if they know a downstream service is undergoing maintenance or experiencing a severe outage that automated detection hasn't yet caught or if they want to prevent any traffic from hitting it. - Forced Closed: After a known issue has been resolved (e.g., a database restart, a new deployment), an operator might want to manually
Closethe circuit breaker to bypass theHalf-Openstate and immediately restore full traffic, especially if theHalf-Openprobing mechanism is too slow or conservative. This capability provides an essential safety valve and allows for quicker recovery in specific operational contexts, though it should be used judiciously and with proper authorization.
Combining with Other Resilience Patterns: A Symphony of Defense
Circuit breakers are most effective when integrated into a broader strategy of resilience patterns. They complement, rather than replace, other techniques:
- Retry Pattern:
- Relationship: Retries attempt to re-execute a failed operation, assuming it was a transient error. Circuit breakers prevent retries to a persistently failing service.
- Synergy: A circuit breaker should wrap the retry logic. If the circuit is
Open, no retries should even be attempted. If the circuit isClosedand a call fails, the retry mechanism can kick in for a few attempts. If those retries consistently fail, then the circuit breaker's failure threshold is met, and itOpens. This ensures that retries don't contribute to overloading an already struggling service.
- Bulkhead Pattern:
- Relationship: The bulkhead pattern isolates resources (e.g., thread pools, connection pools) for different service dependencies, preventing one failing dependency from consuming all resources.
- Synergy: A circuit breaker protects a specific service within its own bulkhead. Even if the circuit for Service A
Opens, the bulkhead for Service B (and its own circuit breaker) remains unaffected, ensuring resources are isolated and failures contained. This prevents Service A's issues from depleting shared resources.
- Timeout Pattern:
- Relationship: Timeouts define how long a client will wait for a response before giving up.
- Synergy: Timeouts are a critical input to the circuit breaker. If a call exceeds its timeout, it's typically counted as a failure, contributing to the circuit breaker's failure threshold. Timeouts prevent the client from hanging indefinitely, while the circuit breaker ensures that repeated timeouts don't repeatedly hammer a slow service.
- Rate Limiting:
- Relationship: Rate limiting typically occurs at the
api gatewayor service boundary to control the number of requests a client can make within a given period, preventing overload from the client side. - Synergy: Circuit breakers protect against failures from the backend service. Rate limiting prevents overload going into the backend service. They are complementary: rate limiting reduces the chance of the service becoming overloaded and thus tripping its circuit breaker, while the circuit breaker handles cases where the service fails despite rate limits (e.g., an internal bug or external dependency failure).
- Relationship: Rate limiting typically occurs at the
Idempotency: Essential for Retries
When combining circuit breakers with retries or fallbacks that might involve re-sending requests, idempotency is crucial. An idempotent operation is one that can be executed multiple times without changing the result beyond the initial execution. For example, setting a value is often idempotent, while incrementing a value is not. If a circuit breaker Opens after a request was sent but before a response was received (leaving the state of the operation ambiguous), and the client then retries the operation, it's essential that this retry doesn't cause unintended side effects (e.g., double charging a customer, creating duplicate records). Designing APIs to be idempotent greatly simplifies resilience strategies.
Choosing the Right Library/Framework: The Toolset
Many libraries and frameworks provide robust implementations of the circuit breaker pattern, simplifying its adoption:
- Hystrix (Netflix): While no longer actively developed, Hystrix was hugely influential in popularizing the circuit breaker pattern in microservices. It introduced concepts like thread isolation (a form of bulkhead), fallback mechanisms, and sophisticated metrics. Many current libraries draw inspiration from Hystrix.
- Resilience4j (Java): A lightweight, highly performant, and modular resilience library that implements circuit breakers, retries, rate limiters, bulkheads, and timeouts. It's a popular choice for Spring Boot applications.
- Polly (.NET): A comprehensive resilience and transient-fault-handling library for .NET, offering circuit breakers, retries, timeouts, and more.
- Sentinel (Alibaba): A robust flow control, concurrency control, and circuit breaking library for microservices, particularly popular in the Java ecosystem.
- Istio/Envoy (Service Mesh): In a service mesh architecture, circuit breaking can often be configured and enforced at the proxy level (e.g., Envoy proxies in Istio), abstracting it away from application code entirely. This is powerful for large-scale, polyglot microservice environments.
The choice of library depends on the technology stack, specific requirements, and the level of integration desired (application-level vs. infrastructure-level).
Distributed Circuit Breakers: Challenges and Solutions
In truly large-scale distributed systems, the concept of a "distributed circuit breaker" sometimes arises, though it's more complex. A standard circuit breaker operates locally within a single client instance. If 10 instances of Service A call Service B, each instance of Service A has its own circuit breaker for Service B.
Challenges of Distributed Circuit Breakers:
- Shared State: Requiring all instances of a client service to share a common view of a dependency's health. This needs a distributed consensus mechanism or a shared data store.
- Latency: Propagating state changes across many instances introduces latency.
- Single Point of Failure: If the centralized state store fails, all circuit breakers might become inoperable.
- False Positives/Negatives: A transient network glitch affecting only one client instance could erroneously trip a global breaker for all instances.
Solutions/Approaches:
- Aggregated Metrics: Instead of a single "distributed circuit breaker," a common approach is to aggregate metrics (e.g., error rates) from all client instances in a central monitoring system. This allows for system-wide alerts, but the actual circuit breaking decisions are still made locally by each client's individual circuit breaker.
- External Control Plane: In service meshes, an external control plane might instruct proxies to
Opena circuit for a service across all instances based on aggregated health signals. - Smart Gateways: An
api gatewayorLLM Gatewayacts as a natural aggregation point, where a single circuit breaker protects all upstream clients from a downstream dependency. This often provides sufficient "distribution" for practical purposes.
Generally, sticking to local circuit breakers and robust monitoring is the simpler and more effective approach for most scenarios, while leveraging gateways for broader cross-cutting concerns.
The sophisticated interplay of circuit breakers with monitoring, related resilience patterns, and careful library selection is what transforms a basic error-handling mechanism into a cornerstone of enterprise-grade system resilience.
Challenges and Best Practices
While the circuit breaker pattern is immensely powerful, its effective implementation is not without challenges. Misconfigurations or a lack of understanding can lead to unintended consequences, potentially making a system less, rather than more, resilient. Adhering to best practices is essential for harnessing its full potential.
1. Over-configuration vs. Under-configuration: Finding the Sweet Spot
- Challenge: The myriad of configuration parameters (failure thresholds, window sizes, timeout durations, permitted calls in
Half-Open) can be overwhelming.- Over-configuration: Too many sensitive parameters, or parameters set too aggressively, can lead to "flapping" circuit breakers (constantly
OpeningandClosing) or breakers tripping for minor, transient issues, unnecessarily degrading service. - Under-configuration: Parameters set too loosely might mean the circuit breaker never trips, rendering it useless. Alternatively, default settings might not be optimal for specific service characteristics.
- Over-configuration: Too many sensitive parameters, or parameters set too aggressively, can lead to "flapping" circuit breakers (constantly
- Best Practice:
- Start with sensible defaults: Most libraries provide good starting points.
- Know your dependencies: Understand the typical latency, error rates, and failure modes of the services your circuit breaker protects.
- Iterative Tuning: Adjust parameters based on real-world monitoring data and observation. Don't set and forget.
- Use a percentage-based threshold: Often more robust than consecutive failure counts, especially under varying load. A threshold like "50% error rate over the last 100 requests" is generally more reliable than "5 consecutive failures."
- Ensure sufficient minimum calls: Don't let a single failure trip a breaker if only a few calls have been made in the window.
2. False Positives/Negatives: The Tuning Dilemma
- Challenge:
- False Positive: The circuit breaker
Openswhen the service is actually healthy (e.g., due to a temporary network glitch that affected only a few requests, but the threshold was too low). This unnecessarily degrades user experience. - False Negative: The circuit breaker fails to
Openwhen the service is genuinely unhealthy, allowing continued hammering of a failing dependency.
- False Positive: The circuit breaker
- Best Practice:
- Careful definition of "failure": Only count true service-impacting errors (e.g., 5xx HTTP codes, connection errors, explicit business failures). Exclude expected client-side errors (e.g., 400 Bad Request) from tripping the breaker.
- Observability is key: Monitor failure rates before the circuit breaker takes action. If a service is showing high error rates but the breaker isn't tripping, it's under-configured. If it's tripping too often for seemingly healthy services, it's over-configured.
- Leverage different metrics: Combine timeout counts with exception counts.
3. Testing Circuit Breakers: Simulating Chaos
- Challenge: It's often difficult to properly test circuit breaker behavior in development or staging environments. Simply throwing an exception might not fully simulate a network partition or a slow, resource-exhausted service.
- Best Practice:
- Chaos Engineering: Employ tools and practices from chaos engineering (e.g., injecting latency, introducing network black holes, intentionally crashing services) to realistically test how circuit breakers react under various failure conditions.
- Mock Services: Use mock services or testing frameworks that can simulate specific error codes, timeouts, or unresponsiveness to verify breaker behavior.
- Integration Tests: Write integration tests that assert the circuit breaker's state transitions and fallback mechanisms under simulated failure scenarios.
- Monitor during Load Tests: Observe circuit breaker behavior during performance and load testing to see how it performs under stress.
4. Observability: Making the Invisible Visible
- Challenge: Without clear visibility, circuit breakers can operate silently, making it difficult to diagnose problems or understand system behavior during incidents.
- Best Practice:
- Emit Metrics: Ensure the circuit breaker library emits metrics for all its states, success/failure counts, and event transitions.
- Create Dashboards: Visualize circuit breaker metrics (e.g., current state, failure rate, time since last open) in your monitoring dashboards (e.g., Grafana, Kibana).
- Configure Alerts: Set up alerts for state changes (especially
Opentransitions) to get immediate notification of dependency issues. - Logging: Log important events, such as when a circuit breaker
OpensorCloses, including the reason.
5. Impact on Development and Operations: Collaboration is Key
- Challenge: Introducing circuit breakers requires developers to think about failure scenarios, and operations teams to understand how to monitor and manage them. A lack of collaboration can lead to misconfigurations or inadequate response to alerts.
- Best Practice:
- Developer Education: Educate developers on the pattern, its purpose, and how to integrate it correctly, including designing fallbacks.
- Operational Runbooks: Create clear runbooks for operations teams on what to do when a circuit breaker
Opens(e.g., check the downstream service, escalate, consider manual override). - Shared Responsibility: Foster a DevOps culture where both development and operations teams are responsible for the resilience of the system, including circuit breaker configuration and monitoring.
6. Start Simple, Iterate: Avoid Over-engineering
- Challenge: The temptation to over-engineer resilience from the start can lead to unnecessary complexity.
- Best Practice:
- Apply where needed most: Focus on critical dependencies that are known to be volatile or are crucial for core business functions. Not every single external call needs a circuit breaker initially.
- Gradual Adoption: Introduce circuit breakers iteratively, starting with sensible defaults and then tuning based on observed behavior in production.
- Simplicity over Complexity: If a simpler solution (like a basic timeout with retries for truly transient errors) suffices, don't immediately jump to a full circuit breaker implementation.
By thoughtfully addressing these challenges and adhering to these best practices, organizations can effectively leverage the circuit breaker pattern to build highly resilient, self-healing distributed systems that gracefully navigate the inevitable complexities and failures of the modern technological landscape.
Conclusion
In the demanding ecosystem of modern distributed systems, where applications are composed of myriad interconnected services, the likelihood of a single component failing is not a matter of if, but when. The Circuit Breaker Pattern stands as a cornerstone of resilience engineering, offering a sophisticated yet intuitive mechanism to confront this reality head-on. It acts as an intelligent sentinel, preventing localized service degradation from spiraling into catastrophic system-wide outages.
We have traversed the journey from its electrical origins to its nuanced implementation in software, exploring its three fundamental states—Closed, Open, and Half-Open—and the critical transitions that govern its behavior. We've dissected the practical mechanics of its operation, from meticulous metrics collection and diverse failure detection strategies to the fine art of configuration and the indispensable role of fallbacks in ensuring graceful degradation.
The benefits of adopting this pattern are profound: enhanced system resilience, preventing cascading failures that can cripple an entire architecture; improved user experience through faster feedback and controlled responses; expedited recovery for struggling services by providing a necessary respite; optimized resource consumption by avoiding futile attempts to reach unhealthy dependencies; and unparalleled observability, offering critical insights into service health.
Furthermore, we underscored its paramount importance in api gateways, where it serves as the frontline defender, safeguarding backend microservices from external pressures and internal frailties. In the burgeoning domain of LLM Gateways, the circuit breaker pattern proves even more indispensable, adeptly navigating the unique complexities of large language models, including their notorious latency variations, stringent rate limits, and the critical need for cost control. Platforms like ApiPark, designed for robust AI gateway and API management, inherently leverage such principles to ensure the seamless integration and high performance of their diverse AI and REST services.
However, the journey of resilience doesn't end with mere implementation. It demands continuous monitoring, careful tuning, rigorous testing, and a collaborative spirit between development and operations teams. By embracing these best practices, we move beyond simply reacting to failures and instead design systems that are inherently prepared for them, systems that are not only robust but also self-healing and predictable.
In a world increasingly reliant on complex, interconnected digital infrastructure, the circuit breaker pattern is more than just a design choice; it is a fundamental imperative, empowering engineers to build a more stable, reliable, and user-friendly digital future. It is a testament to the fact that understanding how to fail gracefully is, ultimately, the most robust path to success.
5 FAQs
1. What is the primary purpose of the Circuit Breaker Pattern in software? The primary purpose of the Circuit Breaker Pattern is to prevent an application from repeatedly attempting to execute an operation that is likely to fail, especially when interacting with a remote service or dependency. It aims to protect both the client application from wasting resources on failed attempts and the struggling backend service from being overwhelmed by continuous requests. By "tripping" (opening the circuit) when failures exceed a threshold, it introduces a "fast-fail" mechanism, improving system resilience and user experience by preventing cascading failures and enabling graceful degradation.
2. How does a Circuit Breaker differ from a simple Timeout or Retry mechanism? While related, a circuit breaker is distinct. A Timeout simply sets an upper limit on how long a client will wait for a response; if exceeded, the call fails. A Retry mechanism attempts to re-execute a failed operation a few times, assuming the failure was transient. The Circuit Breaker Pattern, however, monitors for persistent patterns of failures. If a service consistently fails (even if individual calls eventually timeout or pass after a retry), the circuit breaker will Open, actively preventing all subsequent calls for a period. It effectively wraps and enhances timeouts and retries, deciding when it's unproductive to even try calling a service, whereas timeouts and retries are about handling individual transient errors.
3. What are the three main states of a Circuit Breaker and what do they mean? The three main states are: * Closed: The default state, where requests are allowed to pass through, and the circuit breaker monitors for failures. * Open: Entered when failures exceed a predefined threshold. All requests are immediately short-circuited (fail-fast), without attempting to call the underlying service, for a set timeout duration. * Half-Open: Entered after the Open state's timeout expires. A limited number of "test" requests are allowed to pass through to check if the service has recovered. If these tests succeed, it transitions back to Closed; if they fail, it returns to Open.
4. Why are Circuit Breakers particularly important for API Gateways and LLM Gateways? For API Gateways, circuit breakers are crucial because the gateway is the central entry point for many microservices. If one backend service fails, a circuit breaker prevents the gateway from exhausting its resources on that service, thus isolating the failure and preventing it from bringing down the entire gateway and all other services. For LLM Gateways, they are vital due to unique challenges like high latency variations, strict rate limits from LLM providers, and token costs. Circuit breakers can prevent applications from waiting indefinitely for slow LLMs, gracefully handle rate limit errors, avoid unnecessary costs for failing models, and provide robust fallbacks during provider outages.
5. What happens when a Circuit Breaker is in the "Open" state and a new request comes in? When a circuit breaker is in the Open state, it immediately "short-circuits" the incoming request without attempting to call the protected service. Instead, it will instantly perform a predefined fallback action. This could involve: * Throwing a CircuitBreakerOpenException to the calling code. * Returning a cached response (if available and acceptable). * Returning a default value or an empty dataset. * Executing an alternative fallback method or routing to a different, more stable service (common in LLM Gateways for model failover). This fast-fail mechanism is critical for conserving resources and providing immediate feedback to the client application.
🚀You can securely and efficiently call the OpenAI API on APIPark in just two steps:
Step 1: Deploy the APIPark AI gateway in 5 minutes.
APIPark is developed based on Golang, offering strong product performance and low development and maintenance costs. You can deploy APIPark with a single command line.
curl -sSO https://download.apipark.com/install/quick-start.sh; bash quick-start.sh

In my experience, you can see the successful deployment interface within 5 to 10 minutes. Then, you can log in to APIPark using your account.

Step 2: Call the OpenAI API.