How to Build Microservices Input Bots: A Developer's Guide



The digital landscape is relentlessly evolving, pushing the boundaries of what automated systems can achieve. In this era of rapid technological advancement, intelligent input bots have emerged as critical components for enhancing user experience, streamlining operations, and automating complex workflows. From sophisticated chatbots handling customer inquiries to advanced systems parsing unstructured data and orchestrating intelligent actions, these bots are fundamentally reshaping how businesses interact with information and users. Building such systems, however, presents unique challenges, particularly when aiming for scalability, resilience, and maintainability. This is where the microservices architecture truly shines, offering an agile and robust foundation for developing these intricate intelligent agents.
This comprehensive guide is designed for developers keen on mastering the art and science of constructing microservices input bots. We will embark on a deep dive into the architectural principles, cutting-edge technologies, and practical strategies required to build bots that are not only intelligent but also highly performant, scalable, and adaptable. We will explore everything from decomposing complex functionalities into manageable services and integrating powerful Artificial Intelligence models, especially Large Language Models (LLMs), to deploying and managing these distributed systems in production environments. By the end of this journey, you will possess a profound understanding of how to architect, develop, and operate your own sophisticated microservices input bots, ready to tackle the demands of the modern digital world.
1. Understanding Microservices Input Bots
At its core, a microservices input bot is an automated system designed to receive, interpret, process, and respond to various forms of input, often leveraging advanced AI capabilities. Unlike traditional monolithic applications where all functionalities are tightly coupled, microservices input bots are built as a collection of small, independent services, each responsible for a specific business capability. This architectural paradigm brings immense advantages, particularly for systems that need to be highly responsive, scalable, and continuously evolving.
1.1 What Are Microservices Input Bots?
Imagine a system that can understand natural language queries, parse complex documents, extract key information, or even control other software applications based on user commands. These are the realms where microservices input bots thrive. Examples include:
- Customer Service Chatbots: Capable of understanding user intent, providing information, and even performing transactions through conversational interfaces.
- Voice Assistants: Processing spoken language to execute commands, play music, or control smart home devices.
- Automated Data Entry Systems: Extracting structured data from unstructured documents like invoices or contracts, and feeding it into enterprise resource planning (ERP) systems.
- Intelligent Forms: Guiding users through complex forms by providing context-aware suggestions and validations.
- Workflow Automation Bots: Triggering a sequence of actions across multiple systems based on a specific input or event.
The "input" aspect is crucial here. These bots are engineered to be the first point of contact or data ingestion for specific processes. They transform raw, often ambiguous, user input or external data into actionable insights or commands, serving as intelligent interfaces between humans or external systems and underlying business logic.
1.2 The Inherent Benefits of Microservices for Bots
Adopting a microservices architecture for input bots offers a compelling set of advantages that are difficult to achieve with monolithic designs:
- Scalability: Individual services can be scaled independently based on their specific load requirements. For instance, an NLP service that experiences high traffic can be scaled out without affecting a less-utilized payment processing service, leading to more efficient resource allocation and cost savings. This fine-grained control is vital for bots that might experience unpredictable spikes in input volume.
- Resilience: The failure of one service does not necessarily bring down the entire bot. If the service responsible for generating product recommendations encounters an issue, the bot can still process other types of queries, such as order status checks, albeit with reduced functionality. This isolation enhances the overall fault tolerance of the system.
- Independent Deployment: Each microservice can be developed, tested, and deployed independently. This accelerates the development cycle, allowing teams to iterate faster and deploy new features or bug fixes without redeploying the entire application, which is particularly beneficial in fast-paced AI development environments where models are frequently updated.
- Technology Diversity: Developers can choose the best technology stack (programming language, database, framework) for each service based on its specific needs. A performance-critical NLP service might be written in Python with specialized libraries, while a transaction-heavy order management service might use Java with Spring Boot and a relational database, optimizing each component for its unique requirements.
- Maintainability and Understandability: Smaller codebases are easier to understand, maintain, and debug. This reduces cognitive load on developers and simplifies onboarding for new team members, fostering a more productive development environment.
- Team Autonomy: Cross-functional teams can own specific services from development through deployment and operation, fostering greater accountability and agility. This "you build it, you run it" philosophy promotes a deeper understanding of the service's lifecycle and operational impact.
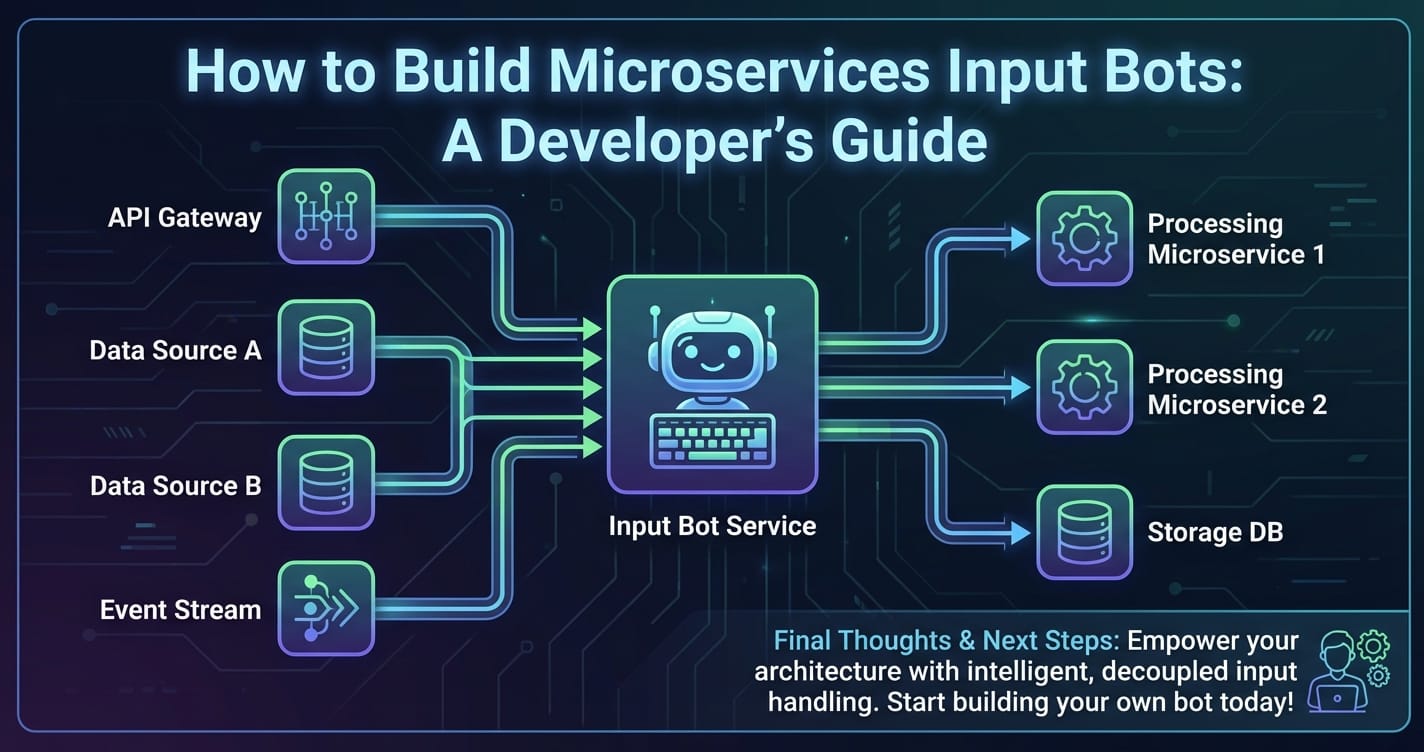
1.3 Core Components of a Microservices Input Bot
Regardless of their specific function, most microservices input bots share a common set of logical components, each typically encapsulated within one or more microservices:
- Input Processing Service: This is the initial entry point, responsible for receiving raw input from various channels (webhooks, APIs, message queues, voice stream, text input fields). It handles format conversion, basic validation, and initial routing.
- Natural Language Processing (NLP) / Natural Language Understanding (NLU) Service: If the bot deals with human language, this service is paramount. It parses the input text, identifies user intent (e.g., "check order status," "find product information"), extracts entities (e.g., "order number 123," "product X"), and performs sentiment analysis. This often involves integrating with powerful AI models, including Large Language Models.
- Business Logic Service: This service orchestrates the core functionality of the bot based on the interpreted input. It determines the appropriate action to take, potentially by calling other internal microservices or external APIs. This could involve querying databases, initiating workflows, or interacting with third-party systems.
- Data Integration/Persistence Service: Handles interactions with databases or external data sources to retrieve or store information relevant to the bot's operations. This could be user profiles, order histories, product catalogs, or conversational context.
- Output Generation Service: Formulates the bot's response or action in a format suitable for the output channel. This might involve generating natural language responses, structured data, or triggering specific system commands.
- Channel Integration Service: Manages the communication with various front-end channels where the bot interacts with users (e.g., Slack, Microsoft Teams, a custom web UI, voice platforms). It ensures messages are formatted correctly for each platform.
By dissecting the bot's functionality into these distinct, independently deployable services, developers can build highly sophisticated and adaptable input systems that are robust enough to meet the dynamic demands of modern applications.
2. Architectural Foundations for Microservices Input Bots
Laying a solid architectural foundation is paramount when constructing microservices input bots. It dictates how services communicate, manage data, and collectively deliver value. A well-designed architecture ensures scalability, resilience, and maintainability, which are critical for any complex distributed system.
2.1 Decomposition Strategy: Breaking Down the Monolith
The first step in microservices architecture is to identify and isolate distinct business capabilities into independent services. This decomposition is an art, not a science, and often involves domain-driven design principles. For an input bot, services might be organized around:
- Authentication and Authorization Service: Handles user login, session management, and verifies permissions for specific actions. This is a common cross-cutting concern that benefits from being a separate service.
- User Profile Service: Stores and manages user-specific data, preferences, and interaction history, allowing for personalized bot experiences.
- Input Channel Service: Specific services for each input channel (e.g.,
SlackGatewayService,VoiceInputService,WebAppInputService), responsible for translating platform-specific messages into a unified internal format. - NLP/NLU Service: Dedicated to processing natural language, as discussed earlier. This might be further broken down into
IntentRecognitionService,EntityExtractionService,SentimentAnalysisService. - Business Orchestration Service: Acts as a coordinator, taking processed input, determining the overall workflow, and invoking other specialized business services. For example, a
CustomerSupportOrchestratorservice. - Domain-Specific Services: These are the core business logic units, such as
OrderManagementService,ProductCatalogService,InventoryService,PaymentService,RecommendationService. Each manages its own data and business rules. - Output Generation Service: Formulates responses or actions, potentially using templates or generative AI, and sends them back through the appropriate channel via the Input Channel Service (reversing the flow).
- Logging and Monitoring Service: Gathers operational data from all other services, crucial for debugging, performance analysis, and security auditing.
The key is to ensure that each service is cohesive, loosely coupled, and has a single responsibility, minimizing dependencies between them.
2.2 Communication Patterns: The Lifeblood of Microservices
Microservices communicate with each other to perform complex tasks. Choosing the right communication pattern is crucial for performance, reliability, and ease of development.
- Synchronous Communication (Request/Response):
- REST (Representational State Transfer): The most common pattern, using HTTP/HTTPS. Services expose RESTful APIs, and clients make requests and wait for responses. It's simple to implement and widely understood. Best for direct queries where an immediate response is required (e.g., "get order details").
- gRPC (Google Remote Procedure Call): A high-performance, open-source framework that uses Protocol Buffers for efficient serialization and HTTP/2 for transport. It supports various communication patterns including unary (single request/response), server streaming, client streaming, and bi-directional streaming. Ideal for internal service-to-service communication where low latency and high throughput are critical.
- Asynchronous Communication (Event-Driven):
- Message Queues (e.g., Kafka, RabbitMQ, SQS): Services communicate by sending and receiving messages via a message broker. A sender publishes a message to a queue/topic, and one or more receivers consume it. This decouples services, enhances resilience (messages are persistent), and enables event-driven architectures. Excellent for long-running processes, notifications, and ensuring reliable delivery even if a service is temporarily unavailable (e.g., "process new order," "update user profile").
Often, a hybrid approach is best, using synchronous communication for direct queries and asynchronous messaging for event-driven workflows and background tasks.
2.3 Data Management: Navigating Distributed Data
One of the most significant challenges in microservices is managing data. Each service should ideally own its data store (database per service pattern) to maintain autonomy and avoid tight coupling.
- Database Per Service: Each microservice has its own private database. This allows services to choose the database technology best suited for their needs (e.g., a graph database for recommendations, a document database for user profiles, a relational database for transactional data). This independence ensures that changes to one service's schema don't impact others.
- Distributed Transactions vs. Eventual Consistency:
- Distributed Transactions (Two-Phase Commit): Generally avoided in microservices due to complexity, performance overhead, and reduced availability.
- Eventual Consistency with Sagas: The preferred approach. A saga is a sequence of local transactions, where each transaction updates data within a single service and publishes an event. Other services react to these events to perform their own local transactions. If a step fails, compensating transactions are executed to undo previous changes. This pattern ensures data consistency across services over time, favoring availability and partition tolerance.
2.4 Service Discovery & Registry: Finding Your Way
In a microservices architecture, services are dynamically provisioned, scaled, and de-provisioned. Their network locations change frequently. Service discovery is the mechanism by which services locate each other.
- Service Registry: A database that stores the network locations of service instances. Services register themselves upon startup and de-register upon shutdown. Examples include Eureka, Consul, Apache ZooKeeper.
- Service Discovery Mechanisms:
- Client-Side Discovery: The client queries the service registry to get the network locations of available service instances and then load balances requests across them.
- Server-Side Discovery: The client makes requests to a router (like an API Gateway or a load balancer), which queries the service registry and forwards the request to an available service instance.
Service discovery is vital for ensuring that services can reliably find and communicate with their peers without manual configuration.
2.5 API Gateway: The Front Door to Your Microservices
The API Gateway is an absolutely critical component in a microservices architecture, especially for input bots. It acts as a single, unified entry point for all client requests, abstracting away the complexity of the underlying microservices. Rather than clients making requests directly to individual services, they communicate with the API Gateway, which then routes the requests to the appropriate backend services.
2.5.1 Key Functions of an API Gateway:
- Request Routing: It maps incoming requests to the correct internal microservice based on predefined rules (e.g., URL path, HTTP method). For an input bot, this means routing specific bot commands or data ingestion requests to the appropriate NLP, business logic, or data integration services.
- Authentication and Authorization: The API Gateway centralizes security concerns. It can authenticate users, validate tokens (e.g., JWTs), and enforce authorization policies before requests even reach the backend services. This offloads security logic from individual services, simplifying their development.
- Rate Limiting: Prevents abuse and ensures fair usage by limiting the number of requests a client can make within a given time frame. This is crucial for protecting your bot's backend services from being overwhelmed.
- Request/Response Transformation: It can modify requests before forwarding them to a service or modify responses before sending them back to the client. This might involve translating data formats, adding headers, or aggregating data from multiple services into a single response.
- Logging and Monitoring: The API Gateway serves as an ideal point to collect logs and metrics for all incoming traffic, providing a comprehensive view of how clients are interacting with your bot and the performance of your microservices.
- Load Balancing: When multiple instances of a service are running, the API Gateway can distribute requests among them to ensure optimal resource utilization and prevent any single instance from becoming a bottleneck.
- Caching: It can cache responses to frequently requested data, reducing the load on backend services and improving response times for clients.
- Cross-Origin Resource Sharing (CORS) Management: Handles CORS policies, enabling web applications from different domains to safely interact with your bot's APIs.
For an input bot, the API Gateway is not just a convenience; it's a necessity. It simplifies client applications by providing a consistent interface, enhances security by centralizing access control, and improves the overall resilience and manageability of the microservices ecosystem. Without it, clients would need to know the specific endpoints of dozens of individual services, manage authentication for each, and deal with varying response formats – a logistical nightmare.
2.6 Observability: Seeing Inside the Black Box
In a distributed microservices environment, understanding what's happening within your system is challenging. Observability is the ability to infer the internal states of a system by examining its external outputs.
- Logging: Every service should emit detailed, structured logs (e.g., JSON format) for every significant event, request, and error. These logs should include correlation IDs to trace a request across multiple services. Centralized logging systems (e.g., ELK stack: Elasticsearch, Logstash, Kibana; or Splunk, Grafana Loki) are essential for aggregating, searching, and analyzing logs.
- Monitoring: Collecting metrics (e.g., request rates, error rates, latency, CPU utilization, memory usage) from all services. Tools like Prometheus, Grafana, Datadog, or New Relic help visualize these metrics, set up alerts, and identify performance bottlenecks.
- Distributed Tracing: Following the path of a single request as it traverses multiple services. Tools like Jaeger or Zipkin assign a unique trace ID to each request, allowing developers to see the latency and errors at each hop, which is invaluable for debugging complex distributed interactions.
Establishing robust observability practices from the outset is non-negotiable for successfully operating microservices input bots in production.
3. Integrating Intelligence: The Role of LLMs and NLP
The "intelligence" in an input bot primarily stems from its ability to understand and generate human-like language, and to make context-aware decisions. This capability is powered by Natural Language Processing (NLP) and, increasingly, by Large Language Models (LLMs).
3.1 Natural Language Processing (NLP) Fundamentals
NLP is a field of artificial intelligence that enables computers to understand, interpret, and generate human language. For an input bot, foundational NLP techniques are crucial for making sense of user queries:
- Tokenization: Breaking down text into individual words or sub-word units (tokens).
- Stemming and Lemmatization: Reducing words to their base or root form (e.g., "running," "runs," "ran" -> "run") to normalize text.
- Part-of-Speech Tagging: Identifying the grammatical role of each word (noun, verb, adjective, etc.).
- Named Entity Recognition (NER): Identifying and classifying named entities in text into predefined categories (e.g., persons, organizations, locations, dates, product names). This is vital for extracting actionable information like "order number" or "product type."
- Sentiment Analysis: Determining the emotional tone of the input (positive, negative, neutral), which can influence the bot's response or escalation strategy.
- Intent Recognition: The most critical NLP task for a conversational bot, where the system identifies the user's goal or purpose behind their query (e.g., "check balance," "reset password," "place order").
Traditional NLP models often require significant training data and feature engineering. While still relevant for specific, well-defined tasks, the advent of LLMs has dramatically simplified and enhanced many of these capabilities.
3.2 Leveraging Large Language Models (LLMs)
Large Language Models (LLMs) are deep learning models trained on massive datasets of text and code, enabling them to understand, generate, and process human language with remarkable fluency and coherence. For microservices input bots, LLMs represent a paradigm shift, offering unprecedented capabilities:
- Enhanced Understanding and Context: LLMs can grasp nuanced meanings, disambiguate ambiguities, and maintain conversational context over extended interactions, far exceeding the capabilities of traditional rule-based or simpler NLP models.
- Complex Intent and Entity Extraction: With proper prompting, LLMs can identify complex intents and extract a wide range of entities without explicit training on every possible permutation. They can infer user intent even from vaguely phrased queries.
- Generative Responses: Instead of relying on pre-scripted answers, LLMs can generate dynamic, contextually relevant, and human-like responses, making bot interactions more natural and engaging. This is particularly powerful for handling unforeseen questions or providing detailed explanations.
- Summarization and Information Retrieval: LLMs can quickly summarize long documents or conversations, extract key information, and answer questions based on retrieved content, which is invaluable for bots that need to process large volumes of data.
- Code Generation and Transformation: Some LLMs can even generate code snippets or transform data formats, opening doors for bots that automate developer tasks or data engineering workflows.
3.2.1 Challenges with LLM Integration:
Despite their power, integrating LLMs into microservices input bots comes with its own set of challenges:
- Cost: LLM API calls can be expensive, especially for high-volume applications or complex prompts.
- Latency: API calls to remote LLMs introduce latency, which can impact the real-time responsiveness of a bot.
- Prompt Engineering: Crafting effective prompts to guide the LLM to desired outputs is a skill in itself. Prompts need to be carefully designed to elicit accurate, relevant, and safe responses.
- Model Management: Different LLMs have varying strengths, weaknesses, and pricing models. Managing multiple models from various providers can be complex.
- Security and Data Privacy: Sending sensitive user data to third-party LLM providers raises concerns about data privacy and intellectual property.
- Vendor Lock-in: Relying heavily on a single LLM provider can lead to vendor lock-in.
3.3 LLM Gateway: Abstracting AI Complexity
To address the challenges associated with integrating and managing LLMs in a microservices environment, an LLM Gateway becomes an indispensable component. Just as an API Gateway centralizes access to backend microservices, an LLM Gateway centralizes and manages access to various LLM providers and AI models. It acts as an abstraction layer, simplifying the consumption of AI capabilities for your microservices.
3.3.1 Key Features of an LLM Gateway:
- Provider Abstraction: The LLM Gateway hides the specifics of different LLM providers (e.g., OpenAI, Google, Anthropic). Your microservices interact with a single, unified API, and the gateway translates those requests into the specific format required by the chosen backend LLM. This allows you to switch LLM providers or models without modifying your core business logic services.
- Centralized Authentication and Key Management: Manages API keys and credentials for all LLM providers, ensuring secure access and rotating keys as needed. This prevents individual microservices from holding sensitive API keys.
- Rate Limiting and Quota Management: Enforces limits on LLM API calls to prevent exceeding quotas, manage costs, and protect against abuse. It can prioritize requests or queue them during peak times.
- Caching: Caches responses for identical or similar LLM requests, significantly reducing latency and cost for frequently asked questions or common queries.
- Intelligent Routing: Can route requests to different LLMs based on criteria such as cost, performance, availability, specific model capabilities (e.g., routing code generation requests to Code Llama, text summarization to GPT-4), or even a fallback mechanism if a primary model is unavailable.
- Prompt Versioning and Management: Allows developers to store, version, and A/B test different prompts, ensuring that prompt engineering efforts are managed systematically and that the best-performing prompts are used.
- Cost Tracking and Optimization: Provides detailed insights into LLM usage and costs across different models and services, enabling better budget management and optimization strategies.
- Input/Output Transformation: Can preprocess prompts before sending them to an LLM (e.g., sanitizing data, adding context) and post-process responses before sending them back to the calling service (e.g., parsing JSON, enforcing output format).
- Security and Compliance: Can apply data masking or anonymization to sensitive data before it's sent to an external LLM, helping to meet data privacy regulations.
For developers looking to streamline the integration of diverse AI models and manage their lifecycle effectively, solutions like an LLM Gateway become indispensable. An excellent open-source example in this space is ApiPark. APIPark serves as both an AI gateway and an API management platform, simplifying the quick integration of over 100+ AI models and offering a unified API format for AI invocation. This means you can standardize request data formats, encapsulate prompts into REST APIs, and gain end-to-end API lifecycle management – all critical features when dealing with complex AI-driven microservices. With APIPark, you can abstract away the complexities of different AI model APIs, transforming varied request formats into a unified standard, which drastically reduces maintenance costs and accelerates development. Furthermore, its ability to encapsulate custom prompts into standard REST APIs allows developers to quickly create specialized AI services like sentiment analysis or data extraction, without deep knowledge of underlying AI models. Features such as centralized authentication, detailed call logging, and powerful data analysis for historical trends ensure that AI integrations are not just functional, but also secure, performant, and cost-effective.
3.4 Hybrid Approaches: Combining Rules with AI
While LLMs are powerful, a purely LLM-driven bot can be expensive and sometimes unpredictable. A robust approach often involves a hybrid model:
- Rule-Based for Deterministic Tasks: For simple, predictable interactions (e.g., "What is your return policy?" with a static answer, or "Reset my password" which triggers a specific workflow), rule-based systems or traditional intent classifiers can be more efficient, cost-effective, and reliable.
- LLM for Complex or Unforeseen Queries: When the user query is ambiguous, complex, or falls outside predefined rules, the LLM can be invoked to interpret intent, extract entities, or generate a dynamic response.
- Retrieval-Augmented Generation (RAG): This pattern combines information retrieval with LLM generation. The bot first retrieves relevant information from a knowledge base (e.g., product documentation, FAQ articles) and then feeds this information into the LLM as context for generating a more accurate and grounded response, reducing hallucinations.
By intelligently combining these approaches, developers can build bots that are both highly capable and efficient, optimizing for cost, performance, and accuracy.
APIPark is a high-performance AI gateway that allows you to securely access the most comprehensive LLM APIs globally on the APIPark platform, including OpenAI, Anthropic, Mistral, Llama2, Google Gemini, and more.Try APIPark now! 👇👇👇
4. Core Development Practices and Technologies
Building microservices input bots requires a selection of appropriate programming languages, frameworks, and tools to ensure efficient development, deployment, and operation. The beauty of microservices is the flexibility to choose the best tool for each job.
4.1 Language Choices: Matching the Task
The choice of programming language often depends on the specific service's requirements and the team's expertise.
- Python: The undisputed king for AI/ML workloads. With libraries like TensorFlow, PyTorch, scikit-learn, and Hugging Face Transformers, Python is ideal for NLP, NLU, and integrating with LLMs. Its rich ecosystem and rapid development cycle make it a favorite for data-intensive and intelligent services. Frameworks like Flask or FastAPI are excellent for creating lightweight, high-performance web services for machine learning models.
- Java: A robust, mature, and highly performant language, Java with Spring Boot is a powerhouse for building enterprise-grade backend services. It's excellent for transactional services, complex business logic, and services requiring high concurrency and reliability. Its strong typing and extensive ecosystem are beneficial for large teams and complex domains.
- Node.js: For I/O-bound services that handle many concurrent connections (e.g., API Gateway, real-time communication services, proxy services), Node.js with Express or Fastify is an excellent choice. Its asynchronous, non-blocking nature makes it highly efficient for handling numerous client requests without significant overhead.
- Go (Golang): Known for its performance, efficiency, and concurrency primitives, Go is increasingly popular for building infrastructure components, high-performance network services, and lightweight microservices. It compiles to a single static binary, making deployment straightforward. Ideal for performance-critical components or services interacting directly with underlying infrastructure.
4.2 Frameworks: Accelerating Development
Frameworks provide structure and common functionalities, speeding up development and ensuring consistency.
- Spring Boot (Java): A comprehensive framework for building production-ready, stand-alone Java applications. It simplifies configuration and dependency management, making it easy to create microservices that are robust and scalable.
- Flask / FastAPI (Python): Lightweight web frameworks for Python. Flask is simple and flexible, while FastAPI leverages modern Python features (type hints) for excellent performance and automatic API documentation. Perfect for exposing ML models as microservices.
- Express.js / NestJS (Node.js): Express is a minimal and flexible Node.js web application framework. NestJS is a more opinionated, full-featured framework inspired by Angular, suitable for building scalable server-side applications with TypeScript.
4.3 Containerization (Docker): Packaging for Portability
Docker has become the de facto standard for packaging microservices. Each service, along with its dependencies, is encapsulated within a lightweight, portable container.
- Isolation: Containers provide process isolation, ensuring that each service runs in its own environment without interfering with others.
- Portability: A Docker container can run consistently across any environment that supports Docker (developer's laptop, staging server, production cloud). This "build once, run anywhere" capability simplifies deployment significantly.
- Resource Efficiency: Containers are much lighter than virtual machines, consuming fewer resources and starting up faster.
- Version Control: Docker images can be versioned, allowing for easy rollback to previous stable versions if issues arise.
4.4 Orchestration (Kubernetes): Managing Containerized Services
While Docker packages individual services, Kubernetes (K8s) orchestrates them. It's an open-source system for automating deployment, scaling, and management of containerized applications.
- Automated Deployment: Deploying and updating services with declarative configurations.
- Self-Healing: Automatically restarts failed containers, replaces unhealthy ones, and reschedules containers on healthy nodes.
- Horizontal Scaling: Easily scale services up or down based on demand, either manually or automatically through Horizontal Pod Autoscalers.
- Load Balancing: Distributes network traffic to ensure stability and performance.
- Service Discovery: Provides built-in service discovery mechanisms for inter-service communication.
- Resource Management: Efficiently manages CPU, memory, and storage resources across a cluster of machines.
Kubernetes is the standard for running microservices in production, providing the robustness and scalability required for complex input bots.
4.5 Database Choices: Storing the Right Data in the Right Place
With the database per service pattern, different services can leverage different types of databases tailored to their specific data access patterns.
| Database Type | Examples | Use Cases for Input Bots | Advantages | Disadvantages |
|---|---|---|---|---|
| Relational (SQL) | PostgreSQL, MySQL, SQL Server | User profiles, order management, transactional data, structured configurations where data integrity and complex joins are crucial. | Strong consistency, mature, ACID properties, complex querying (SQL). | Scalability challenges (vertical scaling), less flexible schema. |
| Document (NoSQL) | MongoDB, Couchbase, DynamoDB | Storing conversational history, user preferences, unstructured logs, or semi-structured data like JSON documents. | Flexible schema, highly scalable (horizontal), good for rapid development. | Weaker consistency models, limited support for complex joins. |
| Key-Value (NoSQL) | Redis, Memcached, DynamoDB | Caching frequently accessed data (e.g., LLM responses), session management, rate limiting counters. | Extremely fast read/write, high scalability, simple API. | Limited query capabilities, data stored as opaque blobs. |
| Graph (NoSQL) | Neo4j, Amazon Neptune | Managing complex relationships (e.g., social networks for user recommendations, knowledge graphs for context awareness). | Excellent for traversing relationships, uncovering hidden connections. | Niche use case, steeper learning curve, less mature tooling. |
| Search Engine | Elasticsearch, Apache Solr | Full-text search on product catalogs, FAQs, documentation; analytical dashboards on bot interactions. | Powerful full-text search, analytics capabilities, high scalability. | Not a primary data store for transactional data, eventually consistent. |
Careful consideration of each service's data requirements will lead to an optimal and performant database landscape.
4.6 Event Streaming: Real-time Data Flow
Event streaming platforms, primarily Apache Kafka, are foundational for building event-driven microservices architectures.
- Decoupling: Services communicate asynchronously by producing and consuming events from topics, reducing direct dependencies.
- Scalability: Kafka is designed for high-throughput, fault-tolerant data streaming, capable of handling millions of events per second.
- Durability: Events are persisted, allowing consumers to replay historical data or catch up if they were offline.
- Real-time Processing: Enables real-time analytics, notifications, and complex event processing, crucial for dynamic bot responses or proactive actions.
For an input bot, Kafka can be used for: * Broadcasting user input events after initial processing. * Propagating state changes (e.g., "order status updated") across relevant services. * Collecting real-time interaction logs for analytics.
By leveraging these core development practices and technologies, developers can construct a robust, scalable, and intelligent microservices input bot capable of meeting diverse and evolving requirements.
5. Building a Sample Microservices Input Bot: E-commerce Customer Support
To illustrate these concepts, let's consider building a microservices input bot for an e-commerce customer support scenario. This bot will handle common queries such as checking order status, getting product information, and offering personalized recommendations.
5.1 Scenario: E-commerce Customer Support Bot
Our bot aims to offload common customer service inquiries, allowing human agents to focus on more complex issues. The bot needs to be available 24/7, highly responsive, and capable of understanding natural language queries.
5.2 Service Breakdown for the E-commerce Bot
Here's how we might decompose the bot's functionality into microservices:
AuthService(Java/Spring Boot):- Handles user authentication (login, session management) and issues JWT tokens.
- Verifies user identity for sensitive actions like checking order status.
- Database: PostgreSQL (for user credentials and roles).
InputChannelGateway(Node.js/Express):- Acts as the primary entry point for users interacting with the bot (e.g., through a web widget, Slack, or SMS).
- Receives user messages, performs basic parsing, and forwards them to the API Gateway.
- Handles sending bot responses back to the user through the specific channel API.
APIGateway(Go/Kong or Node.js/APIGateway framework):- The single entry point for all internal bot services.
- Routes requests from
InputChannelGatewayto theBotOrchestrationService. - Enforces rate limiting, authenticates requests (via
AuthService), and logs all incoming traffic.
BotOrchestrationService(Python/FastAPI):- The brain of the bot. Receives processed input, determines the overall intent and workflow.
- Calls
LLMIntegrationServiceto understand complex queries. - Orchestrates calls to
OrderService,ProductCatalogService,RecommendationServicebased on user intent. - Constructs the overall response and sends it to
OutputGenerationService.
LLMIntegrationService(Python/FastAPI):- This is where the LLM Gateway (like APIPark) is crucial.
- Receives raw or semi-processed natural language queries.
- Uses the LLM Gateway to interact with various LLMs for:
- Intent Recognition: "Is the user asking about an order, a product, or something else?"
- Entity Extraction: "What is the order number?", "What product are they looking for?"
- Sentiment Analysis: "Is the user frustrated?"
- Complex Question Answering: When no simple rule applies.
- Database: Redis (for caching LLM responses and prompt versions).
OrderService(Java/Spring Boot):- Manages all order-related functionalities: retrieve order status, view order history, cancel order (with authorization).
- Database: PostgreSQL (for transactional order data).
ProductCatalogService(Python/FastAPI or Node.js/Express):- Provides information about products: product details, pricing, availability.
- Handles searches for products based on keywords or categories.
- Database: MongoDB (for flexible product schemas).
RecommendationService(Python/Flask or Go):- Generates personalized product recommendations based on user history, browsing patterns, or current context.
- Could leverage a graph database or a machine learning model.
- Database: Neo4j (for recommendation graphs) or a NoSQL store for user interaction logs.
NotificationService(Go/gRPC):- Sends proactive notifications (e.g., "order shipped," "price drop alert").
- Integrates with email, SMS, or in-app notification providers.
- Consumes events from Kafka.
OutputGenerationService(Python/FastAPI):- Takes structured data from
BotOrchestrationServiceand generates natural language responses. - Can use templating engines or call the LLM Gateway for more dynamic, generative responses.
- Ensures responses are concise, polite, and contextually appropriate.
- Takes structured data from
5.3 Interaction Flow: Checking Order Status
Let's trace a typical user interaction: "What's the status of my order 12345?"
- User Input: User types "What's the status of my order 12345?" into the web widget.
InputChannelGateway: Receives the message, adds channel-specific metadata, and forwards it to the API Gateway.APIGateway:- Receives the request.
- Performs initial authentication (e.g., validates a session token).
- Routes the request to the
BotOrchestrationService. - Logs the incoming request.
BotOrchestrationService:- Receives the message.
- Calls the
LLMIntegrationServicewith the raw query.
LLMIntegrationService:- Forwards the query to the underlying LLM Gateway.
- The LLM Gateway (e.g., APIPark) processes the query, identifies the intent "check order status," and extracts the entity "order number: 12345." It might also cache this query/response if it's common.
- Returns the structured intent and entities to
BotOrchestrationService.
BotOrchestrationService:- Recognizes the "check order status" intent.
- Calls
AuthServiceto verify the user's authorization to view this order. - If authorized, calls
OrderServicewith "order number: 12345" and the user ID.
OrderService:- Queries its PostgreSQL database for order 12345 belonging to the authenticated user.
- Retrieves order details (e.g., "shipped," "delivery date: tomorrow").
- Returns the structured order status to
BotOrchestrationService.
BotOrchestrationService:- Receives the order status.
- Passes the structured data to
OutputGenerationService.
OutputGenerationService:- Generates a natural language response: "Your order 12345 has been shipped and is expected to arrive tomorrow."
- Returns the response text to
BotOrchestrationService.
BotOrchestrationService:- Forwards the response to the
APIGateway.
- Forwards the response to the
APIGateway:- Logs the outbound response.
- Forwards the response to
InputChannelGateway.
InputChannelGateway:- Formats the response for the web widget and displays it to the user.
This example demonstrates how different services collaborate, orchestrated by the BotOrchestrationService and facilitated by the API Gateway and LLM Gateway, to fulfill a user request.
5.4 Pseudo-code Snippets
BotOrchestrationService (Python/FastAPI):
from fastapi import APIRouter, Depends, HTTPException
import httpx # For making HTTP requests to other services
router = APIRouter()
# Dependency for authentication (simplified)
async def get_current_user(token: str):
# Call AuthService to validate token and get user ID
async with httpx.AsyncClient() as client:
response = await client.get(f"http://auth-service/validate-token/{token}")
if response.status_code != 200:
raise HTTPException(status_code=401, detail="Invalid token")
return response.json()["user_id"]
@router.post("/techblog/en/process_input")
async def process_user_input(message: str, user_id: str = Depends(get_current_user)):
# 1. Call LLMIntegrationService via LLM Gateway for intent/entities
async with httpx.AsyncClient() as client:
llm_response = await client.post("http://llm-integration-service/parse_query", json={"query": message, "user_id": user_id})
if llm_response.status_code != 200:
raise HTTPException(status_code=500, detail="LLM service error")
parsed_data = llm_response.json()
intent = parsed_data.get("intent")
entities = parsed_data.get("entities", {})
response_text = "Sorry, I couldn't understand that."
if intent == "check_order_status":
order_number = entities.get("order_number")
if order_number:
# 2. Call OrderService
order_response = await client.get(f"http://order-service/orders/{order_number}?user_id={user_id}")
if order_response.status_code == 200:
order_details = order_response.json()
# 3. Call OutputGenerationService
output_response = await client.post("http://output-generation-service/generate_response",
json={"template": "order_status", "data": order_details})
response_text = output_response.json()["text"]
else:
response_text = "I couldn't find that order or you don't have permission."
else:
response_text = "Please provide an order number."
elif intent == "get_product_info":
product_name = entities.get("product_name")
if product_name:
# Call ProductCatalogService
product_response = await client.get(f"http://product-catalog-service/products/search?name={product_name}")
if product_response.status_code == 200:
product_details = product_response.json()
output_response = await client.post("http://output-generation-service/generate_response",
json={"template": "product_info", "data": product_details})
response_text = output_response.json()["text"]
else:
response_text = "Sorry, I couldn't find that product."
else:
response_text = "What product are you interested in?"
# ... handle other intents
return {"response": response_text}
LLMIntegrationService (Python/FastAPI) using hypothetical LLM Gateway client:
from fastapi import APIRouter
from pydantic import BaseModel
import httpx
router = APIRouter()
class QueryRequest(BaseModel):
query: str
user_id: str # For context/personalization
@router.post("/techblog/en/parse_query")
async def parse_user_query(request: QueryRequest):
# This service interacts with the APIPark (our LLM Gateway)
# The LLM Gateway abstracts away specific LLM providers (OpenAI, Google, etc.)
# and handles prompt engineering, caching, routing, and cost management.
llm_gateway_url = "https://your-apipark-instance/v1/llm/completion" # Example URL
prompt_template = f"""
The user is asking: "{request.query}"
Analyze the user's intent and extract relevant entities.
Respond in JSON format with 'intent' and 'entities'.
Example: {{ "intent": "check_order_status", "entities": {{ "order_number": "12345" }} }}
"""
async with httpx.AsyncClient() as client:
# Assuming APIPark has a standardized API for LLM invocation
response = await client.post(
llm_gateway_url,
headers={"Authorization": "Bearer YOUR_APIPARK_API_KEY"}, # APIPark handles underlying LLM keys
json={
"model": "gpt-4-turbo", # APIPark can route this to the actual LLM
"messages": [{"role": "user", "content": prompt_template}],
"temperature": 0.1,
"max_tokens": 150
}
)
if response.status_code != 200:
print(f"Error from LLM Gateway: {response.status_code} - {response.text}")
raise HTTPException(status_code=500, detail="Failed to parse query via LLM Gateway")
llm_output = response.json()
# Assume LLM Gateway returns the parsed JSON directly from the LLM's response
# or performs its own post-processing.
try:
parsed_data = json.loads(llm_output["choices"][0]["message"]["content"])
except json.JSONDecodeError:
print(f"LLM output was not valid JSON: {llm_output['choices'][0]['message']['content']}")
raise HTTPException(status_code=500, detail="LLM returned invalid format")
return parsed_data
This simple example showcases the interaction. In a real-world scenario, each service would have significantly more complex logic, robust error handling, and comprehensive unit/integration tests.
6. Deployment, Scaling, and Operations
Once your microservices input bot is developed, the next critical phase involves deploying, scaling, and maintaining it in production. This encompasses a range of practices from automated pipelines to comprehensive monitoring and management.
6.1 CI/CD Pipelines: Automating the Journey to Production
Continuous Integration (CI) and Continuous Deployment/Delivery (CD) pipelines are essential for microservices. They automate the build, test, and deployment processes, enabling frequent and reliable releases.
- Continuous Integration: Developers commit code frequently to a shared repository. Each commit triggers an automated build and a suite of tests (unit, integration, static analysis). This ensures that code changes are continuously validated and integrated without breaking the existing system.
- Continuous Deployment/Delivery: After successful CI, changes are automatically deployed to staging or production environments. Continuous Delivery means changes are always ready for release, while Continuous Deployment means they are automatically released. This greatly reduces manual effort, speeds up releases, and reduces human error.
Tools like Jenkins, GitLab CI/CD, GitHub Actions, CircleCI, or Azure DevOps are commonly used to implement these pipelines.
6.2 Cloud Platforms: Leveraging Managed Services
Modern microservices are almost exclusively deployed on cloud platforms (AWS, Azure, GCP). These platforms offer a wealth of managed services that significantly simplify operations:
- Compute: Managed Kubernetes (EKS, AKS, GKE) for orchestrating containers, or serverless functions (AWS Lambda, Azure Functions, Google Cloud Functions) for event-driven, cost-effective execution of specific tasks.
- Databases: Managed database services (Amazon RDS, Azure SQL Database, Google Cloud SQL for relational; DynamoDB, Cosmos DB, Firestore for NoSQL) eliminate the need to manage database infrastructure.
- Messaging: Managed message queues and event streaming platforms (Amazon SQS, Azure Service Bus, Google Cloud Pub/Sub, Confluent Cloud for Kafka) provide reliable asynchronous communication without operational overhead.
- Networking: Managed load balancers, API Gateways (Amazon API Gateway, Azure API Management, Google Cloud Apigee), and virtual private clouds (VPCs) provide robust networking and external access.
- Monitoring & Logging: Cloud-native services (CloudWatch, Azure Monitor, Google Cloud Operations Suite) provide comprehensive observability.
Leveraging these managed services allows development teams to focus on business logic rather than infrastructure management.
6.3 Scaling Strategies: Meeting Demand
Microservices architecture inherently supports scaling.
- Horizontal Scaling: Adding more instances of a service. This is the primary scaling mechanism for microservices, handled efficiently by container orchestrators like Kubernetes. When the
NLPServiceexperiences high load, Kubernetes can automatically spin up more pods to handle the incoming requests. - Vertical Scaling: Increasing the resources (CPU, RAM) of a single instance. Less common for microservices, as it eventually hits limits and doesn't improve resilience as much as horizontal scaling.
- Auto-scaling Groups: Dynamically adjusting the number of service instances based on predefined metrics (CPU utilization, request queue length, custom metrics). This ensures that the bot can handle fluctuating loads efficiently and cost-effectively.
6.4 Monitoring and Alerting: Staying Informed
As discussed in Section 2.6, robust monitoring and alerting are crucial for operational health.
- Metrics: Collect detailed metrics from all services (application-level metrics like request latency, error rates, and business metrics like bot accuracy; infrastructure metrics like CPU/memory usage).
- Dashboards: Visualize key metrics on dashboards (Grafana, Kibana, cloud provider dashboards) to get a real-time overview of system health.
- Alerting: Set up alerts for critical thresholds (e.g., high error rates, low available memory, slow response times, high LLM costs). Alerts should be routed to appropriate channels (PagerDuty, Slack, email) to notify operations teams immediately.
- Tracing: Use distributed tracing to pinpoint performance bottlenecks or errors across service calls.
6.5 Security Considerations: Protecting Your Bot
Security must be baked into every layer of your microservices input bot.
- Authentication and Authorization: Implement robust mechanisms at the API Gateway level and within individual services. Use token-based authentication (JWT, OAuth2). Ensure fine-grained authorization policies.
- Data Encryption: Encrypt data both in transit (TLS/SSL for all communication, even internal) and at rest (disk encryption for databases and storage).
- Vulnerability Scanning: Regularly scan containers, libraries, and application code for known vulnerabilities.
- Principle of Least Privilege: Grant services and users only the minimum permissions necessary to perform their functions.
- Network Segmentation: Isolate services using network policies (e.g., Kubernetes Network Policies) to restrict communication between services only to what is explicitly required.
- Secrets Management: Use secure solutions (Vault, AWS Secrets Manager, Azure Key Vault) to store and retrieve API keys, database credentials, and other sensitive configurations, rather than hardcoding them.
6.6 Management and Control Plane (MCP): The Central Nervous System
For complex microservices deployments, particularly those involving service meshes and advanced API Gateway functionalities, a Management and Control Plane (MCP) becomes an essential part of the operational toolkit. An MCP provides a centralized interface and intelligence layer for managing, configuring, and orchestrating the entire microservices ecosystem.
6.6.1 What an MCP Encompasses:
- Service Mesh Control Plane: For service meshes like Istio or Linkerd, the MCP is the "control plane" that configures and manages the "data plane" proxies (sidecars) attached to each service. It sets policies for traffic routing, load balancing, security (mutual TLS), and observability (collecting metrics and traces). This allows for sophisticated traffic management and policy enforcement without modifying service code.
- API Gateway Management: Many advanced API Gateways (and especially LLM Gateways) come with their own MCP to configure routes, policies, rate limits, authentication, and monitor traffic across all APIs.
- Infrastructure Orchestration: Beyond specific service mesh or API Gateway concerns, an overarching MCP can provide a unified view and control over cloud resources, Kubernetes clusters, and deployment pipelines. It's the single pane of glass for monitoring resource utilization, scaling, and applying infrastructure-as-code principles.
- Policy Enforcement: Defines and enforces organizational policies across the microservices, such as security policies, compliance rules, or resource allocation policies.
- Configuration Management: Centralizes the management and distribution of configurations to various microservices, ensuring consistency and controlled updates.
In the context of our microservices input bot, an MCP would allow you to: * Configure traffic splitting for A/B testing different versions of your LLMIntegrationService. * Enforce security policies like mutual TLS between the BotOrchestrationService and OrderService. * Centrally manage API keys for external integrations through the API Gateway and LLM Gateway. * Monitor service health and resource consumption across the entire bot infrastructure from a single dashboard.
The MCP simplifies the complexity of operating a distributed system by providing a high-level abstraction and automation capabilities, enabling teams to manage the bot's lifecycle more effectively and respond rapidly to operational challenges. It’s the conductor of your microservices orchestra, ensuring all components play in harmony.
7. Advanced Topics and Best Practices
To move beyond the basics and build truly resilient, high-performing, and secure microservices input bots, developers must embrace several advanced topics and best practices.
7.1 Fault Tolerance & Resilience: Building for Failure
In a distributed system, failures are inevitable. Designing for resilience means expecting failures and building mechanisms to gracefully handle them.
- Circuit Breakers: Prevent cascading failures. If a service experiences repeated failures or high latency when calling an external dependency, the circuit breaker "opens," preventing further calls to that dependency and quickly returning an error. After a timeout, it allows a small number of requests to "half-open" the circuit to check if the dependency has recovered.
- Retry Mechanisms: Implement intelligent retry logic for transient failures (e.g., network glitches, temporary service unavailability). Use exponential backoff to avoid overwhelming the failing service.
- Bulkheads: Isolate services to prevent failures in one area from affecting others. For instance, dedicate separate thread pools or network connections for different types of requests or external dependencies.
- Timeouts: Configure strict timeouts for all inter-service communication to prevent calls from hanging indefinitely and consuming resources.
- Idempotency: Design operations to be idempotent, meaning performing them multiple times has the same effect as performing them once. This simplifies retry logic and ensures data consistency even in the face of network retries.
- Graceful Degradation: Design your bot to continue functioning, perhaps with reduced capabilities, if certain non-critical services are unavailable. For example, if the
RecommendationServiceis down, the bot can still check order status and provide product info, but won't offer personalized suggestions.
7.2 Testing Strategies: Ensuring Quality and Reliability
Comprehensive testing is non-negotiable for microservices.
- Unit Tests: Test individual components (functions, classes) in isolation.
- Integration Tests: Verify that services correctly interact with each other and with external dependencies (databases, message queues, external APIs). This might involve mocking external systems or using test containers.
- Contract Tests: Ensure that consumers (clients) of a service's API are compatible with the provider (service). Tools like Pact can help define and enforce contracts between services, preventing breaking changes.
- End-to-End Tests: Simulate real user scenarios to verify the entire bot flow from input to output, traversing multiple services. These are valuable but can be brittle and slow.
- Performance Tests: Load testing, stress testing, and scalability testing to ensure services can handle expected (and peak) loads, identify bottlenecks, and verify auto-scaling configurations.
- Chaos Engineering: Deliberately injecting failures into the system (e.g., shutting down a service instance, introducing network latency) to test its resilience in a controlled environment. Tools like Chaos Monkey can automate this.
7.3 Security Hardening: Protecting Against Threats
Beyond basic authentication and encryption, a deeper dive into security is vital.
- OAuth2 and OpenID Connect: Use these standards for secure user authentication and authorization, especially when integrating with third-party identity providers.
- JSON Web Tokens (JWT): A common standard for securely transmitting information between parties as a JSON object, often used for session management and authorization. Ensure tokens are signed and validated.
- API Keys Management: Use dedicated API key management systems (as APIPark does for AI models) for external API integrations, with features like key rotation, revocation, and usage monitoring.
- Input Validation and Sanitization: Rigorously validate and sanitize all user input to prevent injection attacks (SQL injection, cross-site scripting, prompt injection for LLMs).
- Least Privilege Principle: Apply this principle to database access, cloud resource permissions, and inter-service communication.
- Security Audits and Penetration Testing: Regularly conduct external security audits and penetration tests to identify vulnerabilities.
- Image Security: Use trusted base images for containers and scan them for vulnerabilities using tools like Trivy or Clair.
7.4 Cost Optimization: Running Efficiently
Operating microservices, especially with LLM usage, can be expensive.
- Resource Sizing: Right-size your containers and cloud instances. Don't over-provision CPU and memory. Use metrics to find the optimal balance.
- Auto-scaling: Leverage auto-scaling to dynamically adjust resources based on demand, avoiding unnecessary costs during off-peak hours.
- Serverless Functions: Use serverless compute (Lambda, Azure Functions) for event-driven, sporadic, or bursty workloads where you only pay for actual execution time.
- Managed Services: While they might seem more expensive upfront, managed database, messaging, and compute services often provide better cost efficiency due to reduced operational overhead.
- LLM Gateway for Cost Control: Utilize the features of an LLM Gateway (like APIPark) to manage LLM costs through intelligent routing, caching, rate limiting, and detailed cost tracking. Prioritize cheaper models for less critical tasks.
- Spot Instances/Preemptible VMs: For fault-tolerant or non-critical workloads, using these cheaper, interruptible instances can significantly reduce compute costs.
7.5 Ethical AI Considerations: Responsibility in Automation
As input bots become more intelligent and autonomous, ethical considerations become paramount.
- Bias Detection and Mitigation: LLMs can inherit biases from their training data. Implement mechanisms to detect and mitigate bias in bot responses and decision-making. Regularly audit the bot's behavior.
- Transparency and Explainability: Be transparent with users that they are interacting with a bot. For critical decisions, strive for explainability – how did the bot arrive at a particular recommendation or conclusion?
- Privacy: Handle user data with the utmost care, adhering to regulations like GDPR and CCPA. Anonymize or pseudonymize data where possible, especially when interacting with external AI models.
- Fairness: Ensure the bot's algorithms treat all users fairly and do not discriminate based on protected characteristics.
- Safety and Harm Reduction: Implement safeguards to prevent the bot from generating harmful, inappropriate, or misleading content. This includes robust content moderation and prompt injection defenses.
- Human Oversight: Design systems that allow for human intervention and override, especially for high-stakes decisions. The bot should augment, not fully replace, human judgment in critical areas.
Building microservices input bots is an intricate but incredibly rewarding endeavor. By meticulously applying these architectural principles, leveraging modern technologies, and adhering to best practices in development, operations, and ethics, developers can craft intelligent, resilient, and impactful automated systems that push the boundaries of user interaction and business automation. The journey involves continuous learning and adaptation, but the resulting capabilities empower organizations to navigate the complexities of the digital age with unprecedented agility and intelligence.
Frequently Asked Questions (FAQs)
Q1: What is the primary advantage of using a microservices architecture for an input bot compared to a monolithic one?
The primary advantage lies in enhanced scalability, resilience, and independent deployability. In a microservices architecture, individual components of the bot (like NLP, authentication, or business logic) can be developed, scaled, and deployed independently. This means that if your NLP service experiences a surge in traffic, you can scale just that component without affecting other parts of the bot. If one service fails, the entire bot doesn't necessarily go down, leading to higher fault tolerance. This modularity also allows different teams to work on different services using diverse technologies, accelerating development and enabling faster iterations.
Q2: How does an API Gateway contribute to the efficiency and security of a microservices input bot?
An API Gateway acts as the single entry point for all client requests, abstracting away the internal complexity of your microservices. For an input bot, it centralizes crucial functionalities like request routing, authentication, authorization, and rate limiting. This simplifies client interactions by providing a consistent interface, offloads security responsibilities from individual services, and protects your backend from malicious traffic or overload. It also provides a central point for logging and monitoring all incoming requests, offering invaluable insights into bot usage and performance.
Q3: Why is an LLM Gateway necessary when integrating Large Language Models (LLMs) into a microservices bot?
An LLM Gateway is crucial for abstracting the complexities of interacting with various LLM providers and models. It provides a unified API for your microservices to consume LLM capabilities, regardless of the underlying model (e.g., OpenAI, Google). Key benefits include centralized authentication and key management, intelligent routing to different LLMs based on cost or capability, caching of LLM responses to reduce latency and cost, prompt versioning, and detailed cost tracking. This prevents vendor lock-in, enhances security, optimizes performance, and significantly reduces the operational overhead of managing multiple AI integrations.
Q4: What role does a Management and Control Plane (MCP) play in operating a microservices input bot?
A Management and Control Plane (MCP) provides a centralized layer for managing, configuring, and orchestrating the entire microservices ecosystem. In the context of an input bot, it enables you to manage components like service meshes (for traffic control, security, and observability between services), API Gateways, and even cloud infrastructure from a unified interface. An MCP allows for advanced policy enforcement, configuration management, and provides a single pane of glass for monitoring and troubleshooting your distributed bot infrastructure, simplifying complex operational tasks and ensuring consistent deployment strategies.
Q5: What are the key ethical considerations when building intelligent microservices input bots?
As bots become more intelligent, ethical considerations are paramount. Key areas include ensuring fairness and mitigating bias (LLMs can inherit biases from training data), providing transparency to users that they are interacting with an AI, protecting data privacy (especially when sensitive user data interacts with external AI models), and implementing safeguards for safety and harm reduction (preventing the bot from generating inappropriate or harmful content). It's also vital to consider human oversight and intervention mechanisms, especially for high-stakes decisions, ensuring the bot augments human capabilities rather than replaces critical judgment.
🚀You can securely and efficiently call the OpenAI API on APIPark in just two steps:
Step 1: Deploy the APIPark AI gateway in 5 minutes.
APIPark is developed based on Golang, offering strong product performance and low development and maintenance costs. You can deploy APIPark with a single command line.
curl -sSO https://download.apipark.com/install/quick-start.sh; bash quick-start.sh

In my experience, you can see the successful deployment interface within 5 to 10 minutes. Then, you can log in to APIPark using your account.

Step 2: Call the OpenAI API.