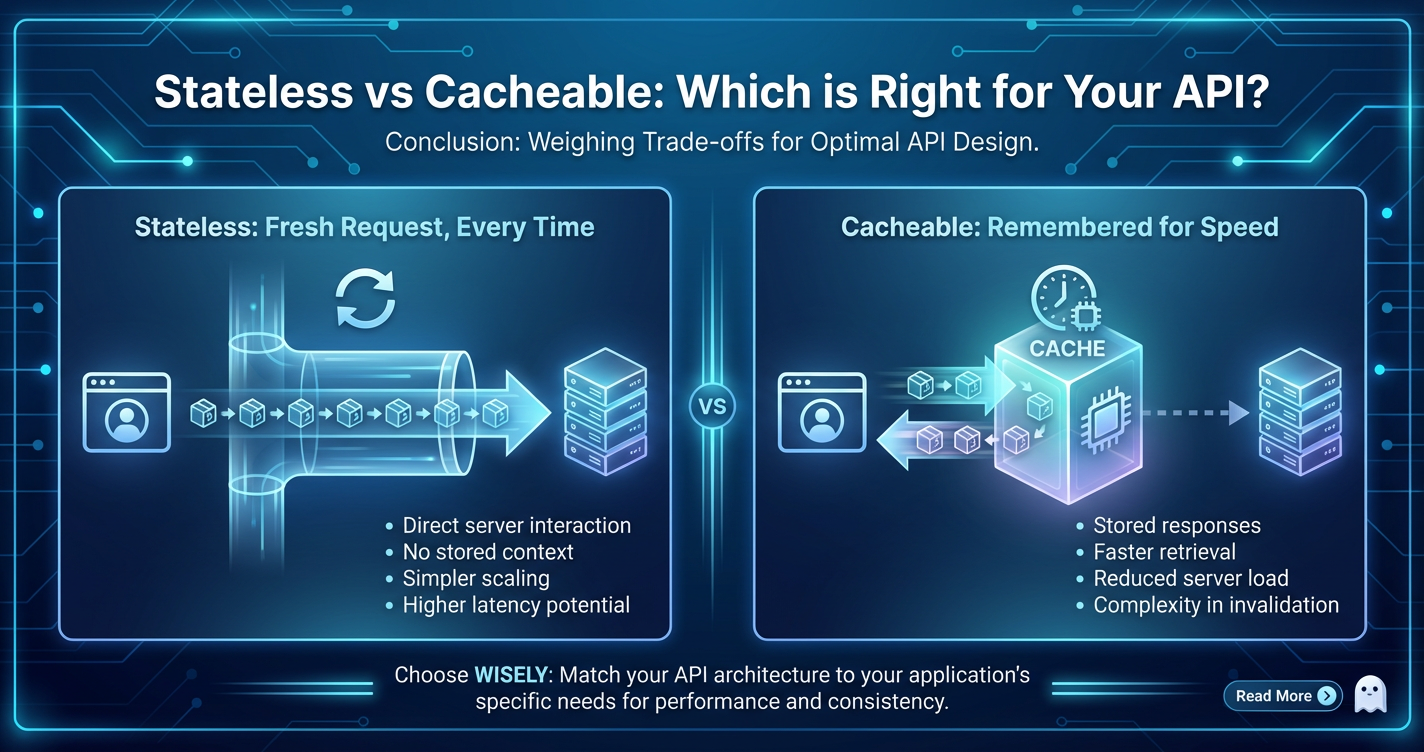
Stateless vs Cacheable: Which is Right for Your API?



The architecture of an API, at its core, revolves around fundamental design choices that profoundly impact its performance, scalability, and maintainability. Among the most pivotal of these decisions lies the distinction between stateless and cacheable designs. These two concepts, while seemingly disparate, are often intertwined and critical for constructing robust and efficient web services. Understanding their nuances is not merely an academic exercise but a practical necessity for any developer or architect aiming to build an API that can withstand the rigors of modern application demands.
This comprehensive exploration delves deep into the principles, advantages, disadvantages, and practical considerations of both stateless and cacheable APIs. We will meticulously dissect what each term signifies, how they are implemented, and, crucially, how to determine which approach, or combination thereof, is the optimal fit for your specific API's requirements. Moreover, we will examine the indispensable role of an API gateway in facilitating and optimizing both stateless interactions and efficient caching strategies, serving as the central nervous system for API traffic. By the end of this journey, you will possess a clearer framework for making informed architectural decisions that empower your APIs to be not just functional, but truly performant, scalable, and resilient.
Part 1: Unraveling the Core of Statelessness in APIs
Statelessness is a foundational principle, particularly in the realm of Representational State Transfer (REST) APIs, yet its implications extend far beyond mere compliance with a architectural style. To truly grasp its essence is to understand how a server interacts with its clients and the profound impact this interaction model has on the overall system architecture.
1.1 Defining Statelessness: A Server Without Memory
At its heart, a stateless API signifies that each request from a client to the server must contain all the necessary information for the server to understand and fulfill that request. The server itself holds no client context between requests. It treats every single request as if it were the first and only request ever made by that client. There is no server-side "session" that tracks a client's progression through a series of interactions.
Imagine a conversation where every sentence you utter is entirely self-contained, requiring no prior knowledge of what was said before. This is akin to a stateless interaction. If a client needs to perform a sequence of operations, it is solely responsible for managing and presenting the required state information with each subsequent request. This could include authentication tokens, pagination parameters, or identifiers for resources created in previous steps. The server processes the request, sends back a response, and then immediately "forgets" everything about that particular interaction, eagerly awaiting the next fully independent request.
This design philosophy starkly contrasts with stateful architectures, where the server maintains session data for each client, often stored in memory or a database, allowing subsequent requests to implicitly refer to this established context. While stateful systems can simplify client-side logic by offloading state management to the server, they introduce significant complexities for scaling and reliability, which we will explore further.
1.2 The Guiding Principles of Stateless Design
Statelessness in API design is not just a feature; it's an architectural constraint that brings with it several important guiding principles:
- Self-Contained Requests: Every request must be complete and unambiguous. It must include all data needed for the server to process it without relying on any previous server-side context. This typically means including authentication credentials (e.g., JWT, API keys), identifiers for resources, and any other relevant parameters directly within the request headers, body, or URL.
- Idempotency (for certain operations): While not exclusively a stateless concept, idempotency is often easier to achieve and manage in stateless systems. An idempotent operation is one that, when executed multiple times with the same parameters, produces the same result (or no further change to the system's state). GET, PUT, and DELETE are typically idempotent, while POST is generally not. Statelessness simplifies the guarantee that repeated requests won't inadvertently alter state based on implicit server context.
- Resource-Oriented Design: Stateless APIs are typically resource-oriented, meaning they expose resources that can be manipulated through standard HTTP methods (GET, POST, PUT, DELETE, PATCH). The focus is on the state of the resources, not the state of the client's interaction with the server.
1.3 The Compelling Advantages of a Stateless API
Embracing statelessness offers a multitude of benefits that are particularly pertinent in today's distributed and cloud-native environments:
- Exceptional Scalability: This is arguably the most significant advantage. Since the server retains no client-specific state, any server instance can handle any client request at any time. This dramatically simplifies horizontal scaling. You can add or remove server instances dynamically based on demand without worrying about session affinity (i.e., ensuring a client's requests always hit the same server where its session data resides). Load balancers can distribute incoming requests across available servers indiscriminately, maximizing resource utilization.
- Enhanced Reliability and Fault Tolerance: If a server instance fails, it doesn't result in lost client sessions or data. Clients can simply retry their request, and a different healthy server instance can seamlessly pick it up. There's no complex session replication or recovery mechanism required, making the overall system more resilient to individual component failures. This simplifies operational procedures and reduces downtime.
- Simplified Server-Side Design and Implementation: Developers don't need to implement complex session management logic on the server. This reduces the cognitive load, the amount of code to write, and the potential for bugs related to state consistency or expiration. The server's role becomes primarily about processing individual requests, which can lead to cleaner, more focused codebases.
- Optimized for Distributed Systems and Microservices: Statelessness is a natural fit for microservices architectures. Each microservice can operate independently, without needing to share session state with other services. This promotes loose coupling, easier deployment, and independent scaling of individual services, which are hallmarks of a robust distributed system.
- Simplified Load Balancing: As mentioned earlier, any server can handle any request. This means standard, simple load balancing algorithms (like round-robin or least connections) can be employed without needing Sticky Sessions, which can introduce their own scaling bottlenecks and complexities. The
api gatewayor load balancer merely needs to forward the request to an available backend instance.
1.4 Navigating the Disadvantages and Challenges
While powerful, statelessness isn't a silver bullet and comes with its own set of trade-offs and challenges:
- Increased Request Size and Bandwidth Usage: Since every request must carry all necessary information, requests can become larger, especially if extensive authentication tokens or contextual data need to be sent repeatedly. Over a long series of interactions, this can lead to increased network bandwidth consumption and slightly higher latency due to larger payload transfers.
- Potential Performance Overhead on the Server: Each request often requires re-processing of authentication and authorization tokens. While this can be mitigated by efficient token validation mechanisms, it still represents a recurring computational cost that a stateful system might avoid by having authenticated a session once.
- Client-Side State Management Responsibility: The burden of maintaining session state shifts entirely to the client. This means client applications (web browsers, mobile apps, desktop clients) must be designed to store, retrieve, and correctly send state information with each request. This can sometimes add complexity to client development, particularly for intricate multi-step workflows. If the client fails to manage state correctly, the API interactions will fail.
- Complexity for Long-Running Transactions: For workflows that require multiple steps and depend heavily on the outcome of previous steps (e.g., a multi-page form submission), managing this state purely on the client side can become cumbersome. Developers might need to resort to hidden fields, local storage, or sophisticated client-side routing to maintain the illusion of a server-side session.
1.5 Practical Implementation Details
Implementing a stateless API effectively requires careful consideration of how state is managed and communicated:
- Authentication and Authorization:
- JSON Web Tokens (JWTs): A highly popular method where the server issues a digitally signed token to the client after successful authentication. The client then includes this JWT in the
Authorizationheader of every subsequent request. The server can validate the token's signature and payload without needing to consult a database, making it inherently stateless. - API Keys: A simpler approach for machine-to-machine communication, where a secret key is sent with each request, often in a header.
- OAuth 2.0 Tokens: Provides a secure delegated authorization framework, where access tokens are used by clients to access protected resources on behalf of a user. The access tokens themselves are typically stateless from the resource server's perspective, which merely validates them.
- JSON Web Tokens (JWTs): A highly popular method where the server issues a digitally signed token to the client after successful authentication. The client then includes this JWT in the
- Session Management (Client-side):
- Local Storage/Session Storage: Web applications can store simple state data in the browser's local or session storage.
- Cookies: Can store small pieces of information, though their use should be limited for security reasons and to avoid "cookie hell" in stateless APIs where explicit header-based tokens are preferred.
- URL Parameters/Headers: Directly passing identifiers or flags within the request.
- Context Passing: All necessary context, such as user preferences, language settings, or pagination details, should be passed through request headers, query parameters, or the request body. For example,
Accept-Languageheader for language preference,pageandlimitquery parameters for pagination.
A well-designed stateless API offers tremendous advantages in terms of scalability and resilience, making it a cornerstone of modern web application development, especially when dealing with a high volume of api calls. The complexities it introduces are often manageable with established patterns and tools, reinforcing its status as a preferred architectural choice.
Part 2: Embracing Cacheability in APIs
While statelessness defines how a server processes individual requests, cacheability dictates whether and how those requests and their responses can be stored and reused to avoid redundant computations and network transfers. It's a fundamental optimization strategy for improving performance and reducing server load, especially crucial for APIs that serve frequently accessed data.
2.1 Defining Cacheability: Storing for Future Use
Cacheability refers to an API's ability to allow its responses to be stored by an intermediary (like a proxy server or an api gateway) or the client itself, so that subsequent, identical requests can be served from this stored copy rather than forcing a fresh computation and data retrieval from the origin server. The core idea is to move data closer to the consumer and avoid repeated work.
When an API response is deemed cacheable, it means that the information contained within that response is unlikely to change immediately, or that the system is willing to accept a slight delay in data freshness for significant performance gains. HTTP, the ubiquitous protocol for web APIs, provides rich mechanisms, primarily through specific headers, to signal an API response's cacheability and to control how long it should be considered valid.
The goal of caching is to make data access faster and more efficient. Instead of traversing the entire path to the origin server, which involves network latency, server processing, and database lookups, a request can often be served in milliseconds from a local cache.
2.2 The Principles of Effective Caching
Effective caching isn't just about storing data; it's about doing so intelligently and with awareness of data freshness:
- HTTP Caching Headers: The backbone of web caching. Headers like
Cache-Control,Expires,ETag, andLast-Modifiedprovide explicit instructions to clients and intermediaries on how to cache a response. - Idempotency and Method Safety: Caching is almost exclusively applied to "safe" methods like
GETandHEAD, which retrieve data and are not intended to change server state. CachingPOST,PUT, orDELETEresponses is generally discouraged and rarely useful, as these methods modify state and their responses are often unique or confirmative of a state change. - Varying Responses: An API response might differ based on various request headers (e.g.,
Accept-Language,Accept-Encoding). TheVaryheader informs caches that they should store separate versions of a response for different values of these headers. - Cache Invalidation: The most challenging aspect. Caches must be invalidated (or updated) when the underlying data changes to prevent serving stale information. This can be time-based, event-driven, or explicitly purged.
2.3 Diverse Types of Caching in API Architectures
Caching can occur at various layers within an API's request-response cycle, each with its own advantages and use cases:
- Client-Side Caching:
- Browser Cache: Web browsers automatically cache responses based on HTTP headers. This is the first line of defense for web applications.
- Application Cache: Mobile applications or desktop clients might implement their own in-memory or on-disk caches to store frequently accessed data.
- Proxy Caching / Gateway Caching:
- Reverse Proxies and Load Balancers: Servers like Nginx or Varnish Cache sit in front of the origin API servers and can cache responses. They serve as a shared cache for multiple clients. An
api gatewayoften incorporates this functionality, providing centralized control over caching policies. - CDNs (Content Delivery Networks): Geographically distributed networks of proxy servers that cache static and dynamic content, bringing it physically closer to end-users to reduce latency and origin server load.
- Reverse Proxies and Load Balancers: Servers like Nginx or Varnish Cache sit in front of the origin API servers and can cache responses. They serve as a shared cache for multiple clients. An
- Server-Side Caching (Backend Caching):
- In-Memory Cache: Application servers can cache frequently computed results or database queries directly in their RAM.
- Distributed Caches: Dedicated caching systems like Redis or Memcached store data across multiple servers, providing a scalable and highly available caching layer that can be shared by multiple API instances. This is common in microservices architectures.
- Database Caching: Some databases have internal caching mechanisms for queries or frequently accessed data.
2.4 The Undeniable Advantages of Cacheability
Integrating caching into your API design offers a suite of compelling benefits:
- Dramatic Performance Improvement: By serving responses from a cache, the need to execute business logic, query databases, and transfer data over long network distances is eliminated or significantly reduced. This translates directly to lower latency and faster response times for clients, leading to a much smoother and more responsive user experience. For APIs under heavy load, this can be the difference between a sluggish and a lightning-fast application.
- Substantial Reduction in Server Load: Every cache hit means one less request reaching the origin API servers. This frees up CPU cycles, memory, and database connections on your backend, allowing them to handle truly unique or uncached requests more efficiently. This is critical for scaling an API without needing to constantly provision more backend resources. During peak traffic, caching can prevent servers from being overwhelmed.
- Lower Network Bandwidth Usage: When responses are served from client-side caches or nearby proxy caches (like a CDN), less data needs to travel across the wider internet. This can reduce operational costs associated with bandwidth and improve the overall network efficiency for both the API provider and consumers.
- Improved User Experience: Faster responses directly contribute to a better user experience. Applications feel snappier, less waiting time leads to higher user satisfaction and engagement. For mobile applications, caching can also mean continued functionality even with intermittent network connectivity.
- Increased Availability and Resilience: In some scenarios, if the origin API server becomes temporarily unavailable, a cache can continue to serve stale, but still useful, data to clients, providing a level of resilience. This "stale-while-revalidate" pattern is a sophisticated caching strategy that trades absolute freshness for availability.
2.5 The Complexities and Disadvantages of Caching
While highly beneficial, caching introduces its own set of significant challenges:
- The Cache Invalidation Problem: Often cited as one of the two hardest problems in computer science, ensuring caches are invalidated (updated) when the underlying data changes is notoriously difficult. If not handled correctly, clients receive stale data, leading to incorrect application behavior, user confusion, or even critical business errors. Strategies include time-based expiration, event-driven invalidation (e.g., publishing a message to a queue when data changes), or explicit cache purging APIs.
- Increased System Complexity: Implementing and managing a robust caching strategy adds layers of complexity to the system. Developers must decide what to cache, where to cache it, for how long, and how to invalidate it. This often involves new components (e.g., Redis clusters, Varnish servers), monitoring tools, and deployment considerations.
- Data Consistency Issues: In distributed systems, maintaining consistency across multiple cache instances and the origin data store is a non-trivial task. Race conditions, eventual consistency models, and cache coherency protocols become important considerations. Strict consistency often comes at the cost of performance or availability.
- Security Concerns: Caching sensitive or personalized data incorrectly can lead to security vulnerabilities. For instance, if an API response containing private user data is cached publicly, it could be exposed to other users. Careful attention must be paid to
Cache-Controldirectives likeprivateorno-storefor such data. Cache poisoning attacks, where malicious data is injected into a cache, are also a concern. - Cache Warming: For new cache instances or after a full cache purge, the cache will be "cold," meaning it has no data. The first few requests for cached resources will still hit the origin server, potentially causing a temporary spike in load until the cache is "warmed up."
2.6 Key Implementation Aspects for Cacheable APIs
Successfully implementing cacheability requires a strategic approach:
- Leveraging HTTP Caching Headers:
Cache-Control: The most powerful header. Directives likemax-age=<seconds>(how long a response is fresh),public(can be cached by any cache),private(only client browser can cache),no-cache(must revalidate with origin),no-store(never cache sensitive data),s-maxage(for shared caches).Expires: An older header (HTTP/1.0) indicating an absolute expiry date/time.Cache-Controlgenerally takes precedence.ETag: An opaque identifier (a "tag") assigned by the server to a specific version of a resource. Clients sendIf-None-Matchwith theETag. If theETagmatches, the server responds with 304 Not Modified, saving bandwidth.Last-Modified: The date and time the resource was last modified. Clients sendIf-Modified-Since. If the resource hasn't changed, the server responds with 304.Vary: Instructs caches that the response is based on specific request headers. E.g.,Vary: Accept-Encodingmeans caches should store different versions for Gzip and non-Gzip requests.
- Cache-Busting Strategies: To force clients or proxies to fetch a fresh version, techniques include:
- Versioning URLs:
/v2/usersor/users?v=20231027. - Appending query parameters with timestamps or hash values (e.g.,
resource.js?v=12345).
- Versioning URLs:
- Invalidation Mechanisms:
- Time-based Expiration: The simplest; rely on
max-ageorExpires. Data will be stale for some duration. - Event-driven/Programmatic Invalidation: When data changes in the database, a message is published to an event bus, triggering cache eviction for the affected keys. This offers stronger consistency but is more complex to implement.
- Cache Purging APIs:
api gateways or CDN services often provide APIs to explicitly purge specific cached items or entire cache regions.
- Time-based Expiration: The simplest; rely on
Caching, when applied judiciously, can transform the performance profile of an API, making it more responsive and resilient under heavy loads. However, it demands a careful architectural approach, particularly concerning data freshness and consistency. The careful balance between serving fresh data and leveraging cached responses is a continuous challenge that defines the maturity of an API architecture.
Part 3: The Interplay and Decision-Making: Statelessness Meets Cacheability
The concepts of statelessness and cacheability, while distinct, are profoundly interconnected in the grand scheme of API design. A robust API often leverages both, ensuring that the underlying architecture is scalable and that performance is optimized through intelligent data reuse. The decision to prioritize one over the other, or to combine them, depends heavily on the specific use cases, data characteristics, and performance requirements of your API.
3.1 Statelessness as a Prerequisite for Effective Cacheability
It's crucial to understand that statelessness often provides a foundational layer upon which effective caching can be built. Here's why:
- Predictable Responses: In a stateless API, given the same request (headers, URL, body), the server will consistently produce the same response (assuming the underlying resource hasn't changed). This predictability is essential for caching. If responses varied based on some hidden server-side session state, caching would be unreliable, as a cached response for one client's "session" might be incorrect for another.
- Simplified Cache Key Generation: Because all necessary context is within the request itself, generating a unique cache key (e.g., a hash of the URL and relevant headers) is straightforward. This allows caches to accurately identify when a request can be served from a stored response.
- Scalable Caching Layers: Stateless APIs inherently support load balancing across multiple backend servers. Similarly, caching layers (like distributed caches or
api gateways) can also be scaled horizontally without worrying about session affinity, as the cache entry itself is tied to the request, not a specific client-server session.
While it's theoretically possible to cache parts of a stateful API, it introduces significant complexity in managing cache keys that incorporate session identifiers and ensuring that cached data doesn't accidentally reveal one user's session data to another. Therefore, a stateless design is almost always the preferred prerequisite for maximizing the benefits of caching.
3.2 When to Prioritize Statelessness
There are specific scenarios where the stateless principle should be rigorously adhered to, and caching might be either inappropriate or limited:
- High-Write or Transactional APIs: APIs that involve creating, updating, or deleting resources (
POST,PUT,PATCH,DELETEmethods) are inherently changing server state. Caching their responses is generally counterproductive, as the response is often a confirmation of the change, and subsequent identical requests (though not strictly idempotent for POST) would likely yield different results or be considered distinct operations. For example, anapifor placing an order should always hit the backend to ensure the transaction is processed uniquely. - APIs Handling Sensitive or Highly Personalized Data: User-specific profiles, financial transactions, private messages, or any data that should never be inadvertently exposed to another user are poor candidates for broad caching, especially in shared caches. While client-side private caching might be acceptable with strict controls, the risk of stale data revealing old sensitive information or caching infrastructure exposing private data often outweighs the performance benefits.
Cache-Control: no-storeis paramount here. - Dynamic and Real-Time Content: APIs that deliver constantly changing data, such as real-time stock quotes, live sports scores, sensor readings, or chat messages, derive their value from freshness. Any delay introduced by caching, even for a short duration, can diminish their utility. In these cases, it's critical to ensure requests bypass caches or have extremely short cache durations.
- Operations with Side Effects: Any
apicall that triggers non-idempotent actions, like sending an email, initiating a background job, or charging a credit card, must always be processed by the origin server. Caching such responses would prevent these critical side effects from occurring.
3.3 When to Prioritize Cacheability (or Combine with Statelessness)
Conversely, caching becomes a primary optimization for different types of API interactions:
- Read-Heavy APIs with Infrequently Changing Data: The quintessential use case for caching. APIs that primarily serve data via
GETrequests, and where that data doesn't change often (e.g., product catalogs, news articles, public configuration data, user lists in a directory), are ideal candidates. The performance gains from serving cached responses repeatedly are enormous. - Public APIs with High Traffic Volume: If your
apiis exposed publicly and experiences a massive volume of identical requests for certain resources, caching is a non-negotiable strategy. It significantly reduces the load on your origin servers and improves response times for a large user base. This is where CDNs andapi gateways with caching capabilities shine. - Static or Semi-Static Content APIs: APIs that serve static assets (images, CSS, JavaScript) or data that is updated on a predictable, infrequent schedule (e.g., daily reports, weekly summaries). Long cache durations are perfectly acceptable here.
- Data Aggregation or Computationally Intensive Results: If an API endpoint aggregates data from multiple sources or performs complex calculations, and the input parameters (and thus the output) remain consistent for a period, caching the result avoids repeating expensive computations for every request.
3.4 Hybrid Approaches: Leveraging Both Strengths
Most real-world API architectures adopt a hybrid strategy, combining stateless design principles with intelligent caching layers. This allows developers to gain the scalability and resilience of stateless services while simultaneously benefiting from the performance and load reduction of caching.
- Stateless Core Logic with a Caching Layer: The backend API service itself remains stateless. It processes each request without retaining client context. However, a caching layer (e.g., a distributed cache like Redis, or an
api gateway's cache) sits in front of it. When a request comes in, the caching layer first checks if it has a valid, fresh response. If yes, it serves it immediately. If not, it forwards the request to the stateless backend, caches the response, and then returns it to the client. This decouples the caching logic from the core business logic. - Endpoint-Specific Caching Policies: Not all endpoints within the same API need the same caching strategy. An
api gatewayor application logic can apply differentCache-Controlheaders and caching policies based on the specific endpoint, HTTP method, or even parameters within the request. For example,GET /productsmight be highly cacheable, whileGET /users/{id}/orders(private data) might be cached only client-side or not at all. - Client-Side and Server-Side Caching Integration: A well-architected system leverages caching at multiple levels. Browsers cache resources with short
max-age. Anapi gatewaycaches commonly accessed public data with longermax-ageand usesETagfor revalidation. Backend services use in-memory or distributed caches for frequently queried database results. This multi-layered approach maximizes cache hits and reduces load.
3.5 The Indispensable Role of an API Gateway
An api gateway serves as a critical component in managing both stateless and cacheable API interactions. It acts as a single entry point for all API requests, providing a centralized control plane for crucial cross-cutting concerns.
- Centralized Authentication and Authorization: An
api gatewaycan enforce authentication and authorization policies for all incoming requests before they even reach the backend services. It can validate JWTs, API keys, or OAuth tokens, and apply fine-grained access controls. This offloads authentication logic from individual backend services, keeping them truly stateless and focused on business logic. Thegatewayensures that only authorized, correctly formed stateless requests proceed. - Request Routing and Load Balancing: For stateless backend services, an
api gatewayefficiently routes requests to available instances, often employing intelligent load balancing algorithms. Since services are stateless, any instance can handle any request, simplifying thegateway's task and improving overall service availability and scalability. - API Gateway Caching: Many
api gateways offer built-in caching capabilities. They can cache responses at thegatewaylevel, acting as a shared cache for all clients. This is incredibly powerful for reducing the load on backend services and improving response times, especially for read-heavy public APIs. Thegatewaycan interpretCache-Controlheaders from the backend or override them with its own policies. This external caching layer allows backend services to remain stateless and simple, while thegatewayhandles the complexities of cache management. - Rate Limiting and Throttling: The
api gatewayis the ideal place to implement rate limiting and throttling policies, protecting backend services from abuse or overload, regardless of whether the requests are cached or not. - API Lifecycle Management: Beyond runtime operations, an
api gatewayoften plays a role in the broader API lifecycle, from design and publication to versioning and monitoring. A comprehensive platform like ApiPark is an excellent example of an open-sourceAI gatewayandAPI management platformthat helps developers and enterprises manage, integrate, and deploy AI and REST services with ease. APIPark facilitates end-to-end API lifecycle management, including traffic forwarding, load balancing, and versioning of published APIs, making it a powerful tool for controlling how both stateless and cacheable APIs are exposed and consumed. Its ability to offer performance rivaling Nginx (achieving over 20,000 TPS with modest resources) underscores the importance of a high-performancegatewayin handling large-scale traffic for both stateless and cached requests. - Unified API Format and AI Integration: APIPark further extends the
gateway's role by standardizing the request data format across various AI models and even allowing prompt encapsulation into REST API. This standardization simplifies AI usage, making the integration of AI models more consistent and predictable for developers, implicitly aiding in applying consistent caching strategies or ensuring stateless interactions with diverse AI services.
The api gateway acts as a crucial orchestrator, abstracting away much of the complexity of managing a fleet of stateless services and intelligently applying caching strategies to optimize performance without burdening individual microservices.
APIPark is a high-performance AI gateway that allows you to securely access the most comprehensive LLM APIs globally on the APIPark platform, including OpenAI, Anthropic, Mistral, Llama2, Google Gemini, and more.Try APIPark now! 👇👇👇
Part 4: Deep Dive into Advanced Considerations
Beyond the fundamental principles, designing and operating stateless and cacheable APIs in a production environment involves several advanced considerations related to security, observability, and scalability patterns. These aspects ensure that the chosen architectural approach not only functions correctly but also remains robust, secure, and maintainable over its lifecycle.
4.1 Security Implications: Protecting Your API
Security is paramount for any API, and the choices between stateless and cacheable designs introduce distinct considerations.
- Stateless APIs and Token Security:
- JWT Revocation: In a truly stateless system using JWTs, tokens are valid until their expiration. There's no server-side session to "log out" or revoke. If a token is compromised, an attacker can use it until it expires. Strategies to mitigate this include:
- Short Expiry Times: Issue JWTs with very short lifespans (e.g., 5-15 minutes).
- Refresh Tokens: Use longer-lived refresh tokens (kept secure) to obtain new short-lived access tokens. If a refresh token is compromised, it can be added to a server-side blacklist.
- Blacklisting/Revocation List: While it introduces a stateful element, maintaining a small blacklist of compromised JWTs can enhance security for critical applications. This list is typically managed by the
api gatewayor an authorization service.
- Token Storage on Client: Clients are responsible for securely storing tokens (e.g., in
HttpOnlycookies, local storage, or secure storage for mobile apps). Vulnerabilities on the client side can compromise tokens. - Signature Verification: The
api gatewayor backend must robustly verify the digital signature of JWTs to prevent tampering. Any deviation should result in immediate rejection. - API Key Management: For API keys, ensure they are transmitted securely (HTTPS), are revocable, and have appropriate access control policies tied to them.
- JWT Revocation: In a truly stateless system using JWTs, tokens are valid until their expiration. There's no server-side session to "log out" or revoke. If a token is compromised, an attacker can use it until it expires. Strategies to mitigate this include:
- Cacheable APIs and Data Protection:
- Preventing Sensitive Data Caching: The most critical concern. Never cache responses containing sensitive user data (e.g., financial info, PII) in public or shared caches. Use
Cache-Control: private(client can cache, but not shared proxies) orCache-Control: no-store(never cache anywhere) for such responses. Theapi gatewayshould enforce these headers if the backend fails to. - Cache Poisoning: An attacker injects malicious data into a shared cache, which is then served to legitimate users. This can happen through crafted request headers or parameters that influence the cached response. Mitigation involves:
- Careful use of
Varyheader to ensure different responses are cached for different header values. - Sanitizing input to prevent malicious content from being cached.
- Ensuring
api gateways properly validate requests before caching.
- Careful use of
- Stale Data Exposure: If cache invalidation fails or is delayed, stale sensitive data might be served. While usually a consistency issue, in some contexts, serving outdated data (e.g., an old user status that should have been revoked) could have security implications.
- CORS and Origin Control: Ensure proper Cross-Origin Resource Sharing (CORS) policies are in place to control which domains can access your API, particularly when caching is involved and resource origins might be obscured.
- Preventing Sensitive Data Caching: The most critical concern. Never cache responses containing sensitive user data (e.g., financial info, PII) in public or shared caches. Use
4.2 Observability and Monitoring: Seeing Inside Your API
Understanding how your API performs and behaves in production is crucial. Both statelessness and cacheability influence observability strategies.
- Monitoring Stateless API Behavior:
- Request Tracing: Since each request is independent, distributed tracing (e.g., using OpenTelemetry or Zipkin) is essential to follow a single request's journey across multiple microservices and identify bottlenecks.
- Logging: Comprehensive request/response logging provides crucial insights. ApiPark offers detailed API call logging, recording every detail of each
apicall. This feature is invaluable for businesses to quickly trace and troubleshoot issues in API calls, ensuring system stability and data security. For stateless services, logging must capture sufficient context within each entry to allow for independent analysis without relying on session correlation. - Metrics: Monitor standard API metrics: request rates, error rates, latency, and resource utilization (CPU, memory) per service instance. Since services scale horizontally, aggregate metrics are vital.
- Monitoring Cache Performance:
- Cache Hit Ratio: The most important metric for caching. It tells you the percentage of requests served from the cache versus those that hit the origin server. A high hit ratio indicates effective caching.
- Cache Miss Rate: The inverse of hit ratio, indicating how many requests had to go to the origin.
- Cache Latency: Measure the time taken to serve a request from the cache versus from the origin.
- Cache Size and Eviction Policies: Monitor how much data is in the cache, how quickly it fills up, and whether eviction policies are working as expected.
- Stale Data Alerts: Implement monitoring to detect and alert on instances where stale data might be served for longer than acceptable thresholds.
- Origin Server Load Reduction: Correlate cache hit rates with reduced load on backend API servers (e.g., lower CPU, fewer database queries).
ApiPark provides powerful data analysis capabilities, analyzing historical call data to display long-term trends and performance changes. This helps businesses with preventive maintenance before issues occur, a feature highly relevant to both general API performance and the specific metrics related to cache effectiveness and overall system health.
4.3 Scalability Patterns and Modern Architectures
The architectural choices between stateless and cacheable profoundly influence how APIs integrate with modern scaling patterns.
- Stateless Services and Cloud-Native:
- Containerization: Stateless APIs are perfectly suited for containerization (Docker, Kubernetes). Containers can be spun up and down rapidly, scaled horizontally, and easily managed by orchestrators.
- Serverless Functions: Serverless platforms (AWS Lambda, Azure Functions) inherently enforce statelessness per invocation. This makes them ideal for implementing stateless API endpoints that scale automatically without server management.
- Service Meshes: In complex microservices environments, a service mesh (Istio, Linkerd) can manage traffic, enforce policies, and collect telemetry for stateless services, further enhancing their scalability and resilience.
- Database Scaling: Statelessness helps scale the application layer, but the database can become a bottleneck. Strategies like sharding, read replicas, and eventual consistency models become vital for scaling the data store backing stateless services.
- Cacheable Services and Distributed Caching:
- Distributed Caching Systems: For significant caching needs, dedicated distributed caches like Redis Cluster, Memcached, or Apache Ignite are essential. These systems are designed for high throughput, low latency, and horizontal scalability, storing cached data across multiple nodes.
- Global Caching with CDNs: For geographically dispersed users, Content Delivery Networks (CDNs) provide global caching at the edge, reducing latency by serving content from servers closer to the user. This is particularly effective for static content or highly cacheable API responses.
- Cache-Aside vs. Read-Through/Write-Through: Different caching patterns for interacting with the cache and the origin data source, each with trade-offs in complexity, consistency, and performance.
Cache-aside(application manages cache reads and writes) is common for its flexibility.
4.4 Evolution of API Design: Beyond REST
While the discussion primarily centers on REST, other API paradigms also interact with statelessness and cacheability.
- GraphQL: GraphQL APIs, while often built on stateless HTTP, introduce different caching considerations. Since clients can request exactly what data they need, traditional HTTP caching (based on full URI matching) is less effective for GraphQL queries. Instead, clients often implement their own normalized caches (e.g., Apollo Client's cache) that store data by ID and update it based on query and mutation responses. The
api gatewaymight cache specific GraphQL query results, but the dynamic nature of queries requires more sophisticated caching. - Event-Driven APIs: In event-driven architectures (e.g., using Kafka or RabbitMQ), APIs might expose endpoints to publish events or subscribe to event streams. These are often inherently stateless (publishing an event is a one-time action) but their responses (e.g., confirmation of event receipt) are not typically cached in the traditional sense. The focus shifts to event durability and processing guarantees.
The ongoing evolution of API design continually presents new challenges and opportunities for applying these fundamental architectural principles. Regardless of the specific technology stack or API style, a deep understanding of statelessness and cacheability remains a cornerstone for building performant, scalable, and secure API ecosystems.
Part 5: Practical Guide and Best Practices
Having delved into the theoretical underpinnings and advanced considerations, it's time to consolidate this knowledge into a practical guide for designing and implementing APIs that effectively leverage statelessness and cacheability. These best practices serve as a roadmap to avoid common pitfalls and build resilient systems.
5.1 Design First: Making Conscious Architectural Decisions
The most critical step in determining the right approach is to make conscious design decisions early in the API development lifecycle. Avoid falling into default patterns without critical thought.
- Understand Your API's Purpose: Is it primarily for data retrieval (read-heavy)? Or is it for creating and updating transactional data (write-heavy)? APIs serving frequently accessed, relatively static data are strong candidates for extensive caching. APIs for sensitive, real-time, or transactional operations should prioritize statelessness and minimal caching.
- Identify Data Characteristics: How often does the underlying data change? What is the tolerance for stale data? This directly informs cache duration (
max-age) and invalidation strategies. Highly dynamic data requires very short cache times or no caching, while static reference data can be cached for long periods. - Anticipate Traffic Patterns: Will the API experience bursty traffic? High concurrent requests for the same resources? Caching can absorb these spikes. If traffic is evenly distributed across unique requests, caching might offer less benefit.
- Consider Client Ecosystem: What types of clients will consume the API (web browsers, mobile apps, other microservices)? Their caching capabilities and requirements will influence your design. For example, web browsers heavily rely on HTTP caching headers.
5.2 Profile and Benchmark: Understanding Your API's Behavior
Guesses about performance and traffic are insufficient. Empirically understanding your API's operational profile is essential.
- Load Testing and Stress Testing: Simulate expected (and unexpected) traffic loads to identify bottlenecks in your API. This will reveal which endpoints are under the most pressure and where caching could provide the most relief.
- Performance Monitoring: Continuously monitor your API in production. Track metrics like response times, error rates, and resource utilization. Identify endpoints with consistently high latency or high server load – these are prime candidates for caching optimization.
- Access Pattern Analysis: Analyze API access logs to understand which endpoints are most frequently called, which resources are most popular, and how often the same requests are repeated. This data guides where to apply caching most effectively. For example, if
GET /products/popularis called thousands of times per minute, it's a clear caching target.
5.3 Leverage HTTP Semantics: The Power of Standards
HTTP provides a rich set of mechanisms for both stateless communication and caching. Use them wisely.
- Statelessness: Adhere to RESTful principles. Use appropriate HTTP methods (GET, POST, PUT, DELETE, PATCH). Ensure all necessary information (authentication, resource IDs, parameters) is part of each request.
- Cacheability:
- Always use
Cache-Control: It's the most powerful and flexible caching header. Specifymax-age,public/private/no-store,no-cache, andmust-revalidateas appropriate. - Implement
ETagandLast-Modified: These headers enable conditional requests and 304 Not Modified responses, significantly reducing bandwidth even for uncached requests by allowing clients/proxies to revalidate cached content efficiently. - Use
Varyheader correctly: If your API response depends on request headers likeAccept-Encoding(for compression) orAccept-Language(for localization), explicitly useVaryto tell caches to store different versions. - Handle
If-None-MatchandIf-Modified-Since: Your API backend should be capable of processing these conditional request headers and returning a 304 Not Modified response when appropriate, saving bandwidth.
- Always use
5.4 Layered Architecture: Separation of Concerns
A well-designed API architecture separates concerns, making it easier to manage both stateless services and caching strategies.
- API Gateway as the Front Door: Position an
api gatewayat the edge of your network. It handles centralized concerns like authentication, authorization, rate limiting, and crucially,api gatewaylevel caching. This allows your backend services to remain lean, stateless, and focused on business logic. ApiPark as anapi gatewaycan streamline this process significantly, providing centralized control over these cross-cutting concerns. - Dedicated Caching Layer: For more complex caching needs, introduce a dedicated distributed caching system (e.g., Redis) that your backend services interact with. This keeps the caching logic external to the individual services, allowing them to remain stateless while leveraging a shared, scalable cache.
- Microservices Design: Encourage a microservices architecture where individual services are stateless and loosely coupled. This enhances scalability and maintainability. Each microservice can then decide its own caching strategy for internal data, or rely on external
gatewayor distributed caches for external API calls.
5.5 Thorough Testing: Validate Your Caching Logic
Caching, especially invalidation, is notoriously complex. Rigorous testing is non-negotiable.
- Functional Testing: Ensure that cached responses are correctly served and that original responses are retrieved when the cache expires or is invalidated.
- Cache Invalidation Testing: Crucially, test all scenarios where data changes, verifying that the cache is correctly invalidated and fresh data is served afterward. This includes edge cases, race conditions, and various invalidation triggers.
- Performance Testing: Measure the impact of caching on latency and throughput. Compare performance with and without caching enabled to quantify the benefits.
- Security Testing: Verify that sensitive data is never cached inappropriately and that cache poisoning vulnerabilities are not present.
5.6 Comprehensive Documentation: Clarity for Consumers and Developers
Clear documentation is vital for both API consumers and internal developers.
- API Contract: Document the expected
Cache-Controlheaders for each endpoint. Clearly state which endpoints are cacheable, their typicalmax-age, and anyVaryheaders. - Authentication Requirements: Explain how to provide authentication credentials (e.g., JWT in Authorization header) for your stateless API.
- Usage Guidelines: Provide guidance on when clients should expect cached responses, how to force a refresh (if applicable), and any considerations for handling stale data.
- Internal Playbooks: For internal developers and operations teams, document caching strategies, invalidation mechanisms, and monitoring procedures.
By diligently following these best practices, you can design and implement APIs that successfully balance the principles of statelessness and cacheability. This leads to systems that are not only performant and scalable but also robust, secure, and easier to manage in the long run. The journey from a basic API to a sophisticated, enterprise-grade service is paved with these thoughtful architectural decisions, often supported and enhanced by powerful tools like an api gateway.
Conclusion: Crafting the Optimal API Architecture
The journey through the realms of statelessness and cacheability reveals that these are not merely academic concepts, but rather fundamental architectural choices with profound implications for any API. A stateless design imbues an API with unparalleled scalability, resilience, and simplicity at the server core, making it an ideal foundation for modern distributed systems and microservices architectures. Each request stands on its own, independent and self-contained, simplifying horizontal scaling and enhancing fault tolerance.
Conversely, cacheability is the ultimate performance enhancer, a strategic layer that reduces latency, diminishes server load, and conserves bandwidth by intelligently reusing prior responses. It transforms a reactive system into a proactive one, delivering data to clients with lightning speed. However, this power comes with the formidable challenge of cache invalidation, demanding meticulous design to ensure data freshness and consistency without compromising security.
The critical insight is that these two paradigms are rarely mutually exclusive. In fact, they are often complementary. A well-designed, stateless API forms the most robust and predictable substrate for implementing highly effective caching strategies. By decoupling the core business logic from session management, stateless services become prime candidates for leveraging caching at various levels—from client-side browsers and powerful api gateways to distributed backend caches.
Choosing "which is right" for your API is, therefore, not a binary decision but a contextual one. It hinges on a deep understanding of your API's specific use cases, the dynamic nature of its data, expected traffic patterns, and the tolerance for data staleness. Transactional, sensitive, or highly dynamic data demands strict statelessness with minimal or no caching. In contrast, read-heavy, publicly accessible, or semi-static content thrives on aggressive caching.
Ultimately, the optimal API architecture often emerges from a thoughtful hybrid approach. This involves building a stateless core, complemented by intelligently layered caching mechanisms managed by a sophisticated api gateway. Such a gateway, like ApiPark, becomes an indispensable orchestrator, centrally managing authentication, authorization, rate limiting, and, crucially, both the routing for stateless services and the caching policies that optimize performance. Its ability to provide end-to-end API lifecycle management, high performance, and detailed observability ensures that your API ecosystem remains efficient, secure, and adaptable.
By embracing these principles and utilizing the right tools, developers and architects can forge APIs that are not just functional, but truly scalable, resilient, performant, and future-proof, capable of meeting the ever-growing demands of the digital world.
Frequently Asked Questions (FAQs)
1. What is the fundamental difference between a stateless API and a stateful API?
A stateless API treats each request as an independent transaction, containing all necessary information for the server to process it without relying on any previous server-side context or session. The server processes the request, sends a response, and then "forgets" everything about that interaction. Conversely, a stateful API maintains client-specific session data on the server, meaning subsequent requests can implicitly refer to this established context, reducing the information needed in each request but complicating scalability and fault tolerance.
2. Why is statelessness considered a best practice for modern API design, especially for microservices?
Statelessness is crucial for modern API design due to its direct impact on scalability, reliability, and simplicity. It allows for easy horizontal scaling because any server instance can handle any request, simplifying load balancing and improving resilience to server failures. In microservices, it promotes loose coupling and independent deployment, as individual services don't need to share session state, leading to a more agile and robust distributed system.
3. What are the main benefits of making an API cacheable, and what's the biggest challenge?
The primary benefits of cacheable APIs are dramatically improved performance (lower latency, faster response times), significant reduction in server load, and decreased network bandwidth usage. By serving responses from a cache, redundant computations and data transfers are avoided. The biggest challenge, however, is cache invalidation – ensuring that cached data remains fresh and that stale information is not served when the underlying resource changes. Incorrect cache invalidation can lead to data inconsistency and application errors.
4. How does an API Gateway contribute to managing both stateless and cacheable APIs effectively?
An API Gateway acts as a central control point, offering indispensable functionalities for both. For stateless APIs, it can handle centralized authentication and authorization (e.g., validating JWTs), request routing, and load balancing across backend services, keeping the services themselves lean. For cacheable APIs, many api gateways provide built-in caching capabilities, allowing them to cache responses at the gateway level, reducing traffic to backend services and improving client response times, all while enforcing caching policies centrally.
5. When should I prioritize statelessness over cacheability, and vice versa?
Prioritize statelessness for APIs that handle high-write operations (e.g., creating accounts, placing orders), sensitive or highly personalized data, dynamic and real-time content, or operations with side effects. For these, data freshness and transaction integrity are paramount. Prioritize cacheability for read-heavy APIs with data that changes infrequently (e.g., public product catalogs, news articles), public APIs experiencing high traffic volumes, or static/semi-static content. In many cases, a hybrid approach with a stateless core and intelligent, strategically placed caching layers (especially via an api gateway) offers the best balance.
🚀You can securely and efficiently call the OpenAI API on APIPark in just two steps:
Step 1: Deploy the APIPark AI gateway in 5 minutes.
APIPark is developed based on Golang, offering strong product performance and low development and maintenance costs. You can deploy APIPark with a single command line.
curl -sSO https://download.apipark.com/install/quick-start.sh; bash quick-start.sh

In my experience, you can see the successful deployment interface within 5 to 10 minutes. Then, you can log in to APIPark using your account.

Step 2: Call the OpenAI API.