Seamlessly Access REST APIs Using GraphQL


The digital ecosystem of the 21st century is built upon the intricate web of Application Programming Interfaces (APIs). From mobile applications fetching real-time data to complex enterprise systems orchestrating microservices, the api serves as the fundamental conduit for information exchange. For years, REST (Representational State Transfer) has reigned supreme as the architectural style of choice for building web services, celebrated for its simplicity, statelessness, and adherence to standard HTTP methods. However, as applications have grown increasingly sophisticated, demanding more nuanced data interactions and highly tailored responses, the inherent limitations of traditional REST APIs have become more apparent. Developers frequently grapple with challenges like over-fetching (receiving more data than needed), under-fetching (requiring multiple requests to gather all necessary data), and the rigid structure of fixed endpoints.
Enter GraphQL, a powerful query language for APIs and a runtime for fulfilling those queries with your existing data. Conceived and open-sourced by Facebook, GraphQL offers a revolutionary approach to data fetching, empowering clients to declare precisely what data they need, no more, no less. This paradigm shift holds immense promise, particularly for developers looking to create seamless, efficient, and highly customized data experiences. But what if your existing infrastructure is heavily invested in REST? The prospect of rewriting entire backend services to accommodate GraphQL can be daunting, if not economically unfeasible. This comprehensive guide delves into the elegant solution of using GraphQL as a sophisticated facade over existing REST APIs, offering a pathway to harness the best of both worlds. We will explore the technical intricacies, architectural considerations, and practical benefits of this hybrid approach, demonstrating how it can unlock unparalleled flexibility, enhance developer experience, and future-proof your api strategy in an increasingly data-driven landscape. By carefully crafting this integration, organizations can continue to leverage their robust RESTful services while simultaneously providing a modern, client-driven data access layer that meets the dynamic demands of contemporary applications.
The Enduring Foundation: Understanding REST APIs and Their Context
Before we embark on the journey of integrating GraphQL, it is imperative to thoroughly understand the foundational principles and widespread adoption of REST APIs. Born from Roy Fielding's doctoral dissertation in 2000, REST is an architectural style that defines a set of constraints for designing networked applications. At its core, REST views data as "resources" that can be manipulated using a uniform interface, typically HTTP methods like GET, POST, PUT, DELETE, and PATCH. Each resource is identified by a unique URI (Uniform Resource Identifier), and clients interact with these resources by sending requests and receiving responses, usually in JSON or XML format. This simplicity, coupled with its stateless nature (meaning each request from a client to a server contains all the information needed to understand the request, without relying on any stored session state on the server), has made REST an incredibly popular choice for web services. It integrates seamlessly with the existing web infrastructure, leveraging HTTP caching mechanisms and a clear separation of client and server concerns, which inherently promotes scalability and maintainability.
The prevalence of RESTful APIs means that a vast majority of existing backend services, microservices architectures, and third-party integrations are built upon this paradigm. Developers are familiar with its conventions, and a rich ecosystem of tools, libraries, and frameworks exists to support its implementation and consumption. The appeal of REST lies in its direct mapping to standard HTTP operations, making it intuitive for developers to understand how to interact with different data entities. For instance, retrieving a list of users might involve a GET /users request, while adding a new user would be a POST /users request with the user's data in the body. This predictable and standardized interaction model has been instrumental in fostering interoperability and accelerating the development of interconnected systems. Consequently, almost every modern application, from social media platforms to e-commerce sites and financial services, relies heavily on a multitude of RESTful apis to function. This deep entrenchment signifies that while new technologies emerge, the existing REST infrastructure represents a significant investment in time, effort, and established processes that cannot be easily discarded. The challenge, therefore, is not to replace REST entirely, but to augment and enhance its capabilities where it falls short, particularly in the face of evolving client-side data requirements.
Despite its undeniable strengths, REST faces growing challenges, especially in highly dynamic and data-intensive application environments. One of the most significant drawbacks is the issue of over-fetching and under-fetching data. When a client requests a resource from a REST endpoint, it typically receives a fixed structure of data predefined by the server. For example, GET /users/{id} might return all details of a user, including their name, email, address, phone number, and preferences. If a client only needs the user's name and email for a specific UI component, it still receives the entire payload, leading to unnecessary data transfer and increased latency, particularly on mobile networks or bandwidth-constrained environments. Conversely, under-fetching occurs when a single REST endpoint does not provide all the necessary data for a particular view, forcing the client to make multiple sequential requests to different endpoints to assemble the complete dataset. Imagine displaying a user's profile along with their last three orders and payment methods; this could necessitate calls to /users/{id}, /users/{id}/orders, and /users/{id}/payment-methods. Each additional network request introduces latency and complexity, impacting application performance and developer productivity.
Furthermore, REST API versioning can be cumbersome. As apis evolve, developers must often introduce new versions (e.g., api/v1, api/v2) to avoid breaking existing client applications. Managing these multiple versions, especially during migrations, adds significant overhead to both server-side and client-side development. The lack of a strong type system in typical REST responses can also lead to ambiguity regarding the expected data structure, often requiring external documentation or trial-and-error to understand. While tools like OpenAPI have emerged to address some of these documentation challenges, the fundamental architectural style of REST often necessitates a predefined and somewhat rigid contract between the client and server. These limitations highlight the growing need for a more flexible, client-centric api interaction model that can adapt to diverse data requirements without burdening the server with endpoint proliferation or the client with inefficient data fetching strategies.
Deconstructing GraphQL: A Paradigm Shift in Data Fetching
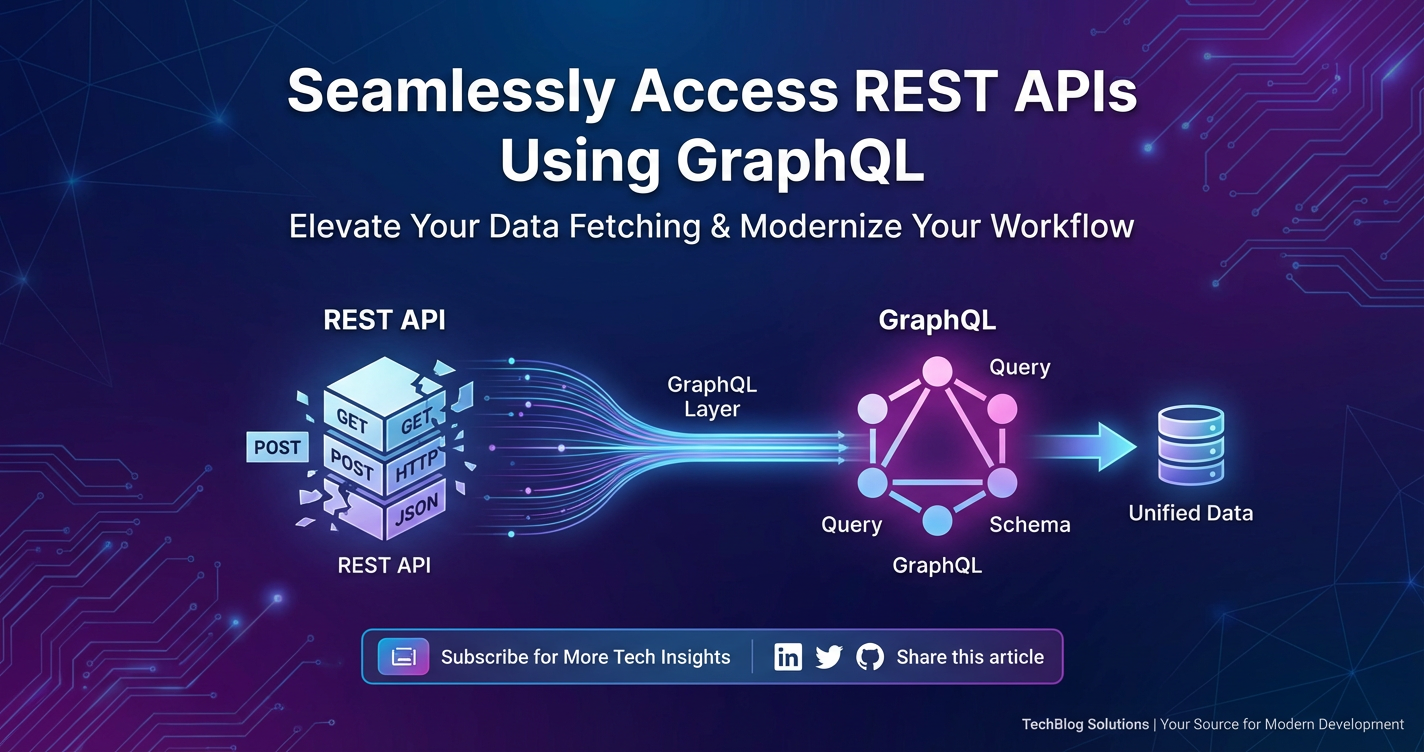
GraphQL represents a fundamental rethinking of how clients interact with APIs, moving away from resource-centric endpoints towards a more declarative, data-driven approach. At its heart, GraphQL is a query language for your APIs and a runtime for fulfilling those queries using your existing data. What truly sets it apart is its ability to allow clients to specify exactly what data they need, in the precise shape they require, and receive it in a single request. This is a dramatic departure from REST's model, where the server dictates the structure and content of the responses for each endpoint. With GraphQL, the server exposes a single endpoint, typically /graphql, and clients send complex queries to this endpoint describing their data requirements. The GraphQL server then interprets these queries, fetches the necessary data from various underlying sources (which could be databases, microservices, or even existing REST APIs), and constructs a response tailored specifically to the client's request. This highly efficient interaction model dramatically reduces the issues of over-fetching and under-fetching that plague traditional REST APIs, as clients are empowered to be hyper-specific about their data needs.
The core strength of GraphQL lies in its robust type system, which is defined in a schema. This schema acts as a contract between the client and the server, describing all the data that a client can query, including the types of objects, their fields, and the relationships between them. For instance, a schema might define a User type with fields like id, name, email, and posts, where posts itself could be an array of Post types. This strong typing provides several immediate benefits: it serves as built-in documentation, enabling developers to discover available data and relationships without referring to external specifications; it allows for powerful client-side tooling like auto-completion and validation in IDEs; and it ensures data consistency and reliability by enforcing type constraints. The schema also defines the entry points for data access, primarily through Queries, which are used to fetch data; Mutations, which are used to modify data (create, update, delete); and Subscriptions, which enable real-time, push-based data updates from the server to the client. This comprehensive and declarative approach to api interaction empowers developers to build more flexible, performant, and maintainable applications, shifting much of the data orchestration logic from the server to the client's query.
Consider a practical example to illustrate the contrast: With a traditional REST API, fetching a user's name, email, and the titles of their last three blog posts might involve: 1. GET /users/{id} to get user details (potentially over-fetching address, phone, etc.). 2. GET /users/{id}/posts to get all posts by the user (potentially over-fetching post content, creation date, etc.). 3. Client-side logic to filter down to the last three post titles.
With GraphQL, the same operation can be achieved with a single, precise query:
query GetUserDetailsAndPosts($userId: ID!) {
user(id: $userId) {
name
email
posts(first: 3) {
title
}
}
}
This single query clearly expresses the exact data requirements, and the GraphQL server responds with only the requested fields, nested as specified. This not only significantly reduces the number of network requests but also minimizes the amount of data transferred over the wire, leading to faster load times and a more responsive user experience, especially critical for mobile api consumption. Moreover, the flexibility offered by GraphQL empowers front-end developers to iterate faster. They can evolve their data requirements on the client-side without needing to wait for backend changes or new REST endpoints to be deployed. This decoupling accelerates development cycles and fosters greater autonomy for client-side teams. By consolidating data fetching through a single, intelligent endpoint, GraphQL streamlines api interactions, making data access more intuitive and efficient, and ultimately enhancing the overall developer experience.
Bridging the Gap: GraphQL as a Facade for REST APIs
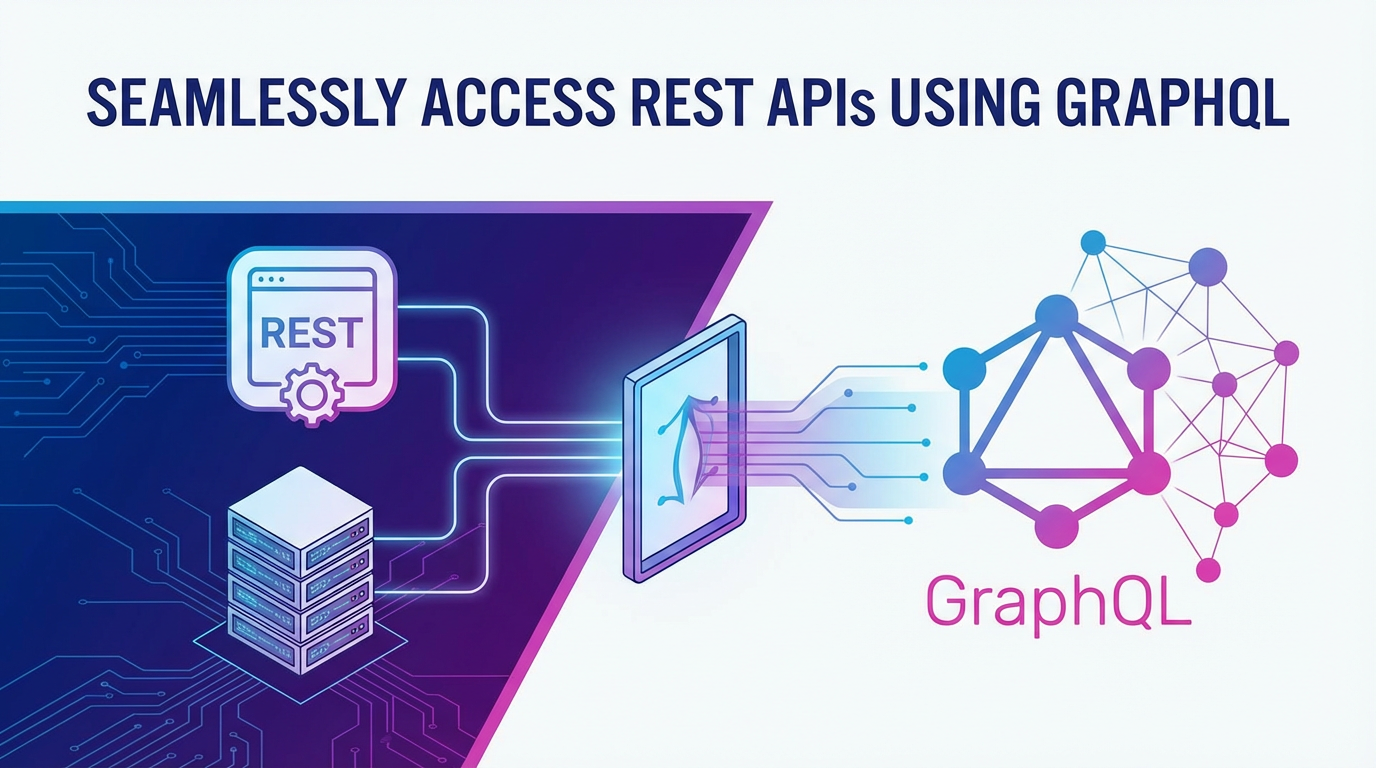
The notion of migrating an entire backend infrastructure from REST to GraphQL can be daunting, especially for organizations with large, established systems and a multitude of existing RESTful services. This is where the true power and elegance of GraphQL as a facade over existing REST APIs shines. Instead of a wholesale replacement, this approach advocates for building a GraphQL layer that sits in front of your existing REST services, acting as an intelligent intermediary. The GraphQL server does not directly manage its own data store; rather, it serves as a sophisticated query engine that translates incoming GraphQL queries into one or more calls to your underlying REST APIs. It then aggregates the responses from these REST services, transforms them into the shape requested by the GraphQL query, and delivers a single, consolidated payload back to the client. This strategy allows organizations to progressively adopt GraphQL, leveraging its benefits without necessitating a costly and risky "rip and replace" of their stable and functional REST services. It is an evolutionary, rather than revolutionary, path to modern api access.
The core idea is to define a GraphQL schema that represents the data entities and relationships your clients need, even if these entities are currently scattered across multiple REST endpoints. For instance, a User type in your GraphQL schema might map to data fetched from /api/v1/users/{id}, while a Product type might map to data from /api/v1/products/{id}. The magic happens within resolvers. In GraphQL, a resolver is a function that is responsible for fetching the data for a specific field in your schema. When a client sends a GraphQL query, the GraphQL execution engine traverses the query's fields and invokes the corresponding resolvers. For a GraphQL facade over REST, these resolvers are specifically designed to make HTTP requests to your existing REST APIs. For example, a resolver for the user.posts field might take the user.id obtained from a previous REST call, then make another REST call to /api/v1/users/{id}/posts to retrieve the user's posts. The resolver then processes this REST response, potentially filtering or transforming it, before returning the data in the format expected by the GraphQL schema.
There are primarily two architectural approaches to building this GraphQL layer: schema-first and code-first. In the schema-first approach, you define your GraphQL schema using GraphQL's Schema Definition Language (SDL) first. This schema then serves as the blueprint, and you write your resolvers to implement the data fetching logic for each field defined in the SDL. This method encourages a design-first mindset, ensuring that the api contract is clear and well-defined from the outset. In contrast, the code-first approach involves defining your schema directly in your programming language using decorators or classes, and the tools then generate the SDL from your code. Both approaches are viable, and the choice often depends on team preferences and existing development workflows. Regardless of the schema definition method, the heart of the integration remains the intelligent mapping of GraphQL fields to REST endpoint calls within the resolver functions.
To manage the inherent inefficiencies that can arise when a single GraphQL query translates into multiple, potentially redundant, REST calls (the N+1 problem), advanced techniques like Data Loaders are crucial. A Data Loader is a utility that provides a consistent, simple api over various caching and batching mechanisms. Instead of making a separate REST call for each item requested in a list, Data Loaders batch multiple requests for similar resources into a single underlying REST call, often delaying execution until the end of the event loop. For example, if a GraphQL query requests details for 10 users, a Data Loader can collect all 10 user IDs and make a single REST call to an endpoint like /api/v1/users?ids=1,2,3..., drastically reducing the number of network round trips and improving performance. Moreover, Data Loaders can implement caching, storing the results of REST calls for a short period to avoid redundant fetches of the same data within a single GraphQL request. By combining well-designed schemas, intelligent resolvers, and robust data loading strategies, developers can construct a highly efficient and performant GraphQL facade that seamlessly orchestrates data from diverse RESTful sources, presenting a unified and flexible api to client applications.
The Indispensable Role of an API Gateway in Modern Architectures
In the complex tapestry of modern microservices and distributed systems, an api gateway stands as a critical architectural component, serving as the single entry point for all client requests. Far more than just a reverse proxy, an API Gateway acts as a traffic cop, bouncer, and accountant for your backend services. It is responsible for a myriad of essential functions that ensure the security, reliability, and performance of your APIs. When external clients, whether web browsers, mobile applications, or third-party services, send requests, they don't directly interact with individual microservices or even the GraphQL facade in a complex setup. Instead, all requests are routed through the api gateway. This centralization offers significant advantages in managing, securing, and scaling an organization's digital offerings.
The core functionalities of an api gateway typically include: 1. Request Routing: It intelligently directs incoming requests to the appropriate backend services based on predefined rules, paths, or headers. This allows for flexible service composition and transparent routing even as backend services scale or change locations. 2. Authentication and Authorization: The gateway can handle authentication tokens (like JWTs), validate credentials, and enforce authorization policies before requests even reach the backend services. This offloads security concerns from individual services and ensures consistent api access control. 3. Rate Limiting and Throttling: To prevent abuse, ensure fair usage, and protect backend services from overload, the gateway can enforce limits on the number of requests a client can make within a certain time frame. 4. Logging and Monitoring: Centralized logging of all api traffic provides invaluable insights into usage patterns, performance metrics, and potential errors, aiding in troubleshooting and operational intelligence. 5. Caching: The gateway can cache responses from backend services to reduce load and improve response times for frequently accessed data. 6. Load Balancing: It can distribute incoming traffic across multiple instances of backend services, enhancing fault tolerance and scalability. 7. Protocol Translation: It can translate between different protocols, for example, exposing a REST api even if a backend service uses gRPC.
In a hybrid architecture where GraphQL sits atop REST APIs, the api gateway plays an even more crucial role. The GraphQL server itself becomes one of the "backend services" that the gateway manages. The gateway can handle the initial authentication of the client before forwarding the GraphQL query to the GraphQL facade. It can also apply rate limiting to GraphQL queries, preventing malicious or excessively complex queries from overwhelming the system. Moreover, the gateway provides a unified point for observing the overall api health and traffic, encompassing both direct REST calls (if any are still exposed) and the GraphQL layer. This layered approach ensures that the GraphQL facade can focus solely on data orchestration and query resolution, while the api gateway handles the broader cross-cutting concerns of api management and security.
For organizations seeking a robust, open-source solution to manage their apis and even integrate AI models, platforms like APIPark offer an excellent example of an advanced api gateway and API management platform. APIPark is an all-in-one AI gateway and API developer portal, open-sourced under the Apache 2.0 license, designed specifically to help developers and enterprises manage, integrate, and deploy AI and REST services with ease. Its capabilities extend far beyond basic routing. For instance, APIPark offers quick integration of over 100 AI models and provides a unified API format for AI invocation, simplifying the use of complex AI services. In the context of our GraphQL-over-REST discussion, APIPark’s end-to-end API lifecycle management features are particularly valuable. It can assist with managing the design, publication, invocation, and decommissioning of both your underlying REST APIs and the GraphQL facade. The platform's ability to regulate api management processes, manage traffic forwarding, load balancing, and versioning of published APIs directly complements the strategy of building a flexible GraphQL layer. Furthermore, features like API service sharing within teams, independent apis and access permissions for each tenant, and subscription approval features ensure that api access is secure and well-governed. APIPark's impressive performance, rivaling Nginx with over 20,000 TPS on modest hardware, means it can handle large-scale traffic for even the most demanding GraphQL and REST workloads. Its detailed api call logging and powerful data analysis capabilities provide critical insights, helping businesses to monitor performance, trace issues, and perform preventive maintenance, which is vital for any sophisticated api architecture. Deploying APIPark is remarkably simple, achievable in just 5 minutes with a single command, making it an accessible yet powerful tool for enhancing api governance and security in a hybrid GraphQL/REST environment.
Leveraging OpenAPI (Swagger) for REST API Description and GraphQL Integration
The success of any API-driven architecture hinges on clear, precise, and up-to-date documentation. This is where OpenAPI Specification (formerly known as Swagger Specification) plays a pivotal role. OpenAPI is a language-agnostic, human-readable, and machine-readable interface description for RESTful APIs. It provides a standardized way to describe an api's operations, parameters, authentication methods, and data models. Think of it as a blueprint for your REST APIs, detailing every endpoint, the HTTP methods they support, the expected request bodies, and the structure of their responses. This comprehensive description serves multiple purposes: it acts as definitive documentation for developers consuming the api, enables the generation of client SDKs in various programming languages, facilitates automated testing, and even allows for the generation of interactive api consoles like Swagger UI. For teams heavily invested in REST, OpenAPI is an invaluable tool for maintaining clarity, consistency, and discoverability across their services.
The benefits of using OpenAPI extend significantly when considering the integration of GraphQL as a facade over existing REST APIs. The OpenAPI specification for your underlying REST services can serve as a rich source of truth for automatically or semi-automatically generating your GraphQL schema. Instead of manually transcribing every REST endpoint, parameter, and response field into GraphQL types, tooling can parse the OpenAPI definition and propose an initial GraphQL schema. For example, if your OpenAPI specification defines a User schema with fields id, name, and email returned by a GET /users/{id} endpoint, a generator can automatically create a type User { id: ID!, name: String, email: String } in your GraphQL schema. Similarly, OpenAPI's definitions for request parameters can inform the arguments for GraphQL queries and mutations. This automated generation process significantly reduces the manual effort and potential for human error involved in creating a GraphQL facade, accelerating the development cycle and ensuring a higher degree of consistency between your underlying REST APIs and their GraphQL representation.
Furthermore, OpenAPI can help in maintaining consistency and coherence across your hybrid api landscape. As your REST APIs evolve and their OpenAPI specifications are updated, these changes can be reflected in the GraphQL schema through regeneration or comparison tools. This ensures that the GraphQL layer always accurately represents the capabilities of the underlying REST services. While GraphQL has its own schema definition language, OpenAPI provides a robust, battle-tested standard specifically for describing REST. By leveraging OpenAPI to define the granular details of your RESTful resources, and then using GraphQL to provide a flexible query interface over those resources, you achieve a powerful synergy. The OpenAPI spec handles the "what is available" for individual REST resources, while the GraphQL schema handles the "how to compose and fetch what is needed" for clients. This combination allows developers to benefit from the strong documentation and tooling ecosystem of OpenAPI for their REST services, while simultaneously offering the client-side flexibility and efficiency of GraphQL for data consumption. This dual-layer approach represents a sophisticated strategy for managing complex api ecosystems, bridging traditional REST practices with modern data fetching paradigms.
APIPark is a high-performance AI gateway that allows you to securely access the most comprehensive LLM APIs globally on the APIPark platform, including OpenAI, Anthropic, Mistral, Llama2, Google Gemini, and more.Try APIPark now! 👇👇👇
Advanced Considerations and Best Practices for GraphQL-over-REST
Building a robust and performant GraphQL facade over existing REST APIs involves navigating several advanced considerations and adhering to best practices to ensure a seamless developer experience and efficient data flow. The architectural benefits are significant, but without careful planning and implementation, this layered approach can introduce its own set of complexities. Addressing these challenges proactively is crucial for the long-term success of such a hybrid api strategy.
Error Handling: In a GraphQL-over-REST setup, error handling becomes a more intricate process. When an underlying REST API call fails, the GraphQL resolver needs to gracefully catch that error, transform it into a GraphQL-compatible error format, and present it to the client. GraphQL errors typically follow a specific structure (e.g., errors array with message, path, and extensions fields). Resolvers must be designed to distinguish between network errors, application-specific REST errors (e.g., 404 Not Found, 400 Bad Request from the REST endpoint), and potential GraphQL execution errors. A common practice is to use custom error types in GraphQL and map specific REST error codes or messages to these types, providing clearer context to the client about what went wrong and where. This requires careful consideration of how much detail from the underlying REST error should be exposed to the GraphQL client without compromising security or leaking implementation details.
Performance Optimization: Caching and the N+1 Problem: Performance is paramount. As discussed, the N+1 problem, where a single GraphQL query translates into many individual REST calls, is a major performance bottleneck. Data Loaders are indispensable for addressing this. They work by batching multiple requests for the same type of resource into a single request and caching results within a single request context. Beyond Data Loaders, other caching strategies are essential. HTTP caching at the api gateway level (like with APIPark) can cache responses from the GraphQL server for repetitive queries. Within the GraphQL server, an in-memory cache or a distributed cache (e.g., Redis) can store the results of expensive REST calls. However, caching GraphQL responses can be tricky due to their dynamic nature; granular caching at the field level or using techniques like persisted queries are advanced strategies. Furthermore, optimizing the underlying REST APIs themselves, ensuring they are performant and offer options for efficient bulk retrieval, directly contributes to the GraphQL layer's speed.
Authentication and Authorization Across the Stack: Managing authentication and authorization across two layers (GraphQL and REST) requires a coherent strategy. Typically, the api gateway (e.g., APIPark) handles the initial authentication of the client, perhaps using JWTs or OAuth. Once authenticated, the gateway can forward the client's identity and permissions to the GraphQL server. The GraphQL server then uses this information within its resolvers to make authorized calls to the underlying REST APIs. This might involve forwarding the client's token or using an internal service-to-service token for secure communication between the GraphQL layer and the REST services. Authorization checks can happen at multiple points: at the api gateway (e.g., is this user allowed to access the GraphQL endpoint at all?), at the GraphQL schema level (e.g., directives restricting access to certain types or fields based on roles), and within individual REST API calls (e.g., the REST service ensuring the user has permissions for the specific resource being accessed). A consistent policy framework is essential to prevent security vulnerabilities.
Versioning Strategies: While GraphQL inherently handles schema evolution more gracefully than REST (clients only fetch what they ask for, so adding new fields rarely breaks existing clients), versioning still merits consideration. For the underlying REST APIs, traditional versioning (e.g., /v1/, /v2/) might still be in place. The GraphQL facade needs to be able to interact with different versions of these REST APIs if necessary, perhaps through different resolvers or by abstracting version differences within the resolver logic. For the GraphQL schema itself, a common practice is to evolve the schema by adding new fields and types, and deprecating old ones, rather than creating entirely new versions. The OpenAPI specification for your REST services can also aid in managing these versions, as the GraphQL schema generator can be configured to target specific REST API versions.
Monitoring and Analytics: Comprehensive monitoring is crucial. The api gateway (like APIPark) provides high-level traffic metrics, latency, and error rates for calls to the GraphQL endpoint. Within the GraphQL server, detailed logging of queries, execution times for resolvers, and specific REST calls made by each query provide granular insights. Tools exist to profile GraphQL queries, identifying slow resolvers or N+1 issues. Distributed tracing can link a single client GraphQL request through the GraphQL server to multiple underlying REST calls, providing an end-to-end view of request flow and latency, which is invaluable for debugging and performance optimization in a layered architecture. APIPark's detailed API call logging and powerful data analysis features are particularly beneficial here, offering insights into long-term trends and performance changes across your entire api landscape.
Tooling and Ecosystems: The GraphQL ecosystem is rich with tools that facilitate development and operation. GraphQL Playground or GraphiQL provide interactive query interfaces. Code generators can create client-side api calls based on your GraphQL schema. Tools exist to convert OpenAPI specifications to GraphQL schemas, and vice-versa, streamlining the integration process. Leveraging these tools can significantly enhance developer productivity and ensure the maintainability of your hybrid api architecture.
By meticulously addressing these advanced considerations, organizations can construct a GraphQL facade that not only provides a flexible and efficient api for clients but also maintains the robustness, security, and performance of the underlying REST services, transforming a complex integration into a powerful, unified data access layer.
Case Studies and Real-World Applications
The adoption of GraphQL as a facade over REST APIs is not merely a theoretical exercise but a pragmatic solution being embraced by a growing number of organizations to address real-world data access challenges. This architectural pattern particularly shines in scenarios involving complex data aggregation, microservices architectures, legacy system integration, and the development of versatile client applications. Understanding these use cases provides tangible evidence of the pattern's value and demonstrates its transformative potential.
One of the most compelling applications is in environments characterized by a microservices architecture. Modern applications are often composed of dozens, or even hundreds, of independent microservices, each exposing its own set of REST APIs. A single user interface might need to fetch data from a user service, an order service, a product catalog service, and a payment service to render a complete view. Without a GraphQL facade, the client would be forced to make numerous sequential or parallel REST requests to these disparate services, leading to increased latency, complex client-side data orchestration, and potential N+1 problems. By introducing a GraphQL layer, clients can send a single query to the GraphQL server, which then intelligently resolves the necessary data by calling the appropriate microservices. The GraphQL server acts as an aggregation point, abstracting away the complexity of the underlying microservices landscape and presenting a unified, client-friendly api. This significantly simplifies front-end development, as developers no longer need to know which microservice owns which piece of data; they simply query the unified GraphQL schema.
Another powerful use case is in dealing with legacy systems. Many enterprises operate with monolithic applications or older services that expose SOAP or REST APIs with rigid data structures that are difficult to modify. Rewriting these legacy systems to support modern data requirements is often prohibitively expensive and risky. A GraphQL facade offers a lifeline. It can sit in front of these legacy APIs, translating their fixed responses into a flexible GraphQL schema tailored for modern client applications. This allows organizations to modernize their client-facing apis without disrupting their stable, albeit dated, backend infrastructure. The GraphQL layer acts as an adapter, enabling a gradual evolution of the api ecosystem and extending the lifespan and utility of existing investments. This incremental modernization approach is critical for large enterprises.
Front-end developers are among the primary beneficiaries of this pattern. With GraphQL, they gain unprecedented control over data fetching. Instead of waiting for backend teams to create specific REST endpoints for their new UI requirements, they can simply modify their GraphQL queries. This drastically accelerates front-end development cycles, fosters greater autonomy, and allows for rapid iteration. For mobile applications, where network latency and bandwidth are critical concerns, GraphQL's ability to fetch only the required data in a single request leads to significantly faster load times and reduced data consumption, enhancing the user experience. Similarly, third-party integrations become simpler. Instead of exposing multiple, potentially complex REST APIs, a single, well-documented GraphQL endpoint can provide partners with a flexible way to consume data tailored to their specific needs. This reduces the burden of api documentation and support, as the GraphQL schema serves as a self-documenting contract.
For instance, consider an e-commerce platform. The product details page might require product information (from a product service), customer reviews (from a review service), and inventory levels (from an inventory service). A GraphQL query could fetch all this data in one go:
query ProductPageData($productId: ID!) {
product(id: $productId) {
name
description
price
reviews {
author
rating
comment
}
inventory {
inStock
quantity
}
}
}
The GraphQL server would resolve product by calling the product REST API, then resolve reviews by calling the review REST API with the productId, and similarly for inventory. This pattern consolidates multiple backend interactions into a single, efficient client request, showcasing the power of GraphQL as an aggregation and transformation layer. These real-world applications underscore that using GraphQL as a facade over REST is a mature, practical strategy for building performant, flexible, and developer-friendly apis in diverse and complex system landscapes.
Challenges and Mitigations in a Hybrid GraphQL/REST Architecture
While the benefits of using GraphQL as a facade over REST APIs are substantial, it's crucial to acknowledge and address the challenges inherent in this hybrid architectural approach. Adopting any new technology or pattern introduces complexities, and a layered api strategy is no exception. Understanding these potential pitfalls and developing effective mitigation strategies is key to ensuring a successful and sustainable implementation.
One of the most immediate challenges is the increased complexity of the overall system. You are essentially adding an additional layer between your clients and your backend services. This means there are now two layers to understand, develop, debug, and maintain: the GraphQL server and the underlying REST APIs. Developers need expertise in both GraphQL and REST, and the data flow between them can be more intricate to trace. A single GraphQL query might fan out to multiple REST calls, making it harder to pinpoint the exact source of a performance bottleneck or an error. * Mitigation: To combat this, comprehensive documentation, clear naming conventions, and robust monitoring tools are essential. Detailed logging at both the GraphQL layer (showing which resolvers were called and their execution times) and the api gateway (like APIPark, offering detailed api call logging) can help pinpoint issues. Distributed tracing tools that can correlate requests across services are invaluable for understanding the end-to-end flow. Investing in strong CI/CD pipelines for both layers ensures consistent deployment and testing.
Another challenge is the learning curve for GraphQL. While many developers are familiar with REST, GraphQL introduces new concepts: schema definition language, resolvers, mutations, subscriptions, and the declarative querying paradigm. Teams need to invest time in training and education to become proficient in GraphQL best practices and tooling. * Mitigation: Start with a pilot project or a small, non-critical api to gain experience. Provide clear examples, hands-on workshops, and access to GraphQL experts. Leverage existing GraphQL tooling like GraphiQL or GraphQL Playground for interactive exploration of the schema. Choose GraphQL libraries and frameworks that have good documentation and an active community.
The overhead of an additional layer can sometimes be a concern, particularly regarding latency. Each GraphQL query needs to be parsed, validated, and then resolved, which involves making HTTP requests to underlying REST APIs. This extra hop can potentially add a small amount of latency compared to direct REST calls. * Mitigation: This is where performance optimization techniques become critical. Data Loaders are indispensable for batching and caching REST requests, significantly reducing network overhead and mitigating the N+1 problem. Implementing intelligent caching strategies at the GraphQL server level, and leveraging an api gateway (such as APIPark) with its own caching and load balancing capabilities, can further reduce latency. Optimizing the performance of the underlying REST APIs themselves is also paramount, as a slow REST endpoint will always result in a slow GraphQL field. Carefully profiling the GraphQL server to identify slow resolvers and optimizing their data fetching logic is an ongoing task.
Complexity in security and authorization can also arise. Managing access control across both the GraphQL and REST layers requires careful design. How are user roles and permissions mapped and enforced? How are sensitive data fields protected? * Mitigation: Establish a clear security model from the outset. As discussed, the api gateway should handle initial authentication. The GraphQL server then receives authenticated user information and enforces authorization checks at the schema and field levels (e.g., using directives). For calls to underlying REST APIs, ensure that the GraphQL server makes requests with appropriate credentials, often using internal service-to-service tokens or forwarding the original client's token with necessary scope adjustments. This requires a strong understanding of your organization's security policies and meticulous implementation at each layer.
Finally, keeping the GraphQL schema in sync with evolving REST APIs can be a challenge. As REST endpoints change, new fields are added, or old ones are removed, the GraphQL schema must accurately reflect these changes to avoid inconsistencies or broken data contracts. * Mitigation: Leverage OpenAPI specifications as the source of truth for your REST APIs. Implement automated or semi-automated tools that can generate or update the GraphQL schema from these OpenAPI definitions. This helps reduce manual effort and ensures consistency. Implement rigorous testing, including contract testing between the GraphQL facade and the REST APIs, to catch breaking changes early in the development cycle. Adopting a culture of continuous integration and delivery (CI/CD) for both layers helps maintain alignment.
By thoughtfully addressing these challenges with robust technical solutions, clear architectural principles, and strong team collaboration, organizations can successfully implement a GraphQL facade over REST, realizing its full potential without being derailed by unforeseen complexities.
The Future of API Access: A Convergent Path
The journey from monolithic systems to microservices, and from rigid REST apis to flexible GraphQL facades, illustrates an ongoing evolution in how we design and consume digital services. The current landscape suggests not a battle between REST and GraphQL, but rather a convergence, where each technology plays a distinct yet complementary role in shaping the future of api access. REST will likely continue to serve as the backbone for many backend-to-backend communications, for simple resource-based interactions, and for external apis where a fixed, predictable contract is desired. Its simplicity, widespread tooling, and alignment with HTTP standards ensure its enduring relevance. However, for client-facing apis, particularly those supporting rich, dynamic user interfaces on diverse platforms, GraphQL is increasingly becoming the preferred choice due to its inherent flexibility and efficiency.
The trend is clear: data-driven architectures are becoming the norm. Applications are no longer just about CRUD operations on isolated resources; they are about aggregating, transforming, and presenting highly interconnected data from multiple sources in a way that is immediately consumable by the client. GraphQL excels precisely in this aggregation and orchestration role. It empowers clients to define their data graphs, shifting the complexity of data joining and filtering from the server-side to the client's query. This is particularly crucial in the era of accelerated development, where front-end teams need to iterate quickly on UI features without being constrained by backend api release cycles. The api that is most convenient and performant for the client will ultimately gain widespread adoption.
The future will likely see sophisticated api gateway platforms, such as APIPark, becoming even more integral to managing this hybrid api landscape. These gateways will evolve to offer native support for both REST and GraphQL, providing advanced features for query analysis, performance optimization for GraphQL (e.g., query complexity limiting), and unified security policies across all api types. They will serve as intelligent traffic managers, potentially even offering protocol translation layers that can expose an underlying REST api as a GraphQL endpoint, or vice versa, at the edge. The role of standards like OpenAPI will also continue to be critical, not just for documenting REST APIs but perhaps also for informing the generation of GraphQL schemas and facilitating interoperability between different api description formats.
This convergent path emphasizes the importance of developer experience (DX). An api that is easy to understand, well-documented, and provides predictable responses significantly enhances developer productivity. GraphQL, with its strong type system and interactive exploration tools, inherently offers a superior DX for data querying. When combined with the robust api management capabilities of platforms like APIPark, which provide features like centralized display of services, independent tenants, and approval workflows, the overall governance and usability of the entire api ecosystem are dramatically improved.
Ultimately, the goal is to provide flexible data access for diverse client applications. Whether it's a mobile app needing minimal data, a web dashboard requiring complex aggregations, or an IoT device pushing small telemetry updates, the api strategy must cater to these varied needs efficiently. GraphQL over REST provides a powerful mechanism to achieve this, allowing organizations to present a modern, highly adaptable api layer while preserving their existing investments. It's about building bridges between established architectures and emerging paradigms, ensuring that apis remain agile, scalable, and secure in an ever-evolving digital world. The future of api access is not about choosing one technology over another, but about intelligently combining them to create the most effective and developer-friendly data ecosystem possible.
Conclusion
The evolution of Application Programming Interfaces has brought us to a fascinating juncture where traditional RESTful architectures, the workhorses of the internet for decades, are being elegantly augmented by innovative paradigms like GraphQL. While REST has undeniably provided a robust and scalable foundation for countless digital services, its fixed resource model often struggles with the intricate and dynamic data requirements of modern client applications, leading to inefficiencies like over-fetching, under-fetching, and cumbersome versioning. This comprehensive exploration has demonstrated that rather than initiating a costly and disruptive overhaul, organizations can strategically deploy GraphQL as a sophisticated facade, seamlessly integrating with and enhancing their existing REST APIs.
By positioning a GraphQL server as an intelligent intermediary, developers gain the power to define a flexible, client-centric data api. This GraphQL layer translates precise client queries into efficient calls to disparate REST services, aggregating and shaping the data before delivering a single, tailored response. This approach not only addresses the inherent limitations of REST but also dramatically improves the developer experience, empowering front-end teams with unprecedented control over their data needs and accelerating iteration cycles. The benefits are profound: reduced network requests, optimized data transfer, simplified client-side logic, and a future-proof architecture capable of adapting to evolving application demands.
Central to the success of such a hybrid architecture is the indispensable role of an api gateway. Acting as the frontline for all api traffic, a robust api gateway centralizes critical functions such as authentication, authorization, rate limiting, and monitoring, offloading these cross-cutting concerns from individual services. Platforms like APIPark, an open-source AI gateway and API management platform, exemplify how a modern gateway can enhance security, manage traffic, and provide vital analytics for both REST and GraphQL endpoints, ensuring the stability and performance of the entire api ecosystem. Furthermore, leveraging standards like OpenAPI for describing underlying REST APIs proves invaluable, streamlining the generation of GraphQL schemas and maintaining consistency across the layered architecture.
While implementing a GraphQL facade over REST introduces challenges such as increased complexity, a learning curve, and performance considerations, these can be effectively mitigated through careful design, the use of powerful tools like Data Loaders for caching and batching, robust error handling, and comprehensive monitoring strategies. By embracing this convergent path, organizations can avoid the "either/or" dilemma, instead harnessing the strengths of both REST and GraphQL. This strategic integration fosters an environment of continuous api evolution, where existing investments are preserved, developer productivity is maximized, and flexible, efficient data access becomes the cornerstone of all digital interactions. The future of api access is indeed a harmonious blend, orchestrating diverse technologies to create seamless, powerful, and adaptable data experiences for a hyper-connected world.
Frequently Asked Questions (FAQs)
1. What are the main benefits of using GraphQL as a facade over existing REST APIs? The primary benefits include solving over-fetching and under-fetching data problems by allowing clients to request precisely what they need, leading to fewer network requests and faster load times. It also simplifies client-side development by providing a single, unified api endpoint that aggregates data from multiple REST services, abstracts away backend complexities, and offers a flexible schema that can evolve without breaking existing clients. This approach helps in modernizing api access without rewriting entire backend infrastructures, making it ideal for microservices and legacy system integration.
2. How does an API Gateway fit into a GraphQL-over-REST architecture? An api gateway acts as the single entry point for all client requests, sitting in front of the GraphQL facade. It handles crucial cross-cutting concerns like authentication, authorization, rate limiting, traffic routing, and monitoring before requests even reach the GraphQL server. For example, platforms like APIPark can authenticate clients, apply access policies to GraphQL queries, and then forward authorized requests to the GraphQL server. This offloads security and operational responsibilities from the GraphQL server, allowing it to focus purely on data orchestration and query resolution, while providing centralized control and observability for the entire api ecosystem.
3. What is the N+1 problem in this context, and how is it mitigated? The N+1 problem occurs when a single GraphQL query, intended to fetch a list of items and their associated details, results in "N" additional REST API calls for each item in the list, plus one initial call for the list itself. For instance, fetching 10 users and their posts might trigger 1 (for users) + 10 (for each user's posts) = 11 REST calls. This significantly impacts performance. It's mitigated primarily by using Data Loaders. Data Loaders batch multiple requests for similar resources into a single underlying REST call (e.g., fetching all posts for 10 user IDs in one go) and also cache results within a single request, drastically reducing the number of network round trips and improving efficiency.
4. Can OpenAPI specifications be used with GraphQL? Yes, OpenAPI specifications are highly beneficial when building a GraphQL facade over REST. They provide a machine-readable description of your existing REST APIs, including endpoints, parameters, and data models. This specification can be used by tools to automatically or semi-automatically generate the initial GraphQL schema, mapping REST resources to GraphQL types and operations. This process significantly reduces manual effort, accelerates development, and helps maintain consistency between the underlying REST apis and their GraphQL representation, ensuring that the GraphQL layer accurately reflects the capabilities of the backend.
5. Is it necessary to migrate entirely from REST to GraphQL, or can they coexist? They can absolutely coexist, and in most large enterprises, a hybrid approach is the most practical and beneficial. The strategy of using GraphQL as a facade over REST APIs explicitly promotes coexistence. REST can continue to serve its purpose for internal service-to-service communication, simpler resource interactions, and existing integrations. GraphQL, on the other hand, provides a modern, flexible, and efficient client-facing api layer. This allows organizations to leverage their existing investments in REST while gradually adopting GraphQL to meet evolving client needs, offering a phased modernization without the need for a "rip and replace" strategy.
🚀You can securely and efficiently call the OpenAI API on APIPark in just two steps:
Step 1: Deploy the APIPark AI gateway in 5 minutes.
APIPark is developed based on Golang, offering strong product performance and low development and maintenance costs. You can deploy APIPark with a single command line.
curl -sSO https://download.apipark.com/install/quick-start.sh; bash quick-start.sh

In my experience, you can see the successful deployment interface within 5 to 10 minutes. Then, you can log in to APIPark using your account.

Step 2: Call the OpenAI API.